4、SpringBoot连接数据库引入druid
系列导航
6、SpringBoot-mybatis分页实现pagehelper
9、SpringBoot-mybatis-druid多源数据多源数据
10、SpringBoot-mybatis-plus-druid多源数据
11、SpringBoot-mybatis-plus-druid多源数据事务
12、SpringBoot-mybatis-plus-ehcache
14、SpringBoot-easyexcel导出excle
完结
以前以为druid是用来连接数据库的,其实这样理解不太对,连接数据库还是驱动,druid起到一个连接池的作用,监控管理连接数据库的状态之类的。
1、创建springboot项目
具体步骤参见之前的项目创建文档 1、springboot工程新建(单模块)
2、pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>demo</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>demo</name>
<description>Demo project for Spring Boot</description> <properties>
<java.version>1.8</java.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<spring-boot.version>2.1.17.RELEASE</spring-boot.version>
</properties> <dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> <dependency>
<groupId>com.oracle</groupId>
<artifactId>ojdbc6</artifactId>
<version>11.2.0.3</version>
</dependency> <!-- 集成druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.1.10</version>
</dependency> <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
<exclusions>
<exclusion>
<groupId>org.junit.vintage</groupId>
<artifactId>junit-vintage-engine</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies> <dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-dependencies</artifactId>
<version>${spring-boot.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement> <build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<version>2.1.17.RELEASE</version>
<configuration>
<mainClass>com.example.demo.DemoApplication</mainClass>
</configuration>
<executions>
<execution>
<id>repackage</id>
<goals>
<goal>repackage</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build> </project>
3、application.properties配置
增加druid的配置
# 应用名称
spring.application.name=demo
# 应用服务 WEB 访问端口
server.port=8080 # 数据库设置
spring.datasource.driverClassName=oracle.jdbc.OracleDriver
spring.datasource.url=jdbc:oracle:thin:@192.168.0.100:1521:orcl
spring.datasource.username=zy
spring.datasource.password=1 # druid配置
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource # druid参数调优(可选)
# 初始化大小,最小,最大
spring.datasource.initialSize=5
spring.datasource.minIdle=5
spring.datasource.maxActive=20
# 配置获取连接等待超时的时间
spring.datasource.maxWait=60000
# 配置间隔多久才进行一次检测,检测需要关闭的空闲连接,单位是毫秒
spring.datasource.timeBetweenEvictionRunsMillis=60000
# 配置一个连接在池中最小生存的时间,单位是毫秒
spring.datasource.minEvictableIdleTimeMillis=300000
# 测试连接
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
# 打开PSCache,并且指定每个连接上PSCache的大小
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
# 配置监控统计拦截的filters
spring.datasource.filters=stat
# asyncInit是1.1.4中新增加的配置,如果有initialSize数量较多时,打开会加快应用启动时间
spring.datasource.asyncInit=true
注:必填项只有
# druid配置
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
4、数据库准备
oracle里创建表及初始化表
注:oralce中创建的用户为zy,密码为1
CREATE TABLE TEST_BLOCK_T
(
BLOCK_ID VARCHAR2(10 BYTE) PRIMARY KEY, --编码
BLOCK_NAME VARCHAR2(200 BYTE) --资源名称
);
Insert into TEST_BLOCK_T (BLOCK_ID, BLOCK_NAME) Values ('1', 'java');
COMMIT;
5、DruidConfig.java配置
由于现在Spring Boot不支持druid配置,参数调优部分的配置不会直接生效,需要配置datasource bean,从application.properties中读取值来装配datasource bean,新增DruidConfig.java配置文件:
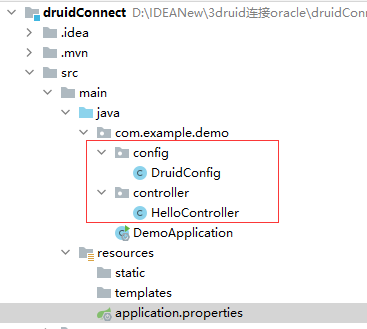
package com.example.demo.config; import java.sql.SQLException; import javax.sql.DataSource; import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary; import com.alibaba.druid.pool.DruidDataSource; @Configuration
public class DruidConfig {
private Logger logger = LoggerFactory.getLogger(DruidConfig.class); @Value("${spring.datasource.url}")
private String dbUrl; @Value("${spring.datasource.username}")
private String username; @Value("${spring.datasource.password}")
private String password; @Value("${spring.datasource.driver-class-name}")
private String driverClassName; @Value("${spring.datasource.initial-size}")
private int initialSize; @Value("${spring.datasource.min-idle}")
private int minIdle; @Value("${spring.datasource.max-active}")
private int maxActive; @Value("${spring.datasource.max-wait}")
private int maxWait; @Value("${spring.datasource.time-between-eviction-runs-millis}")
private int timeBetweenEvictionRunsMillis; @Value("${spring.datasource.min-evictable-idle-time-millis}")
private int minEvictableIdleTimeMillis; @Value("${spring.datasource.test-while-idle}")
private boolean testWhileIdle; @Value("${spring.datasource.test-on-borrow}")
private boolean testOnBorrow; @Value("${spring.datasource.test-on-return}")
private boolean testOnReturn; @Value("${spring.datasource.pool-prepared-statements}")
private boolean poolPreparedStatements; @Value("${spring.datasource.max-pool-prepared-statement-per-connection-size}")
private int maxPoolPreparedStatementPerConnectionSize; @Value("${spring.datasource.filters}")
private String filters; @Bean //声明其为Bean实例
@Primary //在同样的DataSource中,首先使用被标注的DataSource
public DataSource dataSource(){
DruidDataSource datasource = new DruidDataSource(); datasource.setUrl(this.dbUrl);
datasource.setUsername(username);
datasource.setPassword(password);
datasource.setDriverClassName(driverClassName); //configuration
datasource.setInitialSize(initialSize);
datasource.setMinIdle(minIdle);
datasource.setMaxActive(maxActive);
datasource.setMaxWait(maxWait);
datasource.setTimeBetweenEvictionRunsMillis(timeBetweenEvictionRunsMillis);
datasource.setMinEvictableIdleTimeMillis(minEvictableIdleTimeMillis);
datasource.setTestWhileIdle(testWhileIdle);
datasource.setTestOnBorrow(testOnBorrow);
datasource.setTestOnReturn(testOnReturn);
datasource.setPoolPreparedStatements(poolPreparedStatements);
datasource.setMaxPoolPreparedStatementPerConnectionSize(maxPoolPreparedStatementPerConnectionSize);
try {
datasource.setFilters(filters);
} catch (SQLException e) {
logger.error("druid configuration initialization filter", e);
} return datasource;
}
}
package com.example.demo.controller; import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.*; @RestController
@RequestMapping("/hello")
public class HelloController { @Autowired
JdbcTemplate jdbcTemplate; @GetMapping("/list")
@ResponseBody
public String index() { String sql = "SELECT BLOCK_NAME FROM XY_DIC_BLOCK_T WHERE BLOCK_ID = ?"; // 通过jdbcTemplate查询数据库
String mobile = (String) jdbcTemplate.queryForObject(
sql, new Object[]{1}, String.class);
System.out.println("haha");
return "Hello " + mobile;
}
}
6、启动项目访问项目

到这看着和前一个项目没撒区别,继续往下看
7、druid的监控页面
浏览器输入http://localhost:8080/druid
就会发现连接池的监控页面(要先执行一下步骤5,要不监控页面没有内容,因为还没有连接数据自然就没有连接的信息了)
4、SpringBoot连接数据库引入druid的更多相关文章
- Springboot项目引入druid安装部署使用
一.maven引入依赖,数据库驱动根据项目需求自行引入 <!-- https://mvnrepository.com/artifact/com.alibaba/druid-spring-boot ...
- springboot 中使用Druid 数据源提供数据库监控
一.springboot 中注册 Servlet/Filter/Listener 的方式有两种,1 通过代码注册 ServletRegistrationBean. FilterRegistration ...
- spring boot 学习(五)SpringBoot+MyBatis(XML)+Druid
SpringBoot+MyBatis(xml)+Druid 前言 springboot集成了springJDBC与JPA,但是没有集成mybatis,所以想要使用mybatis就要自己去集成. 主要是 ...
- springboot连接数据库报错testWhileIdle is true, validationQuery not set
问题描述: 使用springboot连接数据库,启动的时候报错:testWhileIdle is true, validationQuery not set.但是不影响系统使用,数据库等一切访问正常. ...
- SpringBoot整合阿里Druid数据源及Spring-Data-Jpa
SpringBoot整合阿里Druid数据源及Spring-Data-Jpa https://mp.weixin.qq.com/s?__biz=MzU0MDEwMjgwNA==&mid=224 ...
- SpringBoot学习(五)—— springboot快速整合Druid
Druid连接池 简介 由阿里巴巴开源的druid连接池是目前综合实力最突出的数据库连接池,而且还提供了监控日志功能,能够分析SQL执行情况. 引入druid连接池 pom.xml中加入 <de ...
- SpringBoot ---yml 整合 Druid(1.1.23) 数据源
SpringBoot ---yml 整合 Druid(1.1.23) 数据源 搜了一下,网络上有在配置类写 @Bean 配置的,也有 yml 配置的. 笔者尝试过用配置类配置 @Bean 的方法,结果 ...
- springboot项目整合druid数据库连接池
Druid连接池是阿里巴巴开源的数据库连接池项目,后来贡献给Apache开源: Druid的作用是负责分配.管理和释放数据库连接,它允许应用程序重复使用一个现有的数据库连接,而不是再重新建立一个: D ...
- Springboot中配置druid
pom文件信息: <!--引入druid数据源--> <!-- https://mvnrepository.com/artifact/com.alibaba/druid --> ...
- SpringBoot:Mybatis + Druid 数据访问
西部开源-秦疆老师:基于SpringBoot 2.1.7 的博客教程 秦老师交流Q群号: 664386224 未授权禁止转载!编辑不易 , 转发请注明出处!防君子不防小人,共勉! 简介 对于数据访问层 ...
随机推荐
- 35个超实用excel快捷键
以下是一些常用的Excel快捷键,希望对你有所帮助.如果你想要了解更多快捷键,可以参考Excel的官方文档或者在网上搜索相关信息. Ctrl + C:复制选定的单元格或单元格范围. Ctrl + X: ...
- 在CPF里使用OpenGL做跨平台桌面应用开发
CPF 是开源的C#跨平台UI框架,支持使用OpenGL来渲染,可以用来硬件加速播放视频或者显示3D模型 实现原理其实就是Skia用OpenGL后端,Skia里绑定GLView的OpenGL纹理,将纹 ...
- 前端优化之路:git commit 校验拦截
[前言] 前面在git分支规范那篇文章里,介绍了commit提交规范,如下图 但是想要做到高效落地执行,就需要做些别的功课,先展示下成果图 没错,对不符合规范的commit进行了拦截,符合才可以成功提 ...
- k8s~envoy上添加wasm插件
先查看这篇文章k8s~envoy的部署 当在Kubernetes中使用Envoy的WASM过滤器时,WASM过滤器会与Envoy一起部署在同一个Pod中,并与后端服务进行通信.以下是一个简单的关系图示 ...
- Cocos内存管理解析 CCRef/retain/release/autorelease
Cocos内存管理源码(autorelease解析) 背景 这段时间在做项目的时候,需求需要往spine动作的挂点上绑定按钮节点,由于按钮在编辑器中是加在已有节点上的,所以在往spine上添加挂点时, ...
- Spring 七种事务传播性介绍
作者:vivo 互联网服务器团队 - Zhou Shaobin 本文主要介绍了Spring事务传播性的相关知识. Spring中定义了7种事务传播性: PROPAGATION_REQUIRED PRO ...
- Terraform 的开源替代:OpenTofu 宣布 GA!
OpenTofu 社区于1月10日宣布 OpenTofu 项目 GA,这是 OpenTofu 的首个稳定版本(https://github.com/opentofu/opentofu/releases ...
- 2020-11-05:谈一下TCP的拥塞控制。
福哥答案2020-11-05: 所谓拥塞控制,是指防止过多的数据注入网络,保证网络中的路由器或链路不致过载.出现拥塞时,端点并不了解到拥塞发生的细节,对通信连接的端点来说,拥塞旺旺表现为通信时延的增加 ...
- Boost程序库完全开发指南:1-开发环境和构建工具
Boost官方于2019年12月发布的1.72版编写,共包含160余个库/组件,涵盖字符串与文本处理.容器.迭代器.算法.图像处理.模板元编程.并发编程等多个领域,使用Boost,将大大增强C++ ...
- 非暴力拆解:小熊派NB-IoT通信扩展板
摘要:相信大家对小熊派的NB-IoT通信扩展板已经非常了解了,但你有真正的了解过其内部构造吗?今天小编不聊技术,带你做一回拆·机·客! 相信大家对小熊派的NB-IoT通信扩展板已经非常了解了,但你有真 ...