[转帖]9.2 TiFlash 架构与原理
9.2 TiFlash 架构与原理
相比于行存,TiFlash 根据强 Schema 按列式存储结构化数据,借助 ClickHouse 的向量化计算引擎,带来读取和计算双重性能优势。相较于普通列存,TiFlash 则具有实时更新、分布式自动扩展、SI(Snapshot Isolation)隔离级别读取等优势。本章节将从架构和原理的角度来解读 TiFlash。
9.2.1 基本架构
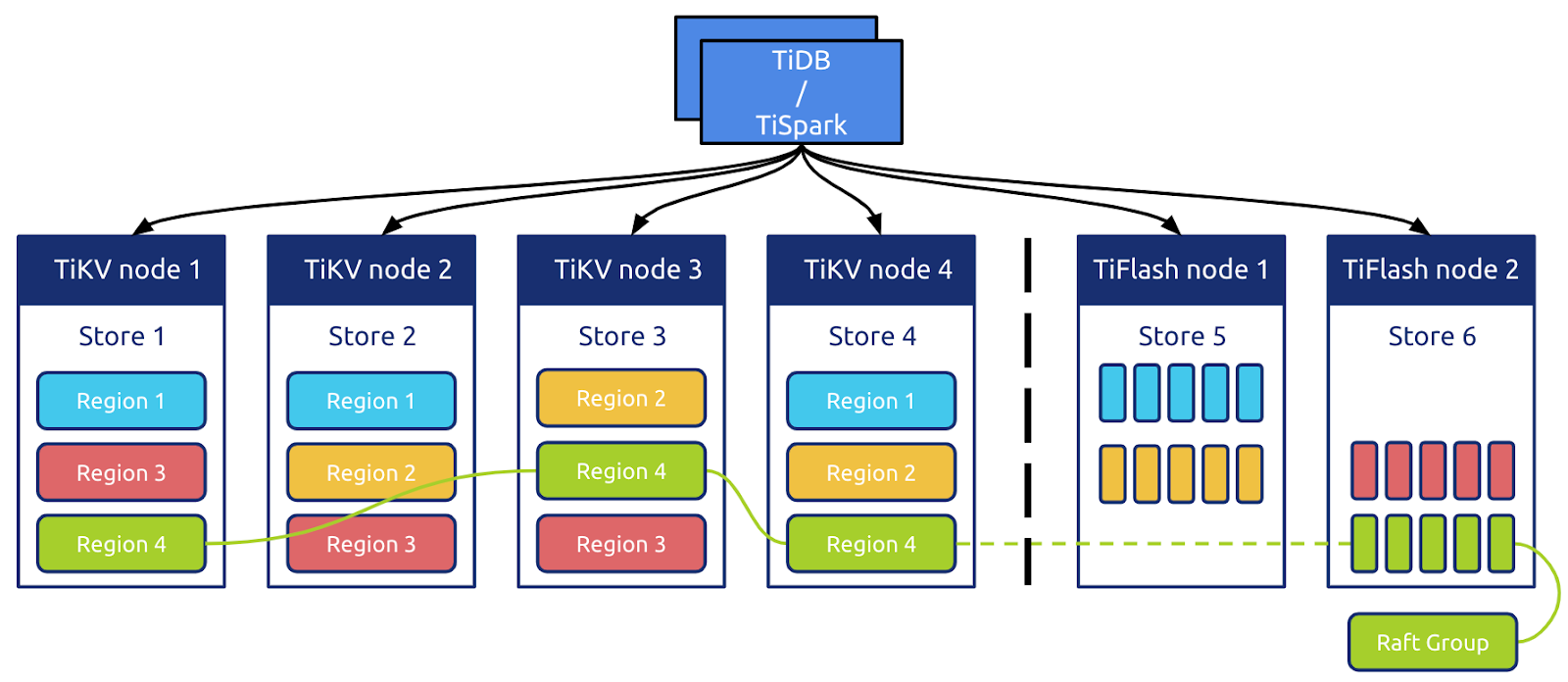
TiFlash 引擎补全了 TiDB 在 OLAP 方面的短板。TiDB 可通过计算层的优化器分析,或者显式指定等方式,将部分运算下推到对应的引擎,达到速度的提升。值得一提的是,在表关联场景下,即便 TiFlash 架构没有 MPP 相关功能,借助 TiDB 的查询优化器、布隆过滤器下推和表广播等手段,相当比例的关联场景仍可享受 TiFlash 加速。
如上图所示,TiFlash 能以 Raft Learner Store 的角色无缝接入 TiKV 的分布式存储体系。TiKV 基于 Key 范围做数据分片并将一个单元命名为 Region,同一 Region 的多个 Peer(副本)分散在不同存储节点上,共同组成一个 Raft Group。每个 Raft Group 中,Peer 按照角色划分主要有 Leader、Follower、Learner。在 TiKV 节点中,Peer 的角色可按照一定的机制切换,但考虑到底层数据的异构性,所有存在于 TiFlash 节点的 Peer 都只能是 Learner(在协议层保证)。TiFlash 对外可以视作特殊的 TiKV 节点,接受 PD 对于 Region 的统一管理调度。TiDB 和 TiSpark 可按照和 TiKV 相同的 Coprocessor 协议下推任务到 TiFlash。
在 TiDB 的体系中,每个 Table 含有 Schema、Index(索引)、Record(实际的行数据) 等内容。由于 TiKV 本身没有 Table 的概念,TiDB 需要将 Table 数据按照 Schema 编码为 Key-Value 的形式后写入相应 Region,通过 Multi-Raft 协议同步到 TiFlash,再由 TiFlash 根据 Schema 进行解码拆列和持久化等操作。
9.2.2 原理
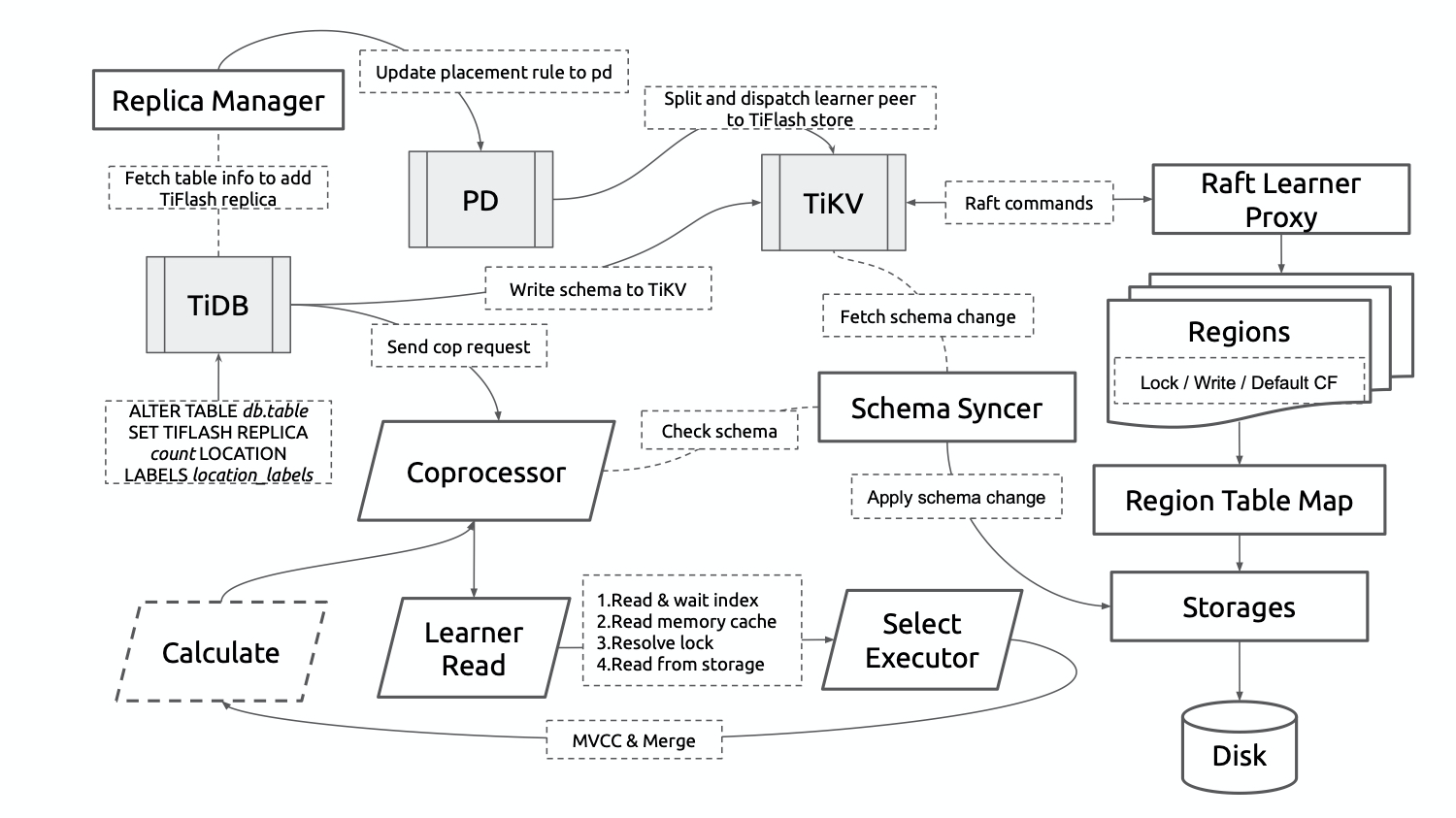
这是一张 TiFlash 数据同步到读取的基本流程架构图,以下将按照大类模块分别简单介绍。
1. Replica Manager
Index 这种主要面向点查的结构对于 TiFlash 的列式存储是没有意义的。为了避免同步冗余数据并实现按 Table 动态增删 TiFlash 列存副本,需要借助 PD 来有选择地同步 Region。
在同一个集群内的 TiFlash 节点会利用 PD 的 ETCD 选举并维护一个 Replica Manager 来负责与 PD 和 TiDB 交互。当感知到 TiDB 对于 TiFlash 副本的操作后(DDL 语句),会将其转化为 PD 的 Placement Rule,通过 PD 令 TiKV 分裂出指定 Key 范围的 Region,为其添加 Learner Peer 并调度到集群中的 TiFlash 节点。此外,当 Table 的 TiFlash 副本尚未可用时,Replica Manager 还负责向各个 TiFlash 节点收集 Table 的数据同步进度并上报给 TiDB。
2. Raft Learner Proxy
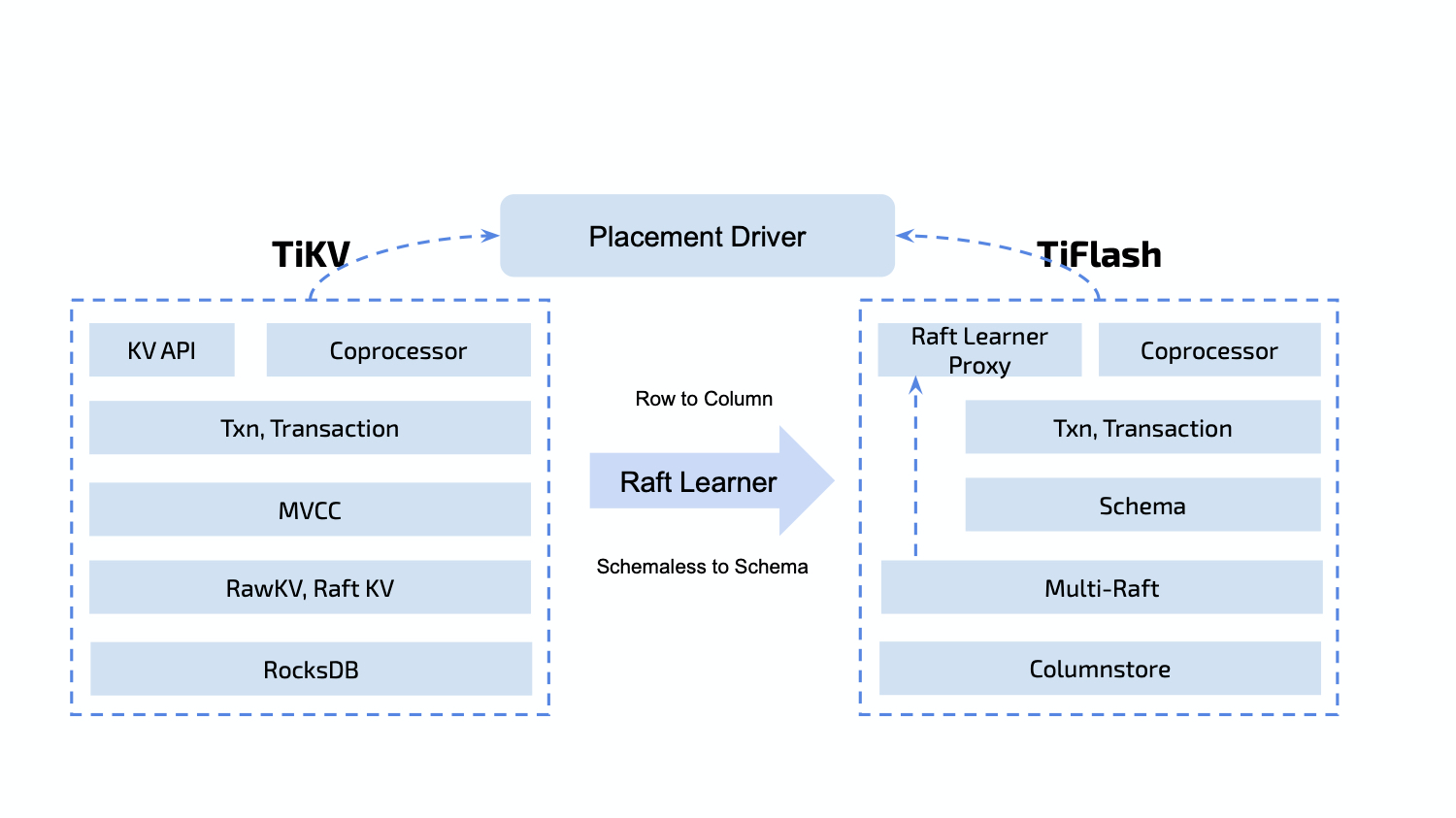
基于 Raft Learner 的数据同步机制是整个 TiFlash 存储体系的基石,也是数据实时性、正确性的根本保障。Region 的 Learner Peer 除了不参与投票和选举,仍要维护与其他 TiKV 节点中相同的全套状态机。因此,TiKV 被改造成了一个 Raft Proxy 库,并由 Proxy 和 TiFlash 协同维护节点内的 Region,其中实际的数据写入发生在 TiFlash 侧。
作为固定存在的 Learner,TiFLash 可以进行数据进行二次加工而不用担心对其他节点产生影响。TiFlash 在执行 Raft 命令时就可以做到剔除无效数据,将未提交的数据按 Schema 预解析等优化。同时 TiFlash 实现了对于 Raft 命令的幂等回放以及引擎层的幂等写,可以不记录 WAL 且只在必要的时刻做针对性的持久化,从而简化模型并降低了风险。
TiDB 的事务实现是基于 Percolator 模型的,映射到 TiKV 中则是对 3 个 CF(Column Family) 数据的读写:Write、Default、Lock。TiFlash 也在每个 Region 内部对此做了抽象,不同的是对于 TiFlash 而言,数据写入 CF 只能作为中间过程,最终持久化到存储层需要找到 Region 对应的 Table 再根据 Schema 进行行列结构转换。
3. Schema Syncer
每个 TiFlash 节点都会实时同步 TiDB 的最新的表 Schema 信息。TiFlash 兼容 TiDB 体系的在线 DDL,对经常需要做表结构修改的业务非常友好,例如增、删、改字段等操作都不影响在线业务。
4. Learner Read / Coprocessor
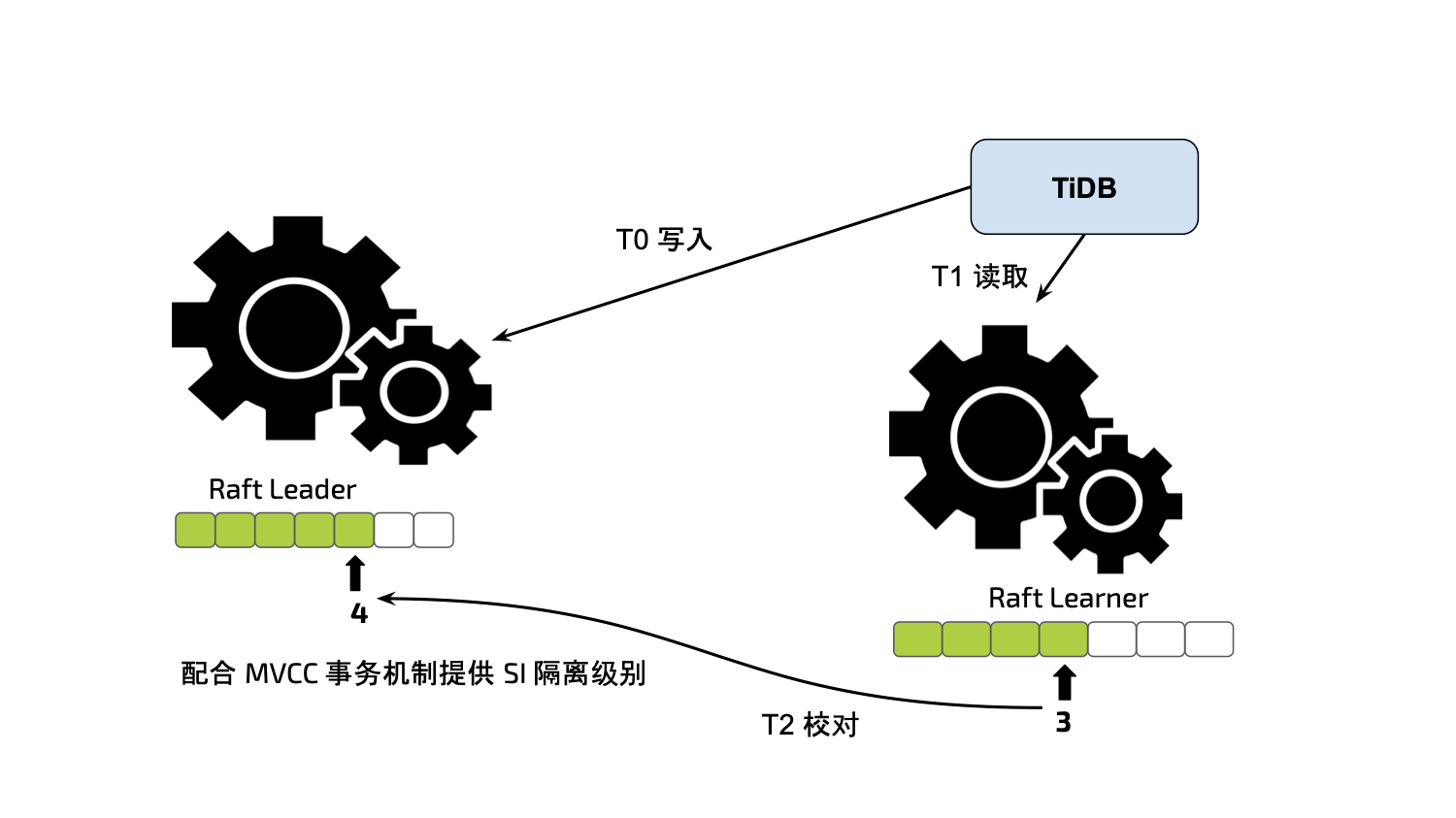
无论是通过 CH 客户端、TiSpark、CHSpark 还是 TiDB 向 TiFlash 发起查询,都需要 Learner Read 来确保外部一致性。在同一个 Raft Group 中,Index 是永续递增的(任何 Raft 命令都会对其产生修改),可被视作乐观锁。Region 本身含有 Version 和 Conf Version 两种版本号,当发生诸如 Split/Merge/ChangePeer 等操作时,版本号均会产生相应的变化。
所有的查询都需要由上层拆分为一个或多个 Region 的读请求,需要包含 Region 的两种版本号(可从 PD 或 TiKV 获取),Timestamp(用于 Snapshot Read 的时间戳,从 PD 获取),以及 Table 相关信息(Schema Version 从 TiDB 获取)。单次读请求可大致分为以下步骤:
- 校验并更新本节点的 Schema
- 向 Region 的 Leader Peer 获取最新的 Index,等待当前节点中 Learner 的 Applied Index 追上
- 校对 Version 和 Conf Version,检查 Lock CF 中的锁信息
- 读取内存中的半结构化数据和存储引擎中 Region 范围对应的结构化数据
- 按照 Timestamp 进行 Snapshot Read 和多路合并
- Coprocessor 计算(主要借助 ClickHouse 的向量化计算引擎)
9.2.3 TiFlash 对 OLAP 查询加速
OLAP 类的查询通常具有以下几个特点:
- 每次查询读取大量的行,但是仅需要少量的列
- 宽表,即每个表包含着大量的列
- 查询通过一张或多张小表关联一张大表,并对大表上的列做聚合
TiFlash 列存引擎针对这类查询有较好的优化效果:
(1) I/O 优化
- 每次查询可以只读取需要的列,减少了 I/O 资源的使用
- 同列数据类型相同,相较于行存可以获得更高的压缩比
- 整体的 I/O 减少,令内存的使用更加高效
(2) CPU 优化
- 列式存储可以很方便地按批处理字段,充分利用 CPU Cache 取得更好的局部性
- 利用向量化处理指令并行处理部分计算
9.2.4 TiKV 与 TiFlash 配合
TiFlash 可被当作列存索引使用,获得更精确的统计信息。对于关联查询来说,点查相关的任务可以下推到 TiKV,而需要关联的大批量聚合查询则会下推到TiFlash,通过两个引擎的配合,达到更快的速度。
9.2.5 总结与展望
TiFlash 是 TiDB HTAP 之路上的全新实践。这套架构体系也将伴随生产环境的使用不断演化发展,进而为用户解决更多问题。
[转帖]9.2 TiFlash 架构与原理的更多相关文章
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- HBase的基本架构及其原理介绍
1.概述:最近,有一些工程师问我有关HBase的基本架构的问题,其实这个问题仅仅说架构是非常简单,但是需要理解.在这里,我觉得可以用HDFS的架构作为借鉴.(其实像Hadoop生态系统中的大部分组建的 ...
- SQL Server AlwaysOn架构及原理
SQL Server AlwaysOn架构及原理 SQL Server2012所支持的AlwaysOn技术集中了故障转移群集.数据库镜像和日志传送三者的优点,但又不相同.故障转移群集的单位是SQL实例 ...
- 爱莲(iLinkIT)的架构与原理
随着移动互联网时代的到来,手机正在逐步替代其他的设备,手机是电话.手机是即时通讯,手机是相机,手机是导航仪,手机是钱包,手机是音乐播放器……. 除此之外,手机还是一个大大的U盘,曾几何时,我们用一根长 ...
- Hbase架构与原理
Hbase架构与原理 HBase是一个分布式的.面向列的开源数据库,该技术来源于 Fay Chang所撰写的Google论文"Bigtable:一个结构化数据的分布式存储系统".就 ...
- HDFS架构及原理
原文链接:HDFS架构及原理 引言 进入大数据时代,数据集的大小已经超过一台独立物理计算机的存储能力,我们需要对数据进行分区(partition)并存储到若干台单独的计算机上,也就出现了管理网络中跨多 ...
- Spark基本架构及原理
Hadoop 和 Spark 的关系 Spark 运算比 Hadoop 的 MapReduce 框架快的原因是因为 Hadoop 在一次 MapReduce 运算之后,会将数据的运算结果从内存写入到磁 ...
- Oracle rac架构和原理
Oracle RAC Oracle Real Application Cluster (RAC,实时应用集群)用来在集群环境下实现多机共享数据库,以保证应用的高可用性:同时可以自动实现并行处理 ...
- storm架构及原理
storm 架构与原理 1 storm简介 1.1 storm是什么 如果只用一句话来描述 storm 是什么的话:分布式 && 实时 计算系统.按照作者 Nathan Marz 的说 ...
- atitit.jndi的架构与原理以及资源配置and单元测试实践
atitit.jndi的架构与原理以及资源配置and单元测试实践 1. jndi架构 1 2. jndi实现原理 3 3. jndi资源配置 3 3.1. resin <database> ...
随机推荐
- Centos7 Zabbix3.2安装(yum)
http://repo.zabbix.com/zabbix/3.2/rhel/7/x86_64/ #官网下载地址(只包含zabbix的应用包) ftp://47.104.78.123/zabbix/ ...
- 谈谈muduo库的销毁连接对象——C++程序内存管理和线程安全的极致体现
前言 网络编程的连接断开一向比连接建立复杂的多,这一点在陈硕写的muduo库中体现的淋漓尽致,同时也充分体现了C++程序在对象生命周期管理上的复杂性,稍有不慎,满盘皆输. 为了纪念自己啃下muduo库 ...
- 常用的 SQL
只知道字段名字查找表 SELECT table_name FROM information_schema.columns WHERE column_name = '字段名'; 查看不等于NULL的数据 ...
- JavaScript异步编程1——Promise的初步使用
目录 1. 概述 2. 详论 3. 参考 1. 概述 Promise对象是ES6提出的的异步编程的规范.说到异步编程,就不得不说说同步和异步这两个概念. 从字面意思理解同步编程的话,似乎指的是两个任务 ...
- 基于Atlas 200 DK的原版YOLOv3(基于Darknet-53)实现(Python版本)
[摘要]本文将为大家带来使用Atlas 200 DK的原版YOLOv3(基于Darknet-53)实现的展示. 前言 YOLOv3可以算作是经典网络了,较好实现了速度和精度的Trade off,成为和 ...
- 避坑指南:关于SPDK问题分析过程
[前言] 这是一次充满曲折与反转的问题分析,资料很少,代码很多,经验很少,概念很多,当内核态,用户态,DIF,LBA,大页内存,SGL,RDMA,NVME和SSD一起迎面而来的时候,问题是单点的意外, ...
- 转角遇上Volcano,看HPC如何应用在气象行业
摘要:高性能计算(HPC)在各个领域都有广泛的应用.本文通过典型的HPC应用WRF,介绍了HPC应用在Kubernetes+Volcano上运行方式. Kubernetes已经成为云原生应用编排.管理 ...
- 带你认识大模型训练关键算法:分布式训练Allreduce算法
摘要:现在的模型以及其参数愈加复杂,仅仅一两张的卡已经无法满足现如今训练规模的要求,分布式训练应运而生. 本文分享自华为云社区<分布式训练Allreduce算法>,原文作者:我抽签必中. ...
- tsconfig.json在配置文件中找不到任何输入,怎么办?
摘要:原来在我们创建tsconfig.json文件的时候,VSCode会自动检测当前项目当中是否有TS文件:如果没有的话,就会报这个错提示我们去创建一个文件,再去使用. 本文分享自华为云社区<t ...
- Axure 自定义元件库
点击文件 -> 新建元件库 可以添加多个元件,并将期重命名 保存元件库 新建页面 添加元件,选择自建的元件库 导入后就会发现我的原件库 这样就可以使用我们自定义的元件库了