spark (三) hadoop上传文件并运行spark
1. 上传文件到hdfs
# 前提挂载了 -v ~/bilibili/input_files:/input_files
# hdfs创建input文件夹
docker exec namenode hdfs dfs -mkdir /input
# 将容器内input_files文件夹下的1.txt上传到 hdfs的 /input下
docker exec namenode hdfs dfs -put /input_files/1.txt /input
查看浏览器中是否有指定文件
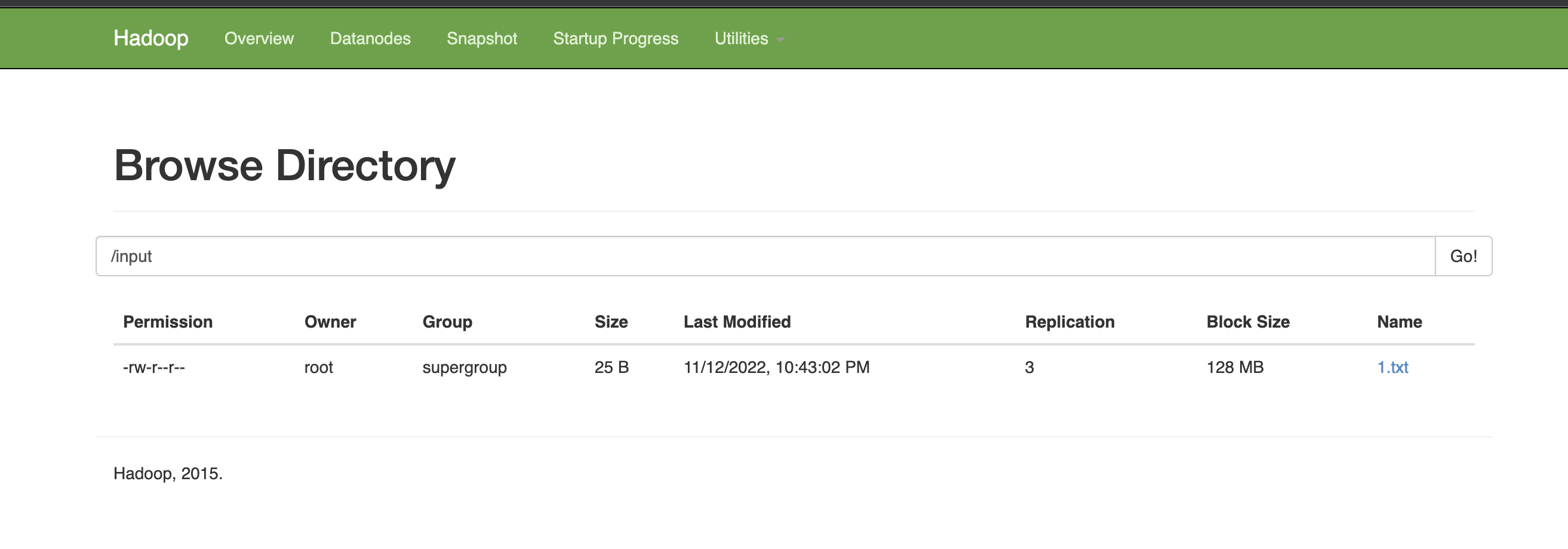
2. 运行wordCount
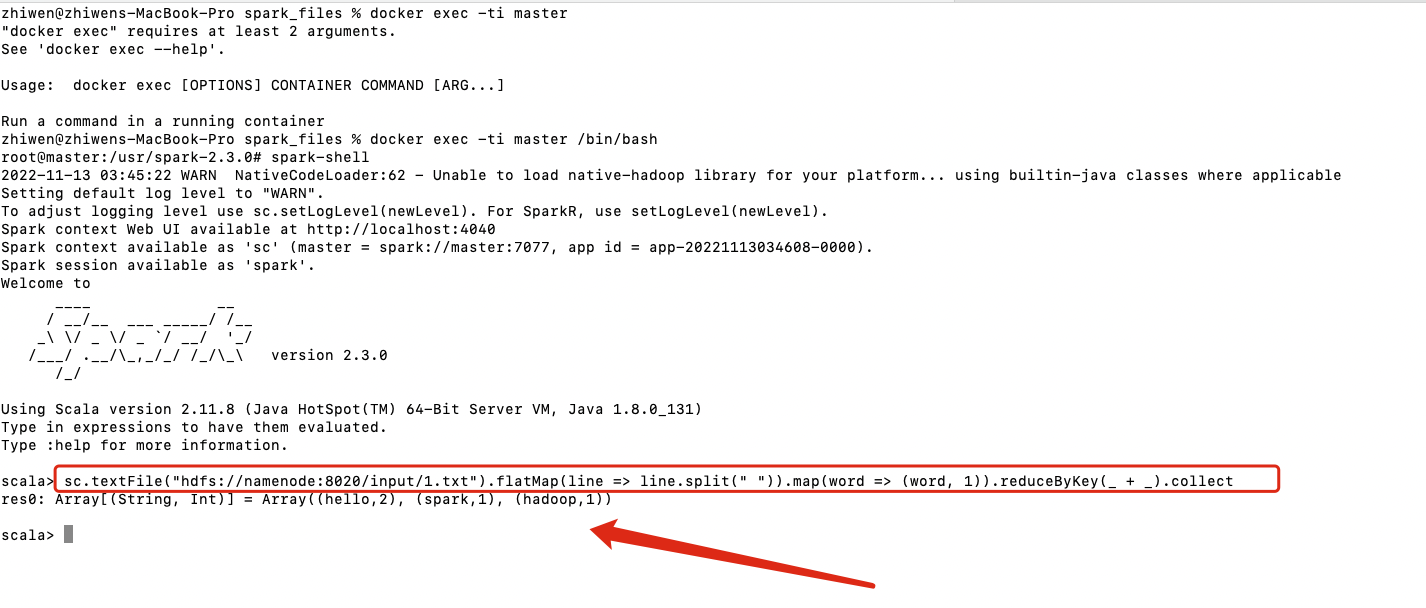
2.1 spark-shell运行
# 进入spark master容器内的spark-shell
docker exec -ti master spark-shell --executor-memory 1024M --total-executor-cores 2
# 执行wordCount
sc.textFile("hdfs://namenode:8020/input/1.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect
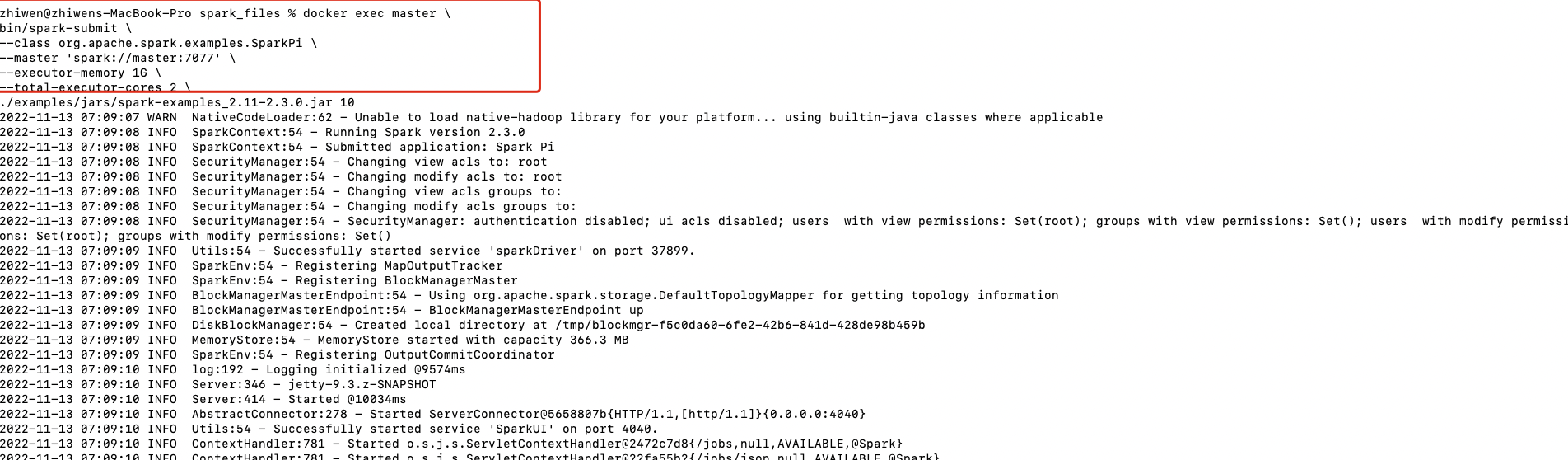
2.2 spark-submit运行example(stand-alone)
这里使用官方默认的example jar运行
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
| 参数 | 解释 | 可选值 |
|---|---|---|
| --class | Spark程序中包含主函数的类 | |
| --master | Spark程序运行的模式(环境) | local[*] spark://master:7077 yarn |
| --executor-memory | 每个executor可用内存为1G | |
| --total-executor-cores | 所有executor使用的cpu核数 | |
| application-jar | 打包好的应用jar, 包含依赖。这个URL在集群中全局可见 | 本地路径的jar包或者hdfs://路径 |
| application-arguements | 传给程序的参数 |
2.3 spark-submit运行example(yarn)
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
2.4 spark-submit运行自定义的jar包(stand-alone)
2.4.1 自定义spark任务
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
println("---------------start word_count----------------")
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
// .setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
println("----------------new SparkContext done---------------")
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val inputPath: String = args(0)
val lines: RDD[String] = ctx.textFile(inputPath)
// val lines: RDD[String] = ctx.textFile("hdfs://namenode:9000/input")
println("----------------ctx.textFile done---------------")
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// 相同的key会对value做reduce
val tuple: RDD[(String, Int)] = wordToOne.reduceByKey((t1, t2) => t1 + t2)
val coll: Array[(String, Int)] = tuple.collect()
coll.foreach(println)
println(s"""----------------tuple.foreach(println) done len ${coll.length}---------------""")
// 3. 关闭连接
ctx.stop()
println("----------------ctx.stop() done---------------")
}
}
2.4.2 生成jar包
2.4.3 复制到挂载的jars文件夹内
2.4.4 运行spark-submit
docker exec master \
bin/spark-submit \
--class com.lzw.bigdata.spark.core.wordcount.Spark03_WordCount \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
/jars/spark_core.jar \
'hdfs://namenode:9000/input'
spark (三) hadoop上传文件并运行spark的更多相关文章
- hadoop上传文件失败解决办法
hadoop上传文件到web端hdfs显示hadoop could only be replicated to 0 nodes instead of 1解决办法 错误状态:在hadoop-2.7.2目 ...
- 【大数据系列】hadoop上传文件报错_COPYING_ could only be replicated to 0 nodes
使用hadoop上传文件 hdfs dfs -put XXX 17/12/08 17:00:39 WARN hdfs.DFSClient: DataStreamer Exception org.ap ...
- 三种上传文件不刷新页面的方法讨论:iframe/FormData/FileReader
发请求有两种方式,一种是用ajax,另一种是用form提交,默认的form提交如果不做处理的话,会使页面重定向.以一个简单的demo做说明: html如下所示,请求的路径action为"up ...
- 三 : spring-uploadify上传文件
一 : applicationContext.xml中:必须声明不然获取不到<!-- 上传文件的配置 --> <bean id="multipartResolver&quo ...
- Hadoop上传文件时报错: could only be replicated to 0 nodes instead of minReplication (=1)....
问题 上传文件到Hadoop异常,报错信息如下: org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /home/inpu ...
- hadoop上传文件报错
19/06/06 16:09:26 INFO hdfs.DFSClient: Exception in createBlockOutputStream java.io.IOException: Bad ...
- Hadoop上传文件的报错
baidu了很多,都说防火墙,datanode没有正常启动的问题,可是检查了都是正常,后来还是在老外的网站上找到了解决的方法 修改了/etc/security/limits.conf文件,上传成功 这 ...
- hadoop上传文件失败报错(put: Cannot create file/eclipse.desktop._COPYING_. Name node is in safe mode.)
解决办法: 离开安全模式方法:执行以下命令即可 bin/hadoop dfsadmin -safemode leave 若不处理安全模式的话,web服务无法启动,dfsadmin report结果异 ...
- C#远程执行Linux系统中Shell命令和SFTP上传文件
一.工具:SSH.Net 网址:https://github.com/sshnet/SSH.NET 二.调用命令代码: Renci.SshNet.SshClient ssh = "); ss ...
- CentOS7中利用Xshell6向虚拟机本地上传文件
环境交代 Linux系统:CentOS7, Xshell版本:6 操作步骤 下面我们以一个文件上传来演示用法 第一步 建立连接,这里不多说 在Xshell中点击如下图标,或者直接按 Alt+Ctrl+ ...
随机推荐
- Mysql导出文本文件
使用mysqldump命令导出文本文件 mysqldump -u root -pPassword -T 目标目录 dbname [tables] [option]; 其中: Password 参数表示 ...
- Next.js 与 React 全栈开发:整合 TypeScript、Redux 和 Ant Design
在上一集,我们编写完毕导航页面,并且非常的美观,但是我们发现编写网站是存静态的,在现代的网站当中一般都是动静结合,也就是说部分数据是从数据库读取的,部分静态数据是写在网页上面的,因此这章讲述如何搭建一 ...
- 你还用ES存请求日志?ClickHouse+Vector打造最强Grafana日志分析看板
为什么要做NGINX日志分析看板 Grafana官网的dashboards有NGINX日志采集到ES数据源的展示看板,也有采集到LOKI数据源的展示看板,唯独没有采集到ClickHouse数据源的展示 ...
- Linux Shell综合:备份数据库
需求分析 每天凌晨2:30备份数据库hspedu到/data/backup/db 备份开始和备份结束能够给出相应的提示信息 备份后的文件要求以备份时间为文件名,并打包成.tar.gz的形式,比如:20 ...
- Git Flow开发分支管理
Git Flow Git Flow 是一种基于 Git 版本控制系统的分支管理模型,定义了一套严格的分支命名和操作规范 主要包括以下几种分支类型: 主干分支(master):始终保持稳定,只包含经过充 ...
- Python 提取PowerPoint文档中的图片
如果你需要在多个PowerPoint演示文稿中使用相同的图片,直接从原始PPT中提取并保存图片可以避免重复寻找和下载.此外,将PPT中的重要图片提取出来可以将其作为备份,以防原文件损坏或丢失.本文将通 ...
- vivo 企业云盘服务端实现简介
作者:来自 vivo 互联网存储团队- Cheng Zhi 本文将介绍企业云盘的基本功能以及服务端实现. 一.背景 vivo 企业云盘是一个企业级文件数据管理服务,解决办公数据的存储.共享.审计等文件 ...
- PHP开源项目之YOURLS
YOURLS是一个开源的PHP的程序,可以利用它来构建属于自己的URL缩短服务,YOURLS还可以集成到WordPress博客中使用. YOURLS 的主要功能: 公开的(Public 任何人都可以用 ...
- getent使用小结
转载请注明出处: getent 是一个用于访问系统数据库的命令,通常用于获取与网络有关的信息,比如用户.组.主机名.服务等.这个命令是 Linux 和 Unix 系统中非常有用的工具,可以用来查询多种 ...
- Web API 控制器的行为和操作方法的属性
ControllerBase 类 Web API 包含一个或多个派生自 ControllerBase 的控制器类. Web API 项目模板提供了一个入门版控制器 [ApiController] [R ...