CUDA C编程权威指南:2.2-给核函数计时
本文主要通过例子介绍了如何给核函数计时的思路和实现。实现例子代码参考文献[7],只需要把相应章节对应的CMakeLists.txt文件拷贝到CMake项目根目录下面即可运行。
1.用CPU计时器计时(sumArraysOnGPU-timer.cu)[7]
在主函数中用CPU计时器测试向量加法的核函数,如下所示:
#include <cuda_runtime.h> // 包含cuda运行时系统的头文件
#include <stdio.h> // 包含标准输入输出函数的头文件
#include <time.h> // 包含时间函数的头文件
#include <sys/timeb.h> // 包含时间函数的头文件
//#define CHECK(call) // 定义CHECK宏函数
void initialData(float *ip, int size)
{
// 为随机数生成不同的种子
time_t t; // time_t是一种时间类型
srand((unsigned int) time(&t)); // time()函数返回当前时间的秒数
for (int i = 0; i < size; i++) // 生成随机数
{
ip[i] = (float) (rand() & 0xFF) / 10.0f; // rand()函数用于生成随机数
}
}
void checkResult(float *hostRef, float *gpuRef, const int N) // 检查结果
{
double epsilon = 1.0E-8; // 定义误差范围
bool match = 1; // 定义匹配标志
for (int i = 0; i < N; i++) // 比较每个元素
{
if (abs(hostRef[i] - gpuRef[i]) > epsilon) // 如果误差超过范围
{
match = 0; // 匹配标志置0
printf("Arrays do not match!\n"); // 打印提示信息
printf("host %5.2f gpu %5.2f at current %d\n", hostRef[i], gpuRef[i], i); // 打印不匹配的元素
break;
}
}
if (match) printf("Arrays match.\n\n"); // 如果匹配,打印提示信息
}
void sumArraysOnHost(float *A, float *B, float *C, const int N) // 在主机上计算
{
for (int idx = 0; idx < N; idx++) // 计算每个元素
{
C[idx] = A[idx] + B[idx]; // 计算
}
}
__global__ void sumArraysOnGPU(float *A, float *B, float *C) // 在设备上计算
{
// int i = threadIdx.x; // 获取线程索引
int i = blockIdx.x * blockDim.x + threadIdx.x; // 获取线程索引
// printf("threadIdx.x: %d, blockIdx.x: %d, blockDim.x: %d\n", threadIdx.x, blockIdx.x, blockDim.x); // 打印线程索引
C[i] = A[i] + B[i]; // 计算
}
struct timeval { // 定义timeval结构体
long tv_sec; // 秒
long tv_usec; // 微秒
};
int gettimeofday(struct timeval *tp, void *tzp) { // 定义gettimeofday函数
struct _timeb timebuffer; // 定义_timeb结构体
_ftime(&timebuffer); // 获取当前时间
tp->tv_sec = static_cast<long>(timebuffer.time); // 转换为秒
tp->tv_usec = timebuffer.millitm * 1000; // 转换为微秒
return 0; // 返回0
}
double cpuSecond() { // 定义cpuSecond函数
struct timeval tp; // 定义timeval结构体
gettimeofday(&tp, NULL); // 获取当前时间
return ((double) tp.tv_sec + (double) tp.tv_usec * 1.e-6); // 返回当前时间
}
int main(int argc, char** argv) {
printf("%s Starting...\n", argv[0]); // 打印提示信息
// 设置device
int dev = 0; // 定义device
cudaDeviceProp deviceProp; // 定义deviceProp结构体
// CHECK(cudaGetDeviceProperties(&deviceProp, dev)); // 获取deviceProp结构体
cudaGetDeviceProperties(&deviceProp, dev); // 获取deviceProp结构体
printf("Using Device %d: %s\n", dev, deviceProp.name);
// CHECK(cudaSetDevice(dev)); // 设置device
cudaSetDevice(dev); // 设置device
// 设置vector数据大小
int nElem = 1 << 24; // 定义vector大小,左移24位相当于乘以2的24次方
printf("Vector size %d\n", nElem); // 打印vector大小
// 分配主机内存
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *hostRef, *gpuRef; // 定义主机内存指针
h_A = (float *) malloc(nBytes); // 分配主机内存
h_B = (float *) malloc(nBytes); // 分配主机内存
hostRef = (float *) malloc(nBytes); // 分配主机内存,用于存储host端计算结果
gpuRef = (float *) malloc(nBytes); // 分配主机内存,用于存储device端计算结果
// 定义计时器
double iStart, iElaps;
// 初始化主机数据
iStart = cpuSecond(); // 记录开始时间
initialData(h_A, nElem); // 初始化数据
initialData(h_B, nElem); // 初始化数据
iElaps = cpuSecond() - iStart; // 记录结束时间
memset(hostRef, 0, nBytes); // 将hostRef清零
memset(gpuRef, 0, nBytes); // 将gpuRef清零
// 在主机做向量加法
iStart = cpuSecond(); // 记录开始时间
sumArraysOnHost(h_A, h_B, hostRef, nElem); // 在主机上计算
iElaps = cpuSecond() - iStart; // 记录结束时间
printf("sumArraysOnHost Time elapsed %f sec\n", iElaps); // 打印执行时间
// 分配设备全局内存
float *d_A, *d_B, *d_C;
cudaMalloc((float **) &d_A, nBytes);
cudaMalloc((float **) &d_B, nBytes);
cudaMalloc((float **) &d_C, nBytes);
// 拷贝数据到设备
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
// 在设备端调用kernel
int iLen = 1024;
dim3 block(iLen);
dim3 grid((nElem + block.x - 1) / block.x);
iStart = cpuSecond(); // 记录开始时间
sumArraysOnGPU<<<grid, block>>>(d_A, d_B, d_C); // 调用kernel
cudaDeviceSynchronize(); // 同步device
iElaps = cpuSecond() - iStart; // 记录结束时间
printf("sumArraysOnGPU <<<%d, %d>>> Time elapsed %f sec\n", grid.x, block.x, iElaps); // 打印执行时间
// 拷贝结果到主机
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
// 检查结果
checkResult(hostRef, gpuRef, nElem);
// 释放设备内存
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// 释放主机内存
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
return 0;
}
输出结果,如下所示:
Using Device 0: NVIDIA GeForce RTX 3090
Vector size 16777216
sumArraysOnHost Time elapsed 0.059000 sec
sumArraysOnGPU <<<16384, 1024>>> Time elapsed 0.001000 sec
Arrays match.
2.用nvprof工具计时(已过时)
nvprof命令行工具可以从应用程序的CPU和GPU活动中获取时间线信息,包括内核执行、内存传输以及CUDA API的调用。使用语法如下所示:
$ nvprof [nvprof_args] <application> [application_args]
$ nvprof --help
$ nvprof ./sumArraysOnGPU-timer
遇到这个错误,将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v11.8\extras\CUPTI\lib64添加到Path环境变量中即可,如下所示:


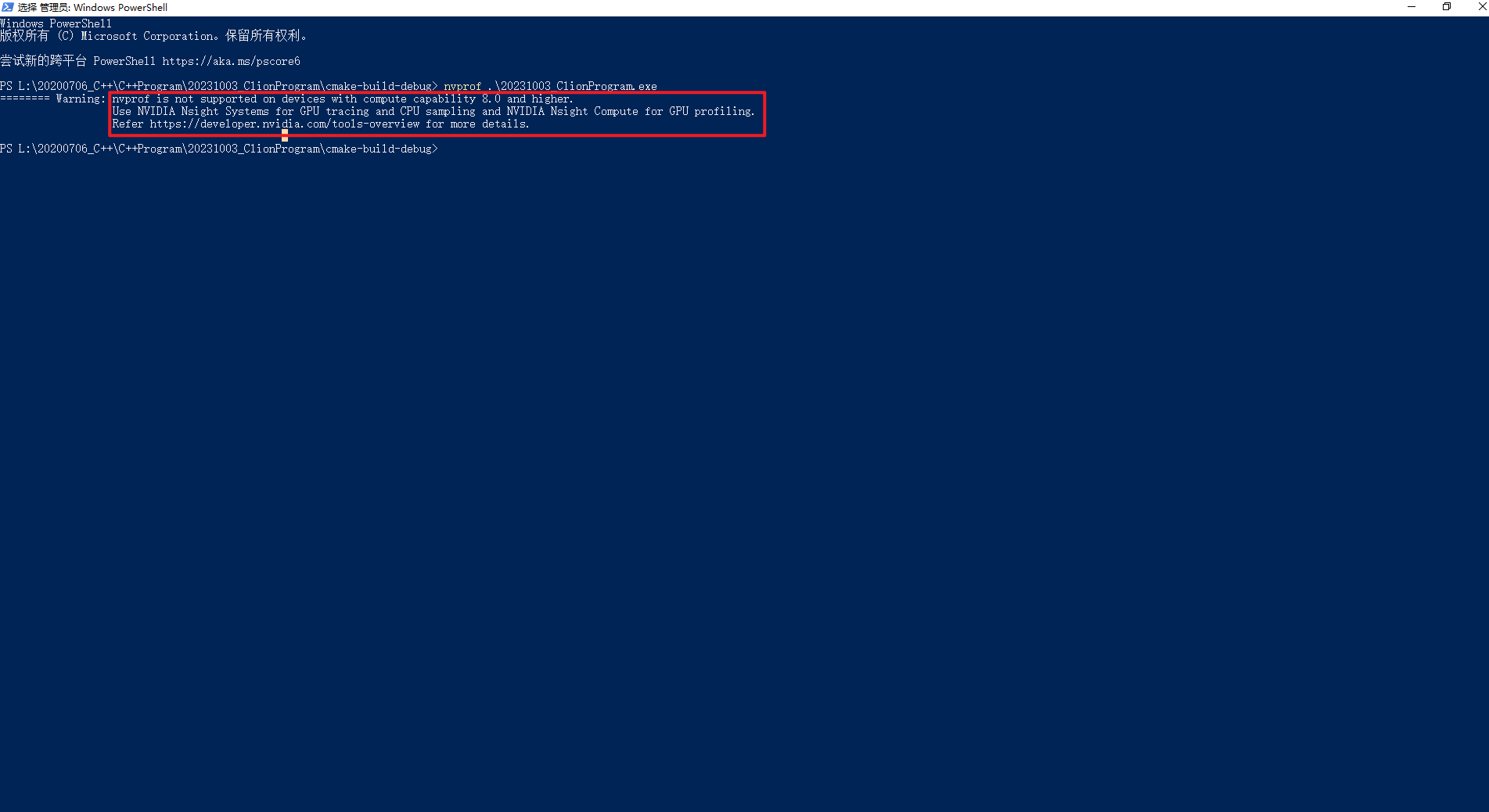
说明:对于计算能力为8.0及更高版本的设备,不支持使用nvprof。对于GPU跟踪和CPU采样,使用NVIDIA Nsight Systems;对于GPU分析,使用NVIDIA Nsight Compute。
这部分还不熟悉,先简要介绍,后续深入研究。Nsight是NVIDIA面相开发者提供的开发工具套件,能提供深入的跟踪、调试、评测和分析,以优化跨NVIDIA GPU和CPU的复杂计算应用程序。Nsight主要包含Nsight System、Nsight Compute、Nsight Graphics三部分。
(1)Nsight System
所有与NVIDIA GPU相关的程序开发都可以从Nsight System开始以确定最大的优化机会。Nsight System给开发者一个系统级别的应用程序性能的可视化分析。开发人员可以优化瓶颈,以便在任意数量或大小的CPU和GPU之间实现高效扩展[4]。
(2)Nsight Compute
Nsight Compute是一个CUDA应用程序的交互式kernel分析器。它通过用户接口和命令行工具的形式提供了详细的性能分析度量和API调试。Nsight Compute还提供了定制化的和数据驱动的用户接口和度量集合,可以使用分析脚本对这些界面和度量集合进行扩展,以获得后处理的结果[5]。
(3)Nsight Graphics
Nsight Graphics是一个用于调试、评测和分析Microsoft Windows和Linux上的图形应用程序。它允许您优化基于Direct3D 11,Direct3D 12,DirectX,Raytracing 1.1,OpenGL,Vulkan和KHR Vulkan Ray Tracing Extension的应程序的性能[6]。
3.CUDA数据类型
CUDA支持多种数据类型,包括标准的C/C++数据类型以及特定于CUDA的数据类型。常见的CUDA数据类型,如下所示:
(1)基本数据类型(与C/C++相似)
int
float
double
char
unsigned int
short
long
unsigned char
unsigned short
unsigned long
bool
void
signed int或signed
signed char
signed short
signed long
signed long long
unsigned long long
(2)向量数据类型
int1, int2, int3, int4: 1到4个整数元素的向量。
float1, float2, float3, float4: 1到4个浮点数元素的向量。
double1, double2, double3, double4: 1到4个双精度浮点数元素的向量。
(3)复数数据类型
cuComplex: 单精度复数。
cuDoubleComplex: 双精度复数。
(4)CUDA数据类型修饰符
__device__: 用于声明在设备上执行的函数或变量。
__constant__: 用于声明常量内存。
__shared__: 用于声明共享内存。
__global__: 用于声明全局内核函数。
(5)CUDA特定的数据类型
dim3: 三维坐标,通常用于线程和块的索引。
cudaStream_t: 用于管理CUDA流。
cudaEvent_t: 用于事件同步。
texture<...>: 用于声明纹理内存,支持不同的数据类型和维度。
除此之外CUDA还支持通过typedef和struct等方式定义自定义数据类型,以满足特定应用程序的需求。
4.C++数据类型
C++中数据类型完整列表,包括基本数据类型、复合数据类型和一些特殊数据类型,如下所示:
(1)基本数据类型
int
float
double
char
bool
void
wchar_t(宽字符类型)
short(或short int)
long(或long int)
long long(或long long int)
unsigned int
unsigned char
unsigned short
unsigned long
unsigned long long
(2)复合数据类型
array(数组)
struct(结构体)
union(联合体)
enum(枚举)
class(类)
(3)其它数据类型
signed(通常与int、char、short和long配合使用,表示有符号类型)
auto(C++11引入的自动类型推导)
decltype(C++11引入的类型推导)
nullptr(C++11引入的空指针)
5.通过deviceQuery.exe查下设备信息
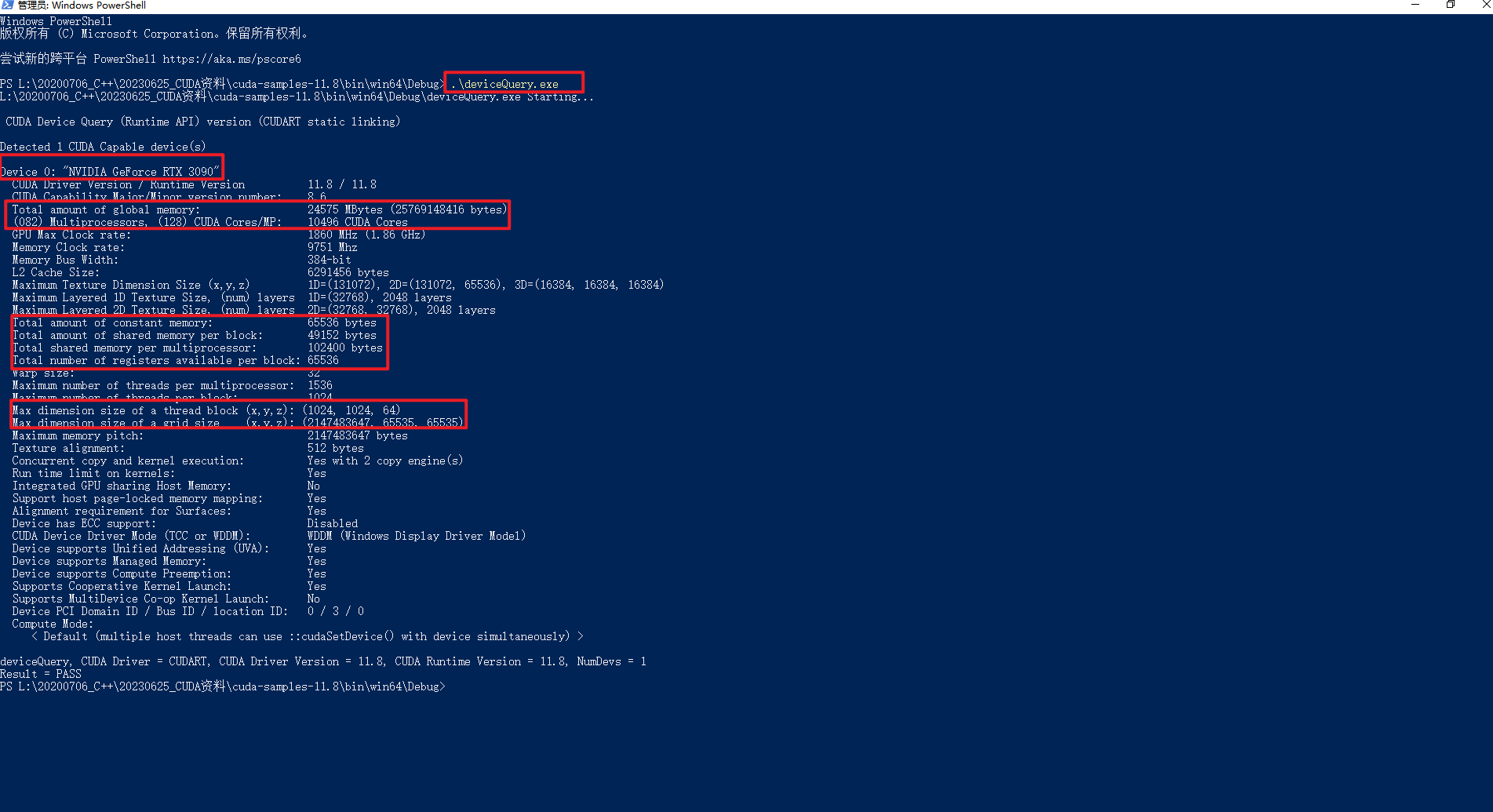
因为本地安装CUDA 11.8版本,所以下载https://github.com/NVIDIA/cuda-samples/releases/tag/v11.8,然后使用VS2022打开Samples_VS2022.sln编译,如下所示:

执行.\deviceQuery.exe后可以看到很多熟面孔的常量信息,如下所示:
参考文献:
[1]NVIDIA Developer Tools:https://developer.nvidia.com/tools-overview
[2]《CUDA C编程权威指南》
[3]使用Nsight工具分析优化应用程序:https://cloud.baidu.com/doc/GPU/s/el8mizux4
[4]https://developer.nvidia.com/nsight-systems
[5]https://developer.nvidia.com/nsight-compute
[6]https://developer.nvidia.com/nsight-graphics
[7]给核函数计时:https://github.com/ai408/nlp-engineering/tree/main/20230917_NLP工程化/20231004_高性能计算/20231003_CUDA编程/20231003_CUDA_C编程权威指南/2-CUDA编程模型/2.2-给核函数计时
CUDA C编程权威指南:2.2-给核函数计时的更多相关文章
- 『CUDA C编程权威指南』第二章编程题选做
第一题 设置线程块中线程数为1024效果优于设置为1023,且提升明显,不过原因未知,以后章节看看能不能回答. 第二题 参考文件sumArraysOnGPUtimer.cu,设置block=256,新 ...
- 读《Android编程权威指南》
因为去年双十二购买了一折的<Android 编程权威指南(第一版)>,在第二版出来后图灵社区给我推送了第二版的优惠码,激动之余就立马下单购买电子书,不得不说Big Nerd Ranch G ...
- 《Android编程权威指南》
<Android编程权威指南> 基本信息 原书名:Android programming: the big nerd ranch guide 原出版社: Big Nerd Ranch Gu ...
- Swift编程权威指南第2版 读后收获
自从参加工作一直在用OC做iOS开发.在2015年的时候苹果刚推出swift1.0不久,当时毕竟是新推出的语言,大家也都很有激情的学习.不过在学完后发现很难在实际项目中使用,再加上当时公司项目都是基于 ...
- 《Android编程权威指南》PhotoGallery应用梳理
PhotoGalley是<Android编程权威指南>书中另外一个重要的应用.
- 《Android编程权威指南》CriminalIntent项目梳理
相信很多新手或者初级开发人员都已经买了第2版的<Android编程权威指南>, 这本书基于Android Studio开发,对入门人员来说是很好的选择,但是很可惜的是, 在完成一个项目后, ...
- 使用最新AndroidStudio编写Android编程权威指南(第3版)中的代码会遇到的一些问题
Android编程权威指南(第3版)这本书是基于Android7.0的,到如今已经过于古老,最新的Android版本已经到10,而这本书的第四版目前还没有正式发售,在最近阅读这本书时,我发现这本书的部 ...
- Android编程权威指南第三版 第32章
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/qq_35564145/article/de ...
- Android编程权威指南(第2版)--第16章 使用intent拍照 挑战练习
16.7挑战练习:优化照片显示 新建dialog_photo.xml 1234567891011121314 <?xml version="1.0" encoding=&qu ...
- Android编程权威指南(第三版)- 2.8 挑战练习:添加后退按钮
package com.example.geoquiz; import android.support.v7.app.AppCompatActivity; import android.os.Bund ...
随机推荐
- 高可用只读,让RDS for MySQL更稳定
摘要:业务应用对数据库的数据请求分写请求(增删改)和读请求(查).当存在大量读请求时,为避免读请求阻塞写请求,数据库会提供只读实例方案.通过主实例+N只读实例的方式,实现读写分离,满足大量的数据库读取 ...
- 把langchain跑起来的3个方法
使用LangChain开发LLM应用时,需要机器进行GLM部署,好多同学第一步就被劝退了,那么如何绕过这个步骤先学习LLM模型的应用,对Langchain进行快速上手?本片讲解3个把LangChain ...
- Sentieon实战:NGS肿瘤变异检测流程
肿瘤基因突变检测是NGS的一个重要应用,其分析难点主要在于低频变异的准确性.不同于遗传病检测,肿瘤样本类型多样,测序方法和参数复杂,且缺乏对应各种场景的公共标准真集.再加上常用开源软件经常遇到的准确性 ...
- Vue + Element ui 实现动态表单,包括新增行/删除行/动态表单验证/提交功能
总结/朱季谦 最近通过Vue + Element ui实现了动态表单功能,该功能还包括了动态表单新增行.删除行.动态表单验证.动态表单提交功能,趁热打铁,将开发心得记录下来,方便以后再遇到类似功能时, ...
- P3574 [POI2014] FAR-FarmCraft 吐槽 + 题解
洛谷上面的题解写的真的不太好,有很多错误,我来谈谈自己的理解. 设 \(f[i]\) 表示以 \(i\) 为根节点的子树中(包括节点 \(i\))的所有人安装好游戏所需要的时间(与下面的 \(g[i] ...
- 博客代码托管网站个人体会及感受(GitHub、Coding、Netlity、阿里云弹性web托管)
GitHub 免费 部署 github上,服务器在国外,访问速度一般,稳定性比较好,网站知名,操作方便,部署简单,域名不需要备案. Coding 免费 coding 支持 PHP + mysql 的动 ...
- 基于Avalonia 11.0.0+ReactiveUI 的跨平台项目开发2-功能开发
基于Avalonia 11.0.0+ReactiveUI 的跨平台项目开发2-功能开发 项目简介:目标是开发一个跨平台的AI聊天和其他功能的客户端平台.目的来学习和了解Avalonia.将这个项目部署 ...
- 二进制安装K8S
参考链接:https://zhuanlan.zhihu.com/p/408967897 准备工作 3台Centos7.9虚拟机 虚拟机配置:2C4G,能连接外网 虚机规划 ip 用途 192.168. ...
- FPGA学习之乒乓操作
乒乓操作学习记录如下: 乒乓操作" 是一个常常应用于数据流控制的设计思想, 典型的乒乓操作方法如下图 所示: 乒乓操作的处理流程为:输入数据流通过" 输入数据选择单元"将 ...
- python分割多个分隔符
想一次指定多个分隔符,可以用re模块 import retext='3.14:15'result = re.split('[.:]', text)print(result) 输出结果如下: ['3', ...