spark (三) hadoop上传文件并运行spark
1. 上传文件到hdfs
# 前提挂载了 -v ~/bilibili/input_files:/input_files
# hdfs创建input文件夹
docker exec namenode hdfs dfs -mkdir /input
# 将容器内input_files文件夹下的1.txt上传到 hdfs的 /input下
docker exec namenode hdfs dfs -put /input_files/1.txt /input
查看浏览器中是否有指定文件
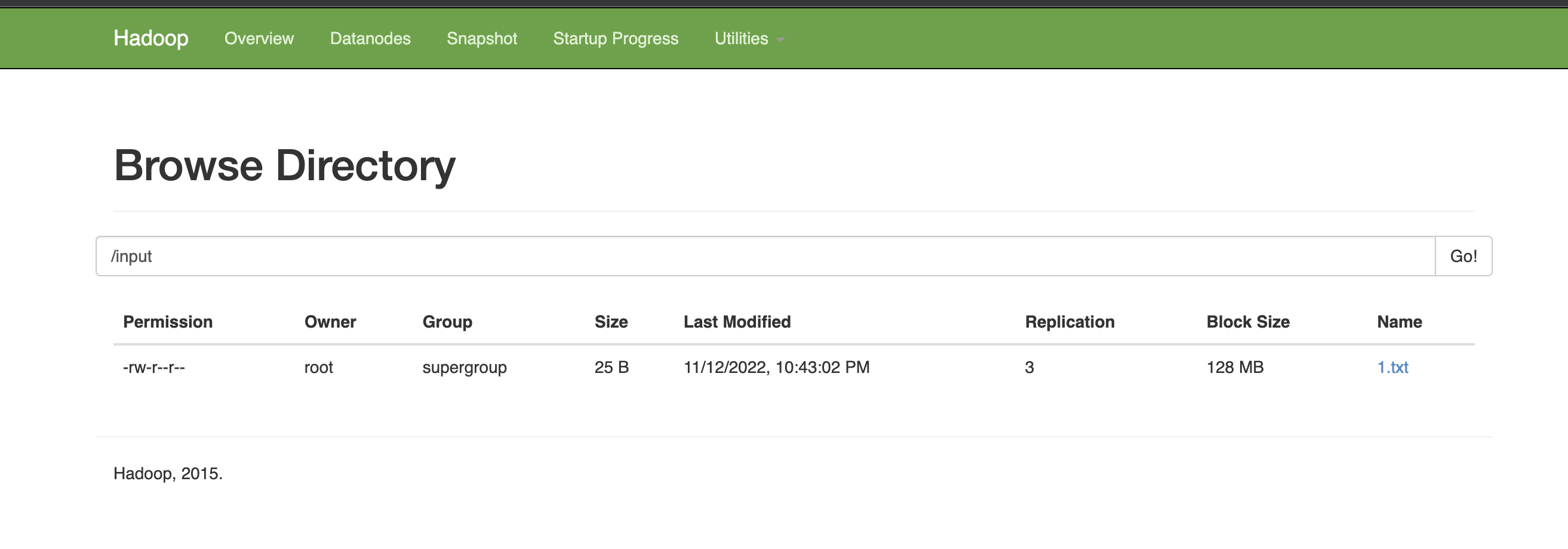
2. 运行wordCount
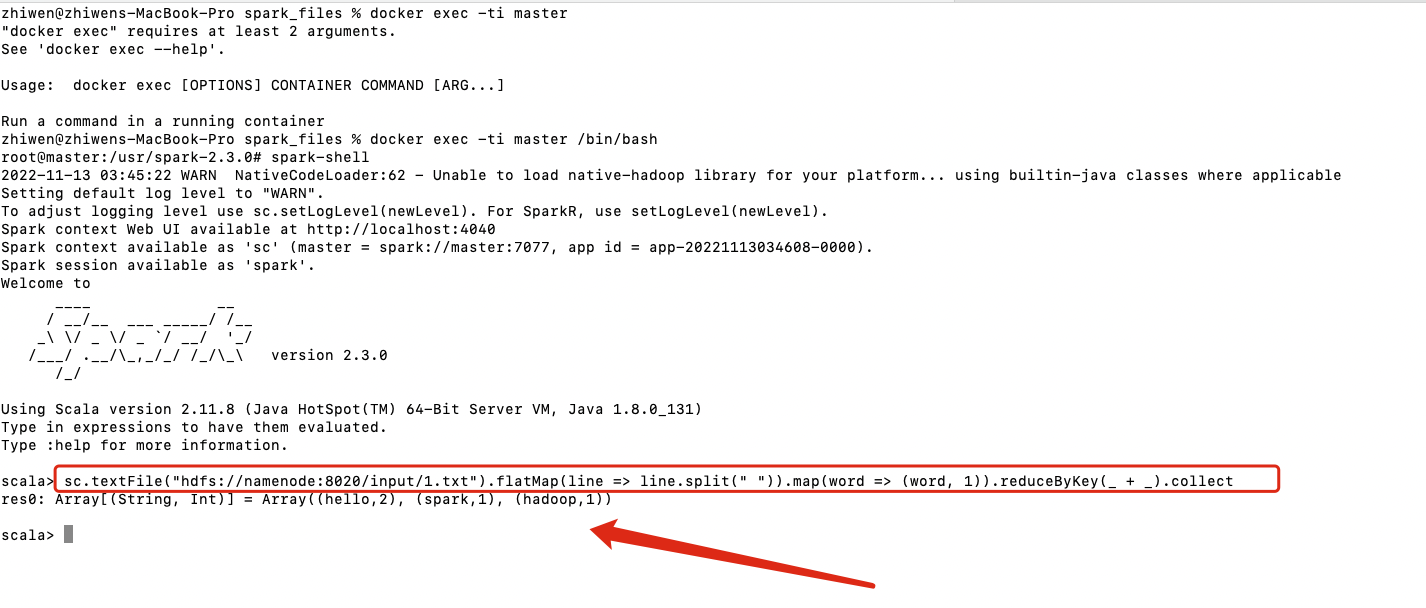
2.1 spark-shell运行
# 进入spark master容器内的spark-shell
docker exec -ti master spark-shell --executor-memory 1024M --total-executor-cores 2
# 执行wordCount
sc.textFile("hdfs://namenode:8020/input/1.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect
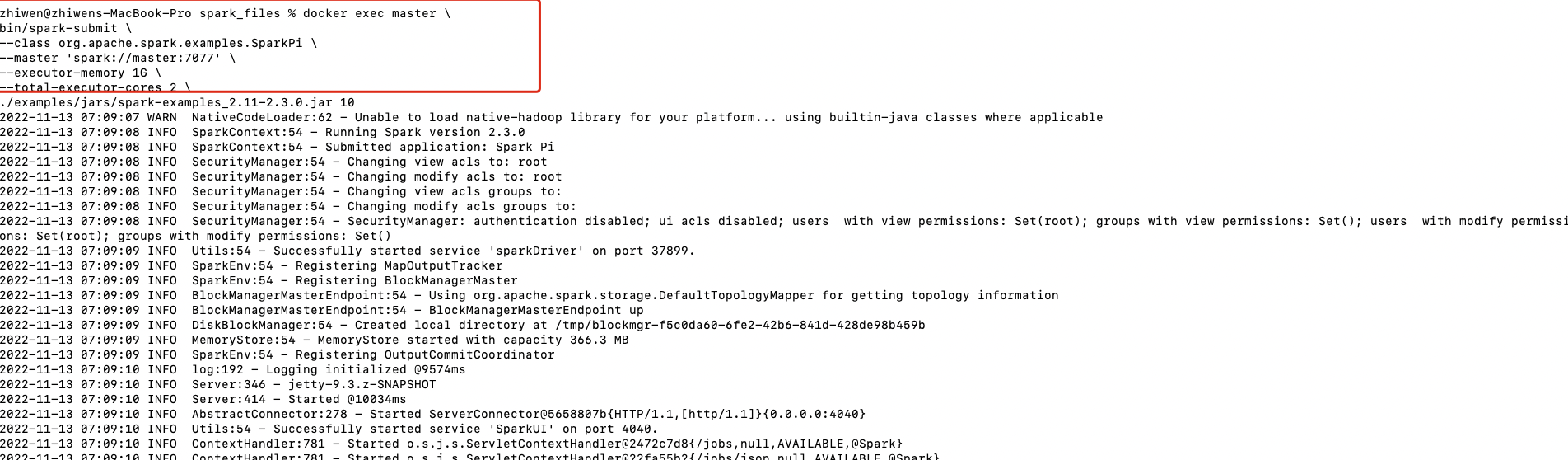
2.2 spark-submit运行example(stand-alone)
这里使用官方默认的example jar运行
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
| 参数 | 解释 | 可选值 |
|---|---|---|
| --class | Spark程序中包含主函数的类 | |
| --master | Spark程序运行的模式(环境) | local[*] spark://master:7077 yarn |
| --executor-memory | 每个executor可用内存为1G | |
| --total-executor-cores | 所有executor使用的cpu核数 | |
| application-jar | 打包好的应用jar, 包含依赖。这个URL在集群中全局可见 | 本地路径的jar包或者hdfs://路径 |
| application-arguements | 传给程序的参数 |
2.3 spark-submit运行example(yarn)
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
2.4 spark-submit运行自定义的jar包(stand-alone)
2.4.1 自定义spark任务
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
println("---------------start word_count----------------")
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
// .setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
println("----------------new SparkContext done---------------")
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val inputPath: String = args(0)
val lines: RDD[String] = ctx.textFile(inputPath)
// val lines: RDD[String] = ctx.textFile("hdfs://namenode:9000/input")
println("----------------ctx.textFile done---------------")
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// 相同的key会对value做reduce
val tuple: RDD[(String, Int)] = wordToOne.reduceByKey((t1, t2) => t1 + t2)
val coll: Array[(String, Int)] = tuple.collect()
coll.foreach(println)
println(s"""----------------tuple.foreach(println) done len ${coll.length}---------------""")
// 3. 关闭连接
ctx.stop()
println("----------------ctx.stop() done---------------")
}
}
2.4.2 生成jar包
2.4.3 复制到挂载的jars文件夹内
2.4.4 运行spark-submit
docker exec master \
bin/spark-submit \
--class com.lzw.bigdata.spark.core.wordcount.Spark03_WordCount \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
/jars/spark_core.jar \
'hdfs://namenode:9000/input'
spark (三) hadoop上传文件并运行spark的更多相关文章
- hadoop上传文件失败解决办法
hadoop上传文件到web端hdfs显示hadoop could only be replicated to 0 nodes instead of 1解决办法 错误状态:在hadoop-2.7.2目 ...
- 【大数据系列】hadoop上传文件报错_COPYING_ could only be replicated to 0 nodes
使用hadoop上传文件 hdfs dfs -put XXX 17/12/08 17:00:39 WARN hdfs.DFSClient: DataStreamer Exception org.ap ...
- 三种上传文件不刷新页面的方法讨论:iframe/FormData/FileReader
发请求有两种方式,一种是用ajax,另一种是用form提交,默认的form提交如果不做处理的话,会使页面重定向.以一个简单的demo做说明: html如下所示,请求的路径action为"up ...
- 三 : spring-uploadify上传文件
一 : applicationContext.xml中:必须声明不然获取不到<!-- 上传文件的配置 --> <bean id="multipartResolver&quo ...
- Hadoop上传文件时报错: could only be replicated to 0 nodes instead of minReplication (=1)....
问题 上传文件到Hadoop异常,报错信息如下: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /home/inpu ...
- hadoop上传文件报错
19/06/06 16:09:26 INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Bad ...
- Hadoop上传文件的报错
baidu了很多,都说防火墙,datanode没有正常启动的问题,可是检查了都是正常,后来还是在老外的网站上找到了解决的方法 修改了/etc/security/limits.conf文件,上传成功 这 ...
- hadoop上传文件失败报错(put: Cannot create file/eclipse.desktop._COPYING_. Name node is in safe mode.)
解决办法: 离开安全模式方法:执行以下命令即可 bin/hadoop dfsadmin -safemode leave 若不处理安全模式的话,web服务无法启动,dfsadmin report结果异 ...
- C#远程执行Linux系统中Shell命令和SFTP上传文件
一.工具:SSH.Net 网址:https://github.com/sshnet/SSH.NET 二.调用命令代码: Renci.SshNet.SshClient ssh = "); ss ...
- CentOS7中利用Xshell6向虚拟机本地上传文件
环境交代 Linux系统:CentOS7, Xshell版本:6 操作步骤 下面我们以一个文件上传来演示用法 第一步 建立连接,这里不多说 在Xshell中点击如下图标,或者直接按 Alt+Ctrl+ ...
随机推荐
- Chrome使用回退,出现表单提交失败,ERR_CACHE_MISS问题
是什么.为什么.怎么办 "ERR_CACHE_MISS" 错误通常发生在你使用浏览器的"返回"按钮时.这种错误与浏览器处理缓存数据的方式有关,特别是在处理表单和 ...
- MISC 高手进阶区 1-5
1.reverseME 题目描述 无 附件 一个 .jpg 的图片 是一个flag字符串的图片镜像. reverse V-T If you reverse the order of a set of ...
- KNN算法:近朱者赤,近墨者黑
文章目录 1.一个例子 2.算法原理 3.算法的优缺点 3.关于 K 的选取 4.代码实现 今天我要讲的这个算法是最近邻算法(K-NearestNeighbor),简称 KNN 算法. 1.一个例子 ...
- ESP8266 + SN74HC595N(8位移位寄存器)
目录 目录 介绍 准备 连线 代码 代码优化 运行 问题 总结 介绍 使用SN74HC595N 为 ESP8266 扩展 SN74HC595N(8位移位寄存器IC) 1. Vcc 16引脚 电压输入 ...
- C# 单例模式的多种实现
单例模式介绍 单例模式是一种创建型设计模式,它主要确保在一个类只有一个实例,并提供一个全局访问点来获取该实例.在C#中,有多种方式实现单例模式,每种方式都有其特定的使用场景和注意事项. 设计模式的作用 ...
- C++ 函数模板与类模板
目录 16.1.1 函数模板 16.1.2 类模板 定义类模板 实例化模板 在类外定义成员函数 类模板成员函数的实例化 类模板和友元 模板类型别名 类模板参数的static成员 16.1.3 模板参数 ...
- PC大屏自适应
通常来说PC端的页面并不像移动端页面那样对屏幕大小和分别率有那么强的依赖.一般的页面都是取屏幕中间的一块宽度(1280px), 两边留白, 高度随着内容的长度滚动.这样无论窗口怎么变化,页面都是可用的 ...
- 使用expected_conditions的url_changes方法判断是否登录成功
使用expected_conditions的url_changes方法判断是否跳转页面登录成功 from selenium import webdriver from selenium.webdriv ...
- 谷歌chrome浏览器大量书签消失,怎么恢复历史?
作者:jdjdjdh链接:https://www.zhihu.com/question/400424237/answer/1604383205来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非 ...
- 深入JUnit源码之Runner
初次用文字的方式记录读源码的过程,不知道怎么写,感觉有点贴代码的嫌疑.不过中间还是加入了一些自己的理解和心得,希望以后能够慢慢的改进,感兴趣的童鞋凑合着看吧,感觉JUnit这个框架还是值得看的,里面有 ...