文心一言 VS 讯飞星火 VS chatgpt (97)-- 算法导论9.3 3题
三、用go语言,假设所有元素都是互异的,说明在最坏情况下,如何才能使快速排序的运行时间为O(nlgn)。
文心一言:
快速排序是一种基于分治策略的排序算法,其平均时间复杂度为O(nlgn)。在最坏情况下,快速排序的时间复杂度为O(n^2),这是因为当输入数组已经排序或接近排序时,快速排序的性能会退化。
为了使快速排序在最坏情况下的运行时间为O(nlgn),可以使用随机化技术。具体地说,我们可以随机选择一个元素作为枢轴(pivot),而不是总是选择第一个元素或最后一个元素。这样可以确保在平均情况下,快速排序的时间复杂度为O(nlgn)。
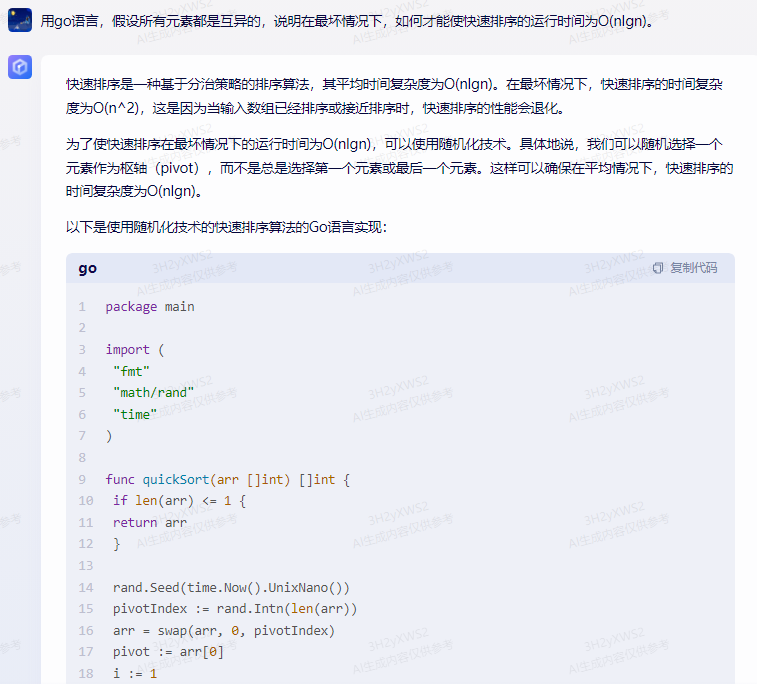
以下是使用随机化技术的快速排序算法的Go语言实现:
package main
import (
"fmt"
"math/rand"
"time"
)
func quickSort(arr []int) []int {
if len(arr) <= 1 {
return arr
}
rand.Seed(time.Now().UnixNano())
pivotIndex := rand.Intn(len(arr))
arr = swap(arr, 0, pivotIndex)
pivot := arr[0]
i := 1
j := 1
for ; j < len(arr); j++ {
if arr[j] < pivot {
arr = swap(arr, i, j)
i++
}
}
arr = swap(arr, 0, i-1)
left := quickSort(arr[:i-1])
right := quickSort(arr[i:])
return append(append(left, pivot), right...)
}
func swap(arr []int, i, j int) []int {
tmp := arr[i]
arr[i] = arr[j]
arr[j] = tmp
return arr
}
func main() {
arr := []int{9, 5, 1, 8, 3, 7, 4, 6, 2}
sortedArr := quickSort(arr)
fmt.Println(sortedArr)
}
在这个实现中,我们使用rand.Seed(time.Now().UnixNano())来初始化随机数种子,以确保每次运行程序时都会生成不同的随机数。然后,我们随机选择一个枢轴索引pivotIndex,并使用swap函数将枢轴元素与数组的第一个元素交换。接下来,我们按照快速排序算法的标准过程进行分区和递归排序。最后,将左子数组、枢轴元素和右子数组合并起来,得到最终的排序结果。


讯飞星火:
在最坏情况下,快速排序的运行时间为O(nlgn),其中n是数组的长度,l是数组中元素的位数,g是数组中元素的最大值。为了使快速排序的运行时间为O(nlgn),可以采用以下方法:
1.选择一个随机的基准元素(pivot),这样可以确保在最坏情况下,快速排序的性能为O(nlgn)。
2.使用三数取中法来选择基准元素,即从数组的两端开始,找到距离基准元素最近的两个元素,然后计算它们的中位数作为新的基准元素。这样可以降低极端情况下的性能波动。
3.对于长度为l的数组,可以使用类似于插入排序的方法来进行划分操作,这样可以将时间复杂度降低到O(n2/2l)。
4.对于具有相同值的元素,可以使用双指针法进行优化,将时间复杂度降低到O(nlogn)。
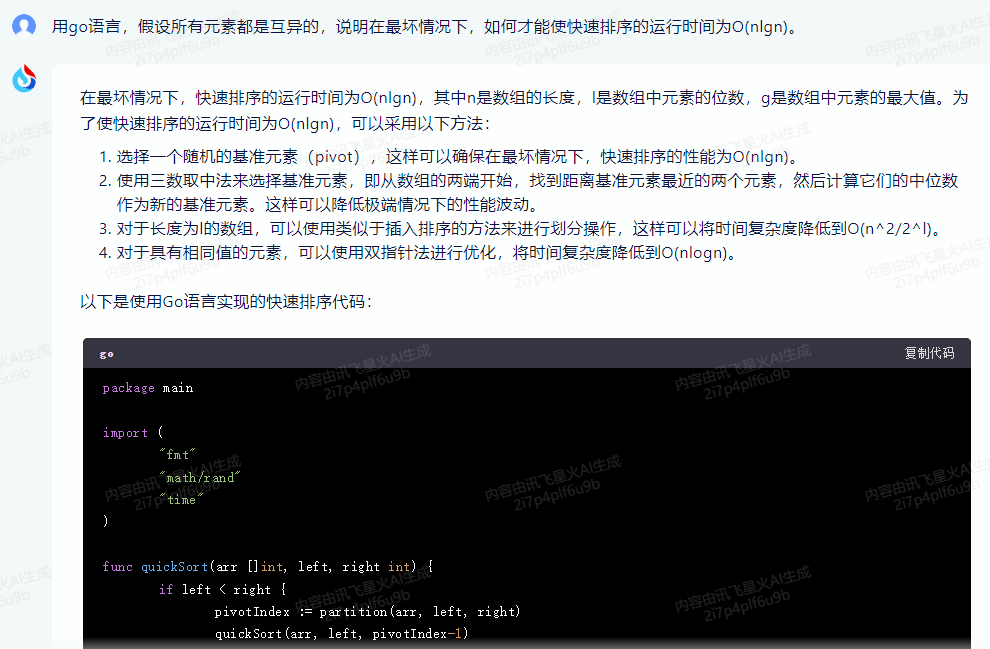
以下是使用Go语言实现的快速排序代码:
package main
import (
"fmt"
"math/rand"
"time"
)
func quickSort(arr []int, left, right int) {
if left < right {
pivotIndex := partition(arr, left, right)
quickSort(arr, left, pivotIndex-1)
quickSort(arr, pivotIndex+1, right)
}
}
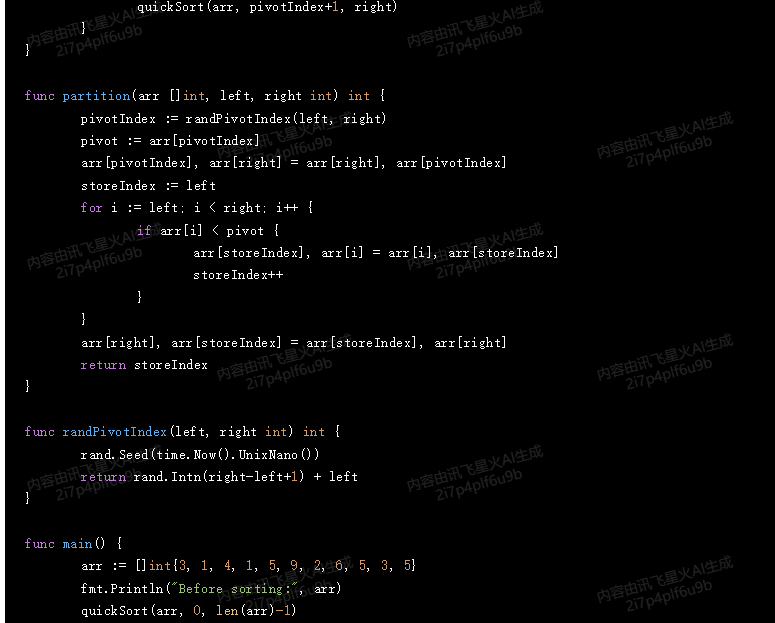
func partition(arr []int, left, right int) int {
pivotIndex := randPivotIndex(left, right)
pivot := arr[pivotIndex]
arr[pivotIndex], arr[right] = arr[right], arr[pivotIndex]
storeIndex := left
for i := left; i < right; i++ {
if arr[i] < pivot {
arr[storeIndex], arr[i] = arr[i], arr[storeIndex]
storeIndex++
}
}
arr[right], arr[storeIndex] = arr[storeIndex], arr[right]
return storeIndex
}
func randPivotIndex(left, right int) int {
rand.Seed(time.Now().UnixNano())
return rand.Intn(right-left+1) + left
}
func main() {
arr := []int{3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5}
fmt.Println("Before sorting:", arr)
quickSort(arr, 0, len(arr)-1)
fmt.Println("After sorting:", arr)
}
这段代码实现了一个随机化的快速排序算法,可以在最坏情况下达到O(nlgn)的时间复杂度。

360智脑:
在最坏情况下,快速排序的运行时间可能会达到O(n2)。这是因为在最坏的情况下,每次分割都会将数组分成两半,其中一半是有序的,另一半是无序的。这样,每次分割都需要进行O(n)次比较和移动操作,总共需要O(n2)次操作。
为了避免这种情况,可以使用随机化方法来打乱数组中的元素顺序,从而减小最坏情况发生的概率。在Go语言中,可以使用sort.Shuffle函数来实现随机化。具体实现如下:
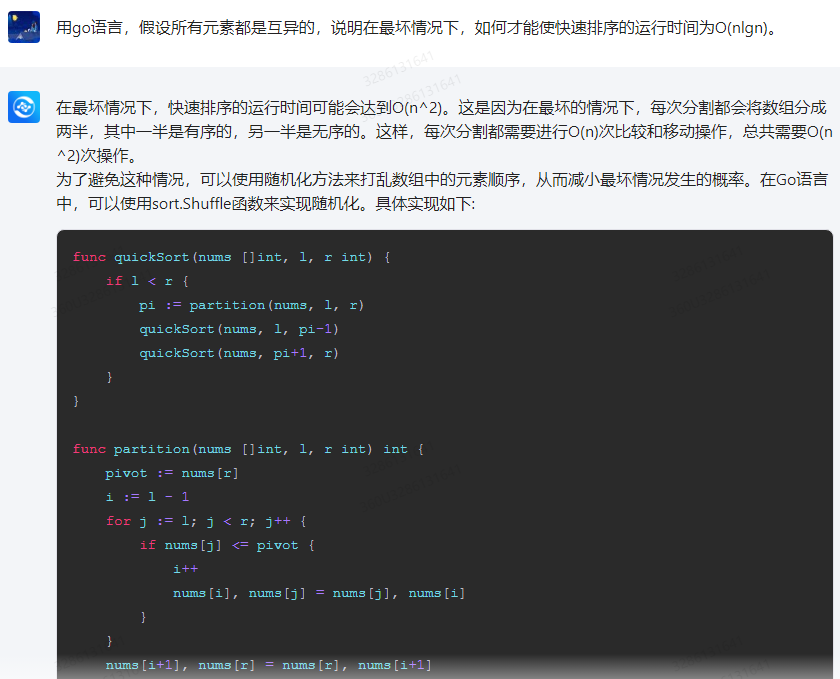
func quickSort(nums []int, l, r int) {
if l < r {
pi := partition(nums, l, r)
quickSort(nums, l, pi-1)
quickSort(nums, pi+1, r)
}
}
func partition(nums []int, l, r int) int {
pivot := nums[r]
i := l - 1
for j := l; j < r; j++ {
if nums[j] <= pivot {
i++
nums[i], nums[j] = nums[j], nums[i]
}
}
nums[i+1], nums[r] = nums[r], nums[i+1]
return i + 1
}
func sortShuffle(nums []int, r int) {
n := len(nums)
random.shuffle(nums[:r])
for i := r; i < n; i++ {
nums[i], nums[i+1] = nums[i+1], nums[i]
}
}
在sortShuffle函数中,首先使用sort.Shuffle函数打乱数组中前r个元素的顺序。然后,对于剩余的元素,按照原来的顺序进行排序。这样可以保证在最坏情况下,快速排序的运行时间仍然为O(nlogn),而不是O(n^2)。

智谱清言:
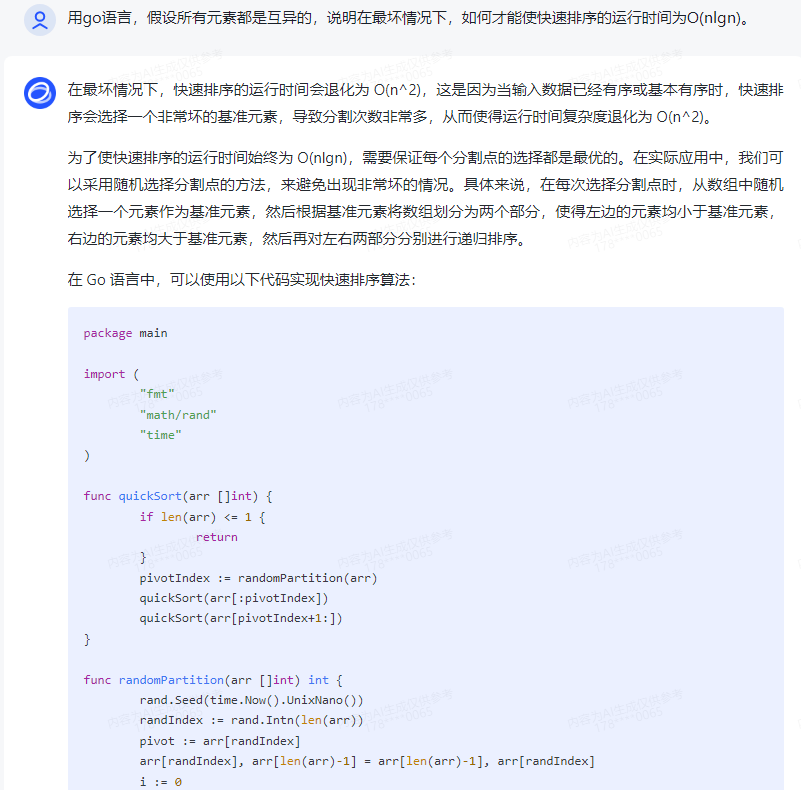
在最坏情况下,快速排序的运行时间会退化为 O(n^2),这是因为当输入数据已经有序或基本有序时,快速排序会选择一个非常坏的基准元素,导致分割次数非常多,从而使得运行时间复杂度退化为 O(n^2)。
为了使快速排序的运行时间始终为 O(nlgn),需要保证每个分割点的选择都是最优的。在实际应用中,我们可以采用随机选择分割点的方法,来避免出现非常坏的情况。具体来说,在每次选择分割点时,从数组中随机选择一个元素作为基准元素,然后根据基准元素将数组划分为两个部分,使得左边的元素均小于基准元素,右边的元素均大于基准元素,然后再对左右两部分分别进行递归排序。
在 Go 语言中,可以使用以下代码实现快速排序算法:
package main
import (
"fmt"
"math/rand"
"time"
)
func quickSort(arr []int) {
if len(arr) <= 1 {
return
}
pivotIndex := randomPartition(arr)
quickSort(arr[:pivotIndex])
quickSort(arr[pivotIndex+1:])
}
func randomPartition(arr []int) int {
rand.Seed(time.Now().UnixNano())
randIndex := rand.Intn(len(arr))
pivot := arr[randIndex]
arr[randIndex], arr[len(arr)-1] = arr[len(arr)-1], arr[randIndex]
i := 0
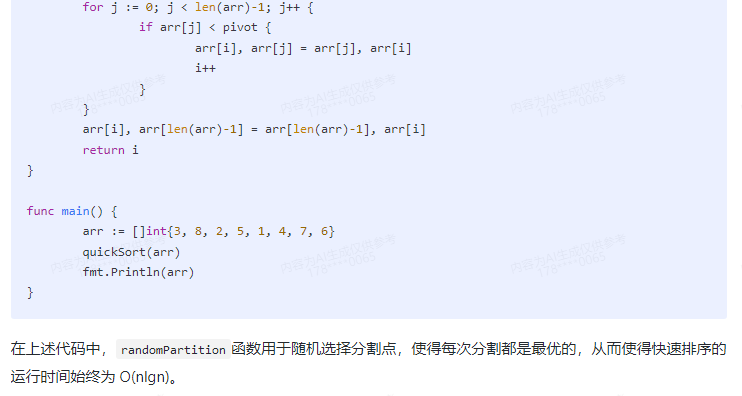
for j := 0; j < len(arr)-1; j++ {
if arr[j] < pivot {
arr[i], arr[j] = arr[j], arr[i]
i++
}
}
arr[i], arr[len(arr)-1] = arr[len(arr)-1], arr[i]
return i
}
func main() {
arr := []int{3, 8, 2, 5, 1, 4, 7, 6}
quickSort(arr)
fmt.Println(arr)
}
在上述代码中,randomPartition函数用于随机选择分割点,使得每次分割都是最优的,从而使得快速排序的运行时间始终为 O(nlgn)。
通义千问:
在最坏情况下,要使快速排序的运行时间为O(nlgn),需要满足以下条件:
1.快速排序的分割操作每次都将序列分割成两份,且分割后的两份序列的长度差为1。
2.每次分割操作选择的枢轴元素都是序列中的最大或最小元素。
如果满足以上两个条件,那么快速排序的运行时间就为O(nlgn)。具体实现方法如下:
1.每次分割操作选择序列的最后一个元素作为枢轴元素。
2.在分割操作中,将序列分成两份,一份包含所有小于枢轴元素的元素,另一份包含所有大于枢轴元素的元素。可以使用两个指针i和j,分别指向序列的第一个元素和最后一个元素,然后交换i和j所指的元素,直到i指向的元素大于枢轴元素为止。此时,i所指的元素就是枢轴元素的位置,然后将序列分成两份,一份包含所有小于枢轴元素的元素,另一份包含所有大于枢轴元素的元素。
3.递归地对小于枢轴元素的序列和大于枢轴元素的序列进行快速排序。
这种实现方法能够保证每次分割操作都将序列分成两份,且分割后的两份序列的长度差为1,因此快速排序的运行时间为O(nlgn)。

天工:
在快速排序的实现中,递归地将数组划分为两个子数组,其中一个子数组的所有元素都小于另一个子数组的所有元素。然后对这两个子数组递归地应用相同的过程,直到每个子数组只有一个元素或为空。
在最坏情况下,快速排序的运行时间为O(n2),即当数组已经有序或逆序时。在这种情况下,每次划分只能将数组划分为一个空子数组和一个包含所有元素的子数组,因此递归树的深度为n。因此,快速排序的运行时间为O(n2)。
要使快速排序的运行时间为O(nlgn),可以使用随机化选择枢轴元素的方法。具体来说,可以从数组中随机选择一个元素作为枢轴元素,而不是总是选择第一个元素。这样可以减少最坏情况发生的概率,从而使平均运行时间更接近O(nlgn)。
另外,还可以使用三数取中法来选择枢轴元素,即从数组的开头、结尾和中间位置分别选择一个元素,然后取它们的中位数作为枢轴元素。这种方法可以更好地避免最坏情况的发生。
chatgpt:
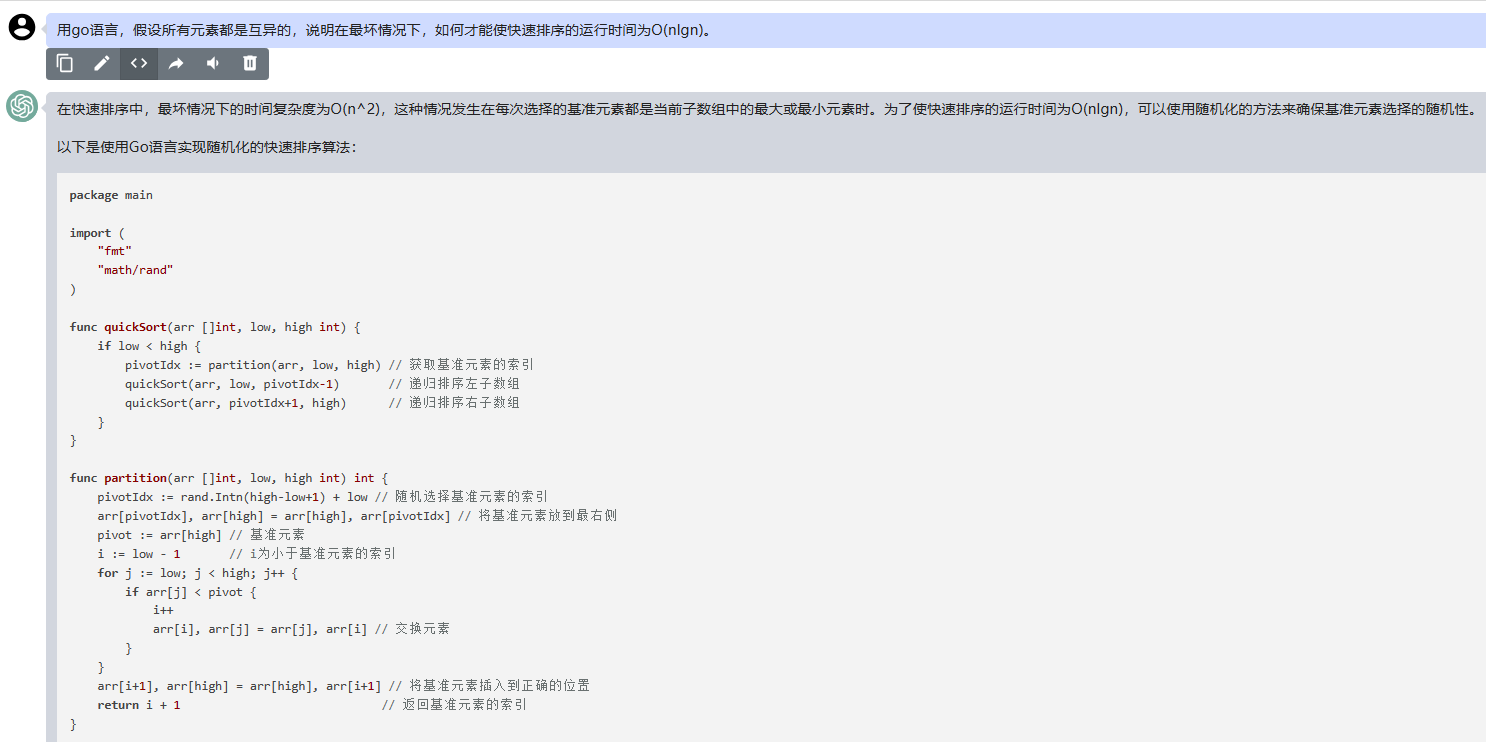
在快速排序中,最坏情况下的时间复杂度为O(n^2),这种情况发生在每次选择的基准元素都是当前子数组中的最大或最小元素时。为了使快速排序的运行时间为O(nlgn),可以使用随机化的方法来确保基准元素选择的随机性。
以下是使用Go语言实现随机化的快速排序算法:
package main
import (
"fmt"
"math/rand"
)
func quickSort(arr []int, low, high int) {
if low < high {
pivotIdx := partition(arr, low, high) // 获取基准元素的索引
quickSort(arr, low, pivotIdx-1) // 递归排序左子数组
quickSort(arr, pivotIdx+1, high) // 递归排序右子数组
}
}
func partition(arr []int, low, high int) int {
pivotIdx := rand.Intn(high-low+1) + low // 随机选择基准元素的索引
arr[pivotIdx], arr[high] = arr[high], arr[pivotIdx] // 将基准元素放到最右侧
pivot := arr[high] // 基准元素
i := low - 1 // i为小于基准元素的索引
for j := low; j < high; j++ {
if arr[j] < pivot {
i++
arr[i], arr[j] = arr[j], arr[i] // 交换元素
}
}
arr[i+1], arr[high] = arr[high], arr[i+1] // 将基准元素插入到正确的位置
return i + 1 // 返回基准元素的索引
}
func main() {
arr := []int{10, 7, 8, 9, 1, 5}
quickSort(arr, 0, len(arr)-1)
fmt.Println(arr)
}
在上述代码中,我们使用rand.Intn(high-low+1) + low来选择随机的基准元素。通过随机选择基准元素,可以避免最坏情况的发生,从而将快速排序的时间复杂度保持在O(nlgn)。

文心一言 VS 讯飞星火 VS chatgpt (97)-- 算法导论9.3 3题的更多相关文章
- 【对比】文心一言对飚ChatGPT实操对比体验
前言 缘由 百度[文心一言]体验申请通过 本狗中午干饭时,天降短信,告知可以体验文心一言,苦等一个月的实操终于到来.心中这好奇的对比心理油然而生,到底是老美的[ChatGPT]厉害,还是咱度娘的[文心 ...
- 【个人首测】百度文心一言 VS ChatGPT GPT-4
昨天我写了一篇文章GPT-4牛是牛,但这几天先别急,文中我测试了用GPT-4回答ChatGPT 3.5 和 Notion AI的问题,大家期待的图片输入也没有出现. 昨天下午百度发布了文心一言,对标C ...
- 文心一言,通营销之学,成一家之言,百度人工智能AI大数据模型文心一言Python3.10接入
"文心"取自<文心雕龙>一书的开篇,作者刘勰在书中引述了一个古代典故:春秋时期,鲁国有一位名叫孔文子的大夫,他在学问上非常有造诣,但是他的儿子却不学无术,孔文子非常痛心 ...
- 获取了文心一言的内测及与其ChatGPT、GPT-4 对比结果
百度在3月16日召开了关于文心一言(知识增强大语言模型)的发布会,但是会上并没现场展示demo.如果要测试的文心一言 也要获取邀请码,才能进行测试的. 我这边通过预约得到了邀请码,大概是在3月17日晚 ...
- 百度生成式AI产品文心一言邀你体验AI创作新奇迹:百度CEO李彦宏详细透露三大产业将会带来机遇(文末附文心一言个人用户体验测试邀请码获取方法,亲测有效)
目录 中国版ChatGPT上线发布 强大中文理解能力 智能文学创作.商业文案创作 图片.视频智能生成 中国生成式AI三大产业机会 新型云计算公司 行业模型精调公司 应用服务提供商 总结 获取文心一言邀 ...
- 阿里版ChatGPT:通义千问pk文心一言
随着 ChatGPT 热潮卷起来,百度发布了文心一言.Google 发布了 Bard,「阿里云」官方终于也宣布了,旗下的 AI 大模型"通义千问"正式开启测试! 申请地址:http ...
- 基于讯飞语音API应用开发之——离线词典构建
最近实习在做一个跟语音相关的项目,就在度娘上搜索了很多关于语音的API,顺藤摸瓜找到了科大讯飞,虽然度娘自家也有语音识别.语义理解这块,但感觉应该不是很好用,毕竟之前用过百度地图的API,有问题也找不 ...
- android用讯飞实现TTS语音合成 实现中文版
Android系统从1.6版本开始就支持TTS(Text-To-Speech),即语音合成.但是android系统默认的TTS引擎:Pic TTS不支持中文.所以我们得安装自己的TTS引擎和语音包. ...
- android讯飞语音开发常遇到的问题
场景:android项目中共使用了3个语音组件:在线语音听写.离线语音合成.离线语音识别 11208:遇到这个错误,授权应用失败,先检查装机量(3台测试权限),以及appid的申请时间(35天期限), ...
- 初探机器学习之使用讯飞TTS服务实现在线语音合成
最近在调研使用各个云平台提供的AI服务,有个语音合成的需求因此就使用了一下科大讯飞的TTS服务,也用.NET Core写了一个小示例,下面就是这个小示例及其相关背景知识的介绍. 一.什么是语音合成(T ...
随机推荐
- 资源高效搜索方法,你 Get 到了吗?
随手转发给好友和朋友圈 编辑:办公小通 百度搜索谁都会,但是搜出来的资料往往良莠不齐.搜索速度是快了,但是还要花大量的时间去筛选. 通过下面的两个最常用的栗子,小通强烈推荐大家用高级搜索. 高级 ...
- Vue——vuex使用、Router使用、localstorage、sessionstorage和cookie
vuex使用 # vuex :状态管理器--->存数据(变量)的地方,所有组件都可以操作 在Vue中实现集中式状态(数据)管理的一个Vue插件,对vue应用中多个组件的共享状态进行集中式的管理( ...
- 通过redis学网络(2)-redis网络模型
本系列主要是为了对redis的网络模型和集群原理进行学习,我会用golang实现一个reactor网络模型,并实现对redis协议的解析. 系列源码已经上传github https://github. ...
- 体验昇腾Ascend C 编程语言极简易用的算子开发
摘要:昇腾Ascend C编程语言,让基于昇腾AI的算法创新更加简单. 本文分享自华为云社区<CANN黑科技解密|昇腾Ascend C编程语言 - 极简易用的算子开发体验>,作者:昇腾CA ...
- 高效处理报表,掌握原生JS打印和导出报表为PDF的顺畅技巧!
摘要:本文由葡萄城技术团队于博客园原创并首发.转载请注明出处:葡萄城官网,葡萄城为开发者提供专业的开发工具.解决方案和服务,赋能开发者. 前言篇 在日常工作中,报表打印和导出为PDF是经常要处理的任务 ...
- Python运维开发之路《文件处理》
一.python字典操作 1.字典的定义 字典一种key-value的数据类型,类似于json串. 2.字典的特性 key:value 字典不可变,key唯一 key的定义规则: 1.不可变,数字.字 ...
- 选择排序与冒泡排序(c语言+Java语言)
选择排序 O(n2) 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置. 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾. 重复第二步,直到所有元素均排序完毕. 例 ...
- Python 引用问题 - ImportError: attempted relative import with no known parent package
问题描述 近日在尝试引用其他文件的代码时,遇到了错误: ImportError: attempted relative import with no known parent package. 问题大 ...
- 4.7 x64dbg 应用层的钩子扫描
所谓的应用层钩子(Application-level hooks)是一种编程技术,它允许应用程序通过在特定事件发生时执行特定代码来自定义或扩展其行为.这些事件可以是用户交互,系统事件,或者其他应用程序 ...
- 【Mybatis】动态SQL
目录 动态SQL if语句 动态SQL if+where语句 动态SQL if+set语句 动态SQL choose(when,otherwise)语句 动态SQL trim语句 动态SQL SQL片 ...