pandas速成笔记(3)-join/groupby/sort/行列转换
接上篇继续 ,这回看下一些常用的操作:
一、join 联表查询
有数据库开发经验的同学,一定对sql中的join ... on 联表查询不陌生,pandas也有类似操作
假设test.xlsx的sheet1, sheet2中分别有下面的数据(相当于2张表)
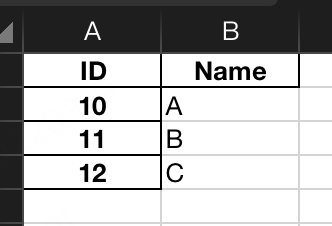
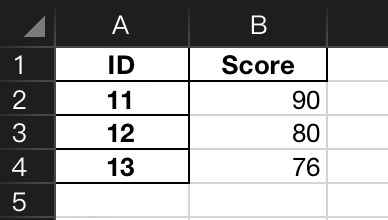
现在要以ID做为作为Key,将二张表join起来,可以这样写:
import pandas as pd
pd1 = pd.read_excel("./data/test.xlsx", sheet_name="sheet1", index_col="ID")
pd2 = pd.read_excel("./data/test.xlsx", sheet_name="sheet2", index_col="ID")
print("-----pd1--------")
print(pd1)
print("\n-----pd2--------")
print(pd2)
print("\n------default-------")
pd3 = pd1.join(pd2)
print(pd3)
print("\n------left-------")
pd3 = pd1.join(pd2, how="left")
print(pd3)
print("\n------right-------")
pd3 = pd1.join(pd2, how="right")
print(pd3)
print("\n------inner-------")
pd3 = pd1.join(pd2, how="inner")
print(pd3)
print("\n------outer-------")
pd3 = pd1.join(pd2, how="outer")
print(pd3)
输出:
-----pd1--------
Name
ID
10 A
11 B
12 C -----pd2--------
Score
ID
11 90
12 80
13 76 ------default-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0 ------left-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0 ------right-------
Name Score
ID
11 B 90
12 C 80
13 NaN 76 ------inner-------
Name Score
ID
11 B 90
12 C 80 ------outer-------
Name Score
ID
10 A NaN
11 B 90.0
12 C 80.0
13 NaN 76.0
是不是跟sql几乎一模一样?如果2个表格中的Key,名称不一样,比如第2个表格长这样,第1列不叫ID,而是stutent_id
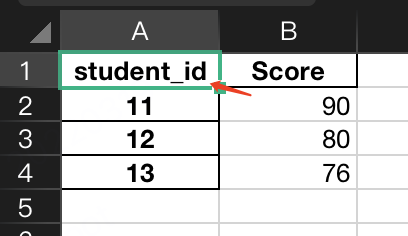
也不影响,只要在读取时设置了索引即可,默认join时就是用index列做为key关联
二、groupby分组统计
假设有一张表:
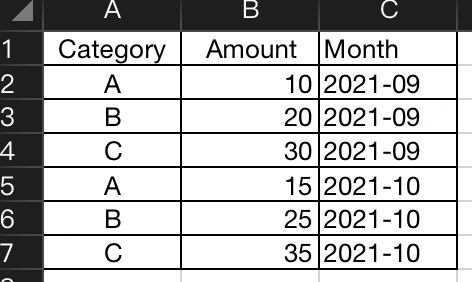
想按月汇总下Amount的总和,直接使用groupby("Month")
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
df_month = df.groupby("Month").sum()
print(df_month)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Month
2021-09 60
2021-10 75
来个更复杂的,希望按Category看看,在本月当中该Category的Amount占"当月Amount总和"的占比,比如2021-09月,Amount总和为60,而9月之中,C类的Amount=30,即9月C类的Amount占9月总Amount的50%
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
df_month = df.groupby("Month").sum()
print(df_month)
print("------------")
# 插入2列
df.insert(2, 'MonthTotal', 0)
df.insert(3, 'MonthPercent', 0.0)
# 计算每个月,各Category的Amount占比
for idx2, data2 in df_month.iterrows():
for idx, data in df.iterrows():
if idx2 == data["Month"]:
data["MonthTotal"] = data2["Amount"]
data["MonthPercent"] = data["Amount"] / data2["Amount"]
df.iloc[idx] = pd.Series(data)
df["MonthPercent"] = df["MonthPercent"].apply(lambda x: format(x, '.2%'))
print(df)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Month
2021-09 60
2021-10 75
------------
Category Amount MonthTotal MonthPercent Month
0 A 10 60 16.67% 2021-09
1 B 20 60 33.33% 2021-09
2 C 30 60 50.00% 2021-09
3 A 15 75 20.00% 2021-10
4 B 25 75 33.33% 2021-10
5 C 35 75 46.67% 2021-10
除了分组求和,当然还能求平均值,以及分组计算count
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print(df)
print("------------")
category_amount_avg = df.groupby("Category").mean()
print(category_amount_avg)
print("------------")
category_count = df.groupby("Month").count()
print(category_count)
输出:
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
------------
Amount
Category
A 12.5
B 22.5
C 32.5
------------
Category Amount
Month
2021-09 3 3
2021-10 3 3
三、sort排序
还是这张表,如果希望按Amount降序排列,可以这样:
import pandas as pd
df = pd.read_excel("./data/test.xlsx")
print("-----before sort------")
print(df)
print("-----after sort------")
df.sort_values("Amount", inplace=True, ascending=False)
print(df)
输出:
-----before sort------
Category Amount Month
0 A 10 2021-09
1 B 20 2021-09
2 C 30 2021-09
3 A 15 2021-10
4 B 25 2021-10
5 C 35 2021-10
-----after sort------
Category Amount Month
5 C 35 2021-10
2 C 30 2021-09
4 B 25 2021-10
1 B 20 2021-09
3 A 15 2021-10
0 A 10 2021-09
如果需要多个字段排序 ,比如:先按Month升序,再按Amount降序
print("-----after sort------")
df.sort_values(by=["Month", "Amount"], ascending=[True, False], inplace=True)
print(df)
输出:
-----after sort------
Category Amount Month
2 C 30 2021-09
1 B 20 2021-09
0 A 10 2021-09
5 C 35 2021-10
4 B 25 2021-10
3 A 15 2021-10
四、行列转换
pandas有一个内置的transpose()方法,可以直接实现:
import pandas as pd
df = pd.read_excel("./data/test.xlsx", index_col="Category")
print("------行转列(前)----------")
print(df)
print("------行转列(后)----------")
print(df.transpose())
输出:
------行转列(前)----------
Amount Month
Category
A 10 2021-09
B 20 2021-09
C 30 2021-09
A 15 2021-10
B 25 2021-10
C 35 2021-10
------行转列(后)----------
Category A B C A B C
Amount 10 20 30 15 25 35
Month 2021-09 2021-09 2021-09 2021-10 2021-10 2021-10
不过这个转换功能有点简单,如果要实现一些个性化的行列转换,比如希望达到下面的效果:
2021-09 2021-10
Category
A 10 15
B 20 25
C 30 35
就得自己写代码了,参考下面:
import pandas as pd
import matplotlib.pyplot as plt df = pd.read_excel("./data/test.xlsx") print("-------before-------")
df.set_index("Month", inplace=True)
print(df) print("-------after-------")
# 先对Month求distinct
months = df.index.unique()
rows = []
for month in months:
# 遍历df
for idx, data in df.iterrows():
if idx == month:
# 生成新DataFrame中的每一行
row = pd.Series({"Category": data.Category, month: data.Amount})
found = 0
for d in rows:
# 如果该分类的行存在,则填充缺的月份列
if d.Category == data.Category:
found = 1
d[month] = data.Amount # 如果该分类的行不存在,直接放入rows数列
if found == 0:
rows.append(row) # 构造新的DataFrame
df_output = pd.DataFrame(rows)
df_output.set_index("Category", inplace=True) print(df_output)
参考:
1、官网 pandas.DataFrame.join 文档
2、官网 pandas.DataFrame.groupby 文档
pandas速成笔记(3)-join/groupby/sort/行列转换的更多相关文章
- 【转】Pandas学习笔记(五)合并 concat
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(一)基本介绍
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- Oracle 表的连接方式(1)-----Nested loop join和 Sort merge join
关系数据库技术的精髓就是通过关系表进行规范化的数据存储,并通过各种表连接技术和各种类型的索引技术来进行信息的检索和处理. 表的三种关联方式: nested loop:从A表抽一条记录,遍历B表查找匹配 ...
- Pandas 学习笔记
Pandas 学习笔记 pandas 由两部份组成,分别是 Series 和 DataFrame. Series 可以理解为"一维数组.列表.字典" DataFrame 可以理解为 ...
- Nested Loops,Hash Join 和 Sort Merge Join. 三种不同连接的不同:
原文:https://blog.csdn.net/tianlesoftware/article/details/5826546 Nested Loops,Hash Join 和 Sort Merge ...
- 三大表连接方式详解之Nested loop join和 Sort merge join
在早期版本,Oracle提供的是nested-loop join,两表连接就相当于二重循环,假定两表分别有m行和n行 如果内循环是全表扫描,时间复杂度就是O(m*n) 如果内循 ...
- 【转】Pandas学习笔记(七)plot画图
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(六)合并 merge
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(四)处理丢失值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
- 【转】Pandas学习笔记(三)修改&添加值
Pandas学习笔记系列: Pandas学习笔记(一)基本介绍 Pandas学习笔记(二)选择数据 Pandas学习笔记(三)修改&添加值 Pandas学习笔记(四)处理丢失值 Pandas学 ...
随机推荐
- 在Podman中配置Dify Sandbox服务与外部PostgreSQL服务的网络连接
在Podman中配置Dify Sandbox服务与外部PostgreSQL服务的网络连接 引言 在容器化环境中,确保不同服务之间的可靠通信是至关重要的.本文将指导你如何使用Podman来配置Dify ...
- 关于The JSON value could not be converted to System.DateTime的解决方案
如下json格式提交到后台后报: The JSON value could not be converted to System.DateTime. Path: $.beginTime | LineN ...
- 乌班图20.04上安装java配置tomcat9
原文参考:https://blog.csdn.net/u010763324/article/details/122678528 Apache Tomcat是一个开源的 Web 服务器和 Java se ...
- windows环境下的常用命令
1.appwiz.cpl 程序和功能 2.certmgr.msc 证书管理实用程序 3.control 控制面板 4.firewall.cpl 防火墙 5.fsmgmt.msc 共享文件夹管理器 6. ...
- MySQL-Canal-Kafka数据复制详解
摘要 MySQL被广泛用于海量业务的存储数据库,在大数据时代,我们亟需对其中的海量数据进行分析,但在MySQL之上进行大数据分析显然是不现实的,这会影响业务系统的运行稳定.如果我们要实时地分析这些数据 ...
- vue模板语法中能否用??的三目运算简写的问题
使用双问号(??)的三目运算可以在 JavaScript 中使用,但在 Vue 模板语法中不支持.Vue 模板语法中的三目运算仍然使用单个问号(?)和冒号(:)的标准形式.例如: {{ conditi ...
- 做思维导图?chatmoney轻轻松松拿下
本文由 ChatMoney团队出品 嘿,各位职场朋友们 是不是常常对着密密麻麻的笔记感到焦虑呢? 想整理却无从下手? 别怕,ChatmoneyAI知识库来拯救你的整理困难症啦! 咱们都知道,思维导图是 ...
- 又TM遇到傻B了
一想到自己的收藏还有可能被傻逼用到,我TM更蛋疼了...傻逼千千万
- 【运维必看】雷池社区版自动 SSL:从申请到部署全自动化,让证书续期从此 “无感”!
雷池社区版自动SSL 作者:夜猫(社区9群) 正常安装雷池,并配置站点,暂时不配置ssl 不使用雷池自带的证书申请. 安装(acme.sh),使用域名验证方式生成证书 先安装gityum instal ...
- Claude Code 初体验 - Windows
1. 前言 Cursor 和 Claude Code 都是编程神器,它们的主要区别是什么呢? Cursor 主要对不同的AI模型进行整合,提供友好的代码编辑体验,包括OpenAI 的 GPT 系列.G ...