时间复杂度为 O(n^2) 的排序算法
对于小规模数据,我们可以选用时间复杂度为 O(n2) 的排序算法。因为时间复杂度并不代表实际代码的执行时间,它省去了低阶、系数和常数,仅代表的增长趋势,所以在小规模数据情况下, O(n2) 的排序算法可能会比 O(nlogn) 的排序算法执行效率高。不过随着数据规模增大, O(nlogn) 的排序算法是不二选择。本篇我们主要对 O(n2) 的排序算法进行介绍,在介绍之前,我们先了解一下算法特性:
算法特性:
稳定性:经排序后,若等值元素之间的相对位置不变则为稳定排序算法,否则为不稳定排序算法
原地排序:是否借助额外辅助空间
自适应性: 自适应性排序受输入数据的影响,即最佳/平均/最差时间复杂度不等,而非自适应排序时间复杂度恒定
本篇我们将着重介绍插入排序,选择排序和冒泡排序了解即可。
插入排序
插入排序的工作方式像整理手中的扑克牌一样,即不断地将每一张牌插入到其他已经有序的牌中适当的位置。
插入排序的当前索引元素左侧的所有元素都是有序的:若当前索引为 i,则 [0, i - 1] 区间内的元素始终有序,这种性质被称为循环不变式,即在第一次迭代、迭代过程中和迭代结束时,这种性质始终保持不变。
不过,这些有序元素的索引位置暂时不能确定,因为它们可能需要为更小的元素腾出空间而向右移动。插入排序的代码实现如下:
private void sort(int[] nums) {
for (int i = 1; i < nums.length; i++) {
int base = nums[i];
int j = i - 1;
while (j >= 0 && nums[j] > base) {
nums[j + 1] = nums[j--];
}
nums[j + 1] = base;
}
}
它的实现逻辑是取未排序区间中的某个元素为基准数base,将base与其左侧已排序区间元素依次比较大小,并"插入"到正确位置。插入排序对部分有序(数组中每个元素距离它的最终位置都不远或数组中只有几个元素的位置不正确等情况)的数组排序效率很高。事实上,当逆序很少或数据量不大(n2和nlogn比较接近)时,插入排序可能比其他任何排序算法都要快,这也是一些编程语言的内置排序算法在针对小数据量数据排序时选择使用插入排序的原因。
算法特性:
空间复杂度:O(1)
原地排序
稳定排序
自适应排序:当数组为升序时,时间复杂度为 O(n);当数组为降序时,时间复杂度为 O(n2)
希尔排序
插入排序对于大规模乱序数组排序很慢,因为它只会交换相邻的元素,所以元素只能一步步地从一端移动到另一端,如果最小的元素恰好在数组的最右端,要将它移动到正确的位置需要移动 N - 1 次。
希尔排序是基于插入排序改进的排序算法,它可以交换不相邻的元素以对数组的局部进行排序,并最终用插入排序将局部有序的数组排序。它的思想是使数组中间隔为 h 的元素有序(h 有序数组),如下图为间隔为 4 的有序数组:
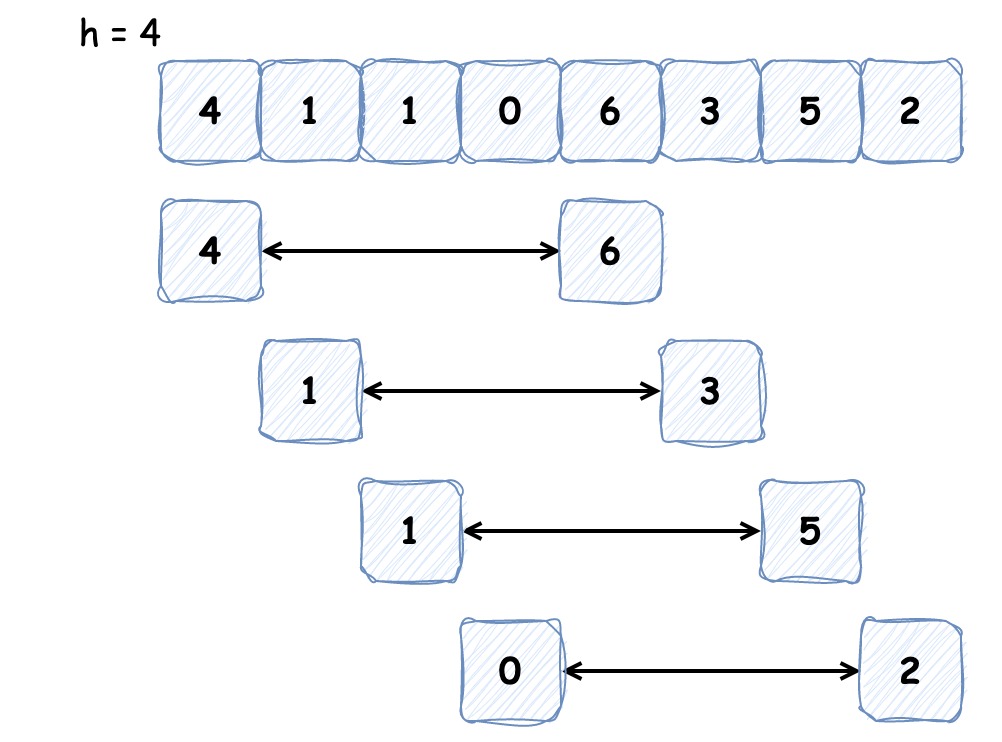
排序之初 h 较大,这样我们能将较小的元素尽可能移动到靠近左端的位置,为实现更小的 h 有序创造便利,最后一次循环时 h 为 1,便是我们熟悉的插入排序。这就是希尔排序的过程,代码实现如下:
private void sort(int[] nums) {
int N = nums.length;
int h = 1;
while (h < N / 3) {
h = 3 * h + 1;
}
while (h >= 1) {
for (int i = h; i < N; i++) {
int base = nums[i];
int j = i - h;
while (j >= 0 && nums[j] > base) {
nums[j + h] = nums[j];
j -= h;
}
nums[j + h] = base;
}
h /= 3;
}
}
希尔排序更高效的原因是它权衡了子数组的规模和有序性,它也可以用于大型数组。排序之初,各个子数组都很短,排序之后子数组都是部分有序的,这两种情况都很适合插入排序。
选择排序
选择排序的实现非常简单:每次选择未排序数组中的最小值,将其放到已排序区间的末尾,代码实现如下:
private void sort(int[] nums) {
for (int i = 0; i < nums.length; i++) {
int min = i;
for (int j = i + 1; j < nums.length; j++) {
if (nums[j] < nums[min]) {
min = j;
}
}
swap(nums, i, min);
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
算法特性:
空间复杂度:O(1)
原地排序
非稳定排序:会改变等值元素之间的相对位置
非自适应排序:最好/平均/最坏时间复杂度均为 O(n2)
冒泡排序
冒泡排序通过连续地比较与交换相邻元素实现排序,每轮循环会将未被排序区间内的最大值移动到数组的最右端,这个过程就像是气泡从底部升到顶部一样,代码实现如下:
public void sort(int[] nums) {
for (int i = nums.length - 1; i > 0; i--) {
// 没有发生元素交换的标志位
boolean flag = true;
for (int j = 0; j < i; j++) {
if (nums[j] > nums[j + 1]) {
swap(nums, j, j + 1);
flag = false;
}
}
if (flag) {
break;
}
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
算法特性:
空间复杂度:O(1)
原地排序
稳定排序
自适应排序:经过优化后最佳时间复杂度为 O(n)
巨人的肩膀
《算法导论 第三版》第 2.1 章
《算法 第四版》第 2.1 章
《Hello 算法》第 11 章
作者:京东物流 王奕龙
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
时间复杂度为 O(n^2) 的排序算法的更多相关文章
- 排序算法汇总(C/C++实现)
前言: 本人自接触算法近2年以来,在不断学习中越多地发觉各种算法中的美妙.之所以在这方面过多的投入,主要还是基于自身对高级程序设计的热爱,对数学的沉迷.回想一下,先后也曾参加过ACM大大小小的 ...
- 十大经典排序算法总结——JavaScrip版
首先,对于评述算法优劣术语的说明: 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面:即排序后2个相等键值的顺序和排序之前它们的顺序相同 不稳定:如果a原本在b的前面,而a=b,排序之后a ...
- 插入排序算法--直接插入算法,折半排序算法,希尔排序算法(C#实现)
插入排序算法主要分为:直接插入算法,折半排序算法(二分插入算法),希尔排序算法,后两种是直接插入算法的改良.因此直接插入算法是基础,这里先进行直接插入算法的分析与编码. 直接插入算法的排序思想:假设有 ...
- js排序算法汇总
JS家的排序算法 十大经典算法排序总结对比 一张图概括: 主流排序算法概览 名词解释: n: 数据规模k:“桶”的个数In-place: 占用常数内存,不占用额外内存Out-place: 占用额外 ...
- 八大排序算法Java实现
本文对常见的排序算法进行了总结. 常见排序算法如下: 直接插入排序 希尔排序 简单选择排序 堆排序 冒泡排序 快速排序 归并排序 基数排序 它们都属于内部排序,也就是只考虑数据量较小仅需要使用内存的排 ...
- java实现八大排序算法
Arrays.sort() 采用了2种排序算法 -- 基本类型数据使用快速排序法,对象数组使用归并排序. java的Collections.sort算法调用的是归并排序,它是稳定排序 方法一:直接插入 ...
- [java初探06]__排序算法的简单认识
今天,准备填完昨天没填的坑,将排序算法方面的知识系统的学习一下,但是在简单的了解了一下后,有些不知如何组织学习了,因为排序算法的种类,实在是太多了,各有优略,各有适用的场景.有些不知所措,从何开始. ...
- 排序算法Java版,以及各自的复杂度,以及由堆排序产生的top K问题
常用的排序算法包括: 冒泡排序:每次在无序队列里将相邻两个数依次进行比较,将小数调换到前面, 逐次比较,直至将最大的数移到最后.最将剩下的N-1个数继续比较,将次大数移至倒数第二.依此规律,直至比较结 ...
- 各排序算法的Java实现及简单分析
一,直接插入排序 //直接插入排序的算法时间复杂度分析: //如果输入为正序,则每次比较一次就可以找到元素最终位置,复杂度为O(n) //如果输入为反序,则每次要比较i个元素,复杂度为O(n2) // ...
- python 十大经典排序算法
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存.常见的内部排序算法有:插入排序.希尔排序.选 ...
随机推荐
- 记一次MySql灾难性事件
2023年8月8日,本来系一个风和日丽的夏天中的平凡一天,但这种平凡,注定住佢一定唔平凡,唉...现在回忆起都阵阵咁痛!!! 重要嘅事情讲三次,唔好手贱,唔好手贱,唔好手贱 事日,如常上班,本人系一名 ...
- IDEA使用@Autowired注解为什么会提示不建议?
在使用IDEA编写Spring相关的项目时,当在字段上使用@Autowired注解时,总会出现一个波浪线提示:"Field injection is not recommended.&qu ...
- 开源 SD-Small 和 SD-Tiny 知识蒸馏代码与权重
最近,人工智能社区在开发更大.更高性能的语言模型方面取得了显著的进展,例如 Falcon 40B.LLaMa-2 70B.Falcon 40B.MPT 30B; 以及在图像领域的模型,如 SD2.1 ...
- shopee商品详情接口的应用
Shopee是东南亚和台湾地区最大的电子商务平台之一,成立于2015年,目前覆盖6个国家和地区.作为一家新兴电商平台,Shopee拥有快速增长的销售额和庞大的用户群体,为开发者提供了丰富的商业机会.其 ...
- Got permission denied while trying to connect to the Docker daemon socket at unix:///var/run/docker.so
在安装Docker以后,执行命令出现错误. Got permission denied while trying to connect to the Docker daemon socket at u ...
- 全是中文的txt文件查找特定字符并输出该行到新文件
tangshi.txt文件为全为汉唐诗 在该文件中查找指定字符 codecs库为打开中文文件的库,详情自行知乎 tangshi.txt大概十几万行,需要该文件练手的同学下方评论 要点:更改文件字符编码 ...
- RocketMQ 消息重试与死信队列
RocketMQ 消息重试与死信队列 RocketMQ 前面系列文章如下: RocketMQ系列(一) 基本介绍 RocketMQ 系列(二) 环境搭建 RocketMQ 系列(三) 集成 Sprin ...
- Centos7使用ssh免密登陆同时禁用root密码登陆
Centos7使用ssh免密登陆同时禁用root密码登陆 首先配置免密登陆,参考:ssh免密登陆 禁用root密码登陆 修改 /etc/ssh/sshd_config 文件 找到: RSAAuthen ...
- Q-REG论文阅读
Q-REG Jin, S., Barath, D., Pollefeys, M., & Armeni, I. (2023). Q-REG: End-to-End Trainable Point ...
- Python基础概要(一天快速入门)
文章目录 一 编程与编程语言 二 编程语言分类 三 主流编程语言介绍 四 Python介绍 五 安装python解释器 六 第一个python程序 七 变量 八 用户与程序交互 九 基本数据类型 十 ...