ElasticSearch系列——查询、Python使用、Django/Flask集成、集群搭建,数据分片、位置坐标实现附近的人搜索
@
Elasticsearch之-查询
查询分类:
基本查询:使用es内置查询条件进行查询
组合查询:把多个查询组合在一起进行复合查询
过滤:查询的同时,通过filter条件在不影响打分的情况下筛选数据
一 基本查询
#添加映射
PUT lago
{
"mappings": {
"properties":{
"title":{
"stort":true,
"type":"text",
"analyzer":"ik_max_word"
},
"company_name":{
"stort":true,
"type":"keyword",
},
"desc":{
"type":"text"
},
"comments":{
"type":"integer"
},
"add_time":{
"type":"date",
"format":"yyy-MM-dd"
}
}
}
}
#测试数据
POST lago/job
{
"title":"python django 开发工程师",
"company_name":"美团科技有限公司",
"desc":"对django熟悉,掌握mysql和非关系型数据库,网站开发",
"comments:200,
"add_time":"2018-4-1"
}
POST lago/job
{
"title":"python数据分析",
"company_name":"百度科技有限公司",
"desc":"熟悉python基础语法,熟悉数据分析",
"comments:5,
"add_time":"2018-10-1"
}
POST lago/job
{
"title":"python自动化运维",
"company_name":"上海华为",
"desc":"熟悉python基础语法,精通Linux",
"comments:90,
"add_time":"2019-9-18"
}
1.1 match查询
GET lagou/job/_search
{
"query":{
"match":{
"title":"python"
}
}
}
#因为title字段做了分词,python都能搜索出来
#搜索python网站也能搜索出来,把python和网站分成两个词
#搜索爬取也能搜索到,把爬和取分词,去搜索
#只搜取 搜不到
1.2 term查询
GET lagou/_search
{
"query":{
"term":{
"title":"python"
}
}
}
#会拿着要查询的词不做任何处理,直接查询
#用python爬虫,查不到,用match就能查到
{
"query":{
"term":{
"company_name":"美团"
}
}
}
#通过美团,就查询不到
1.3 terms查询
GET lagou/_search
{
"query":{
"terms":{
"title":["工程师","django","运维"]
}
}
}
#三个词,只要有一个,就会查询出来
1.4 控制查询的返回数量(分页)
GET lagou/_search
{
"query":{
"match":{
"title":"python"
}
},
"form":1,
"size":2
}
#从第一条开始,大小为2
1.5 match_all 查询
GET lagou/_search
{
"query":{
"match_all":{}
}
}
#所有数据都返回
1.6 match_phrase查询
GET lagou/_search
{
"query":{
"match_phrase":{
"title":{
"query":"python系统",
"slop":6
}
}
}
}
#短语查询,
#会把查询条件python和系统分词,放到列表中,再去搜索的时候,必须满足python和系统同时存在的才能搜出来
#"slop":6 :python和系统这两个词之间最小的距离
1.7 multi_match
GET lagou/_search
{
"query":{
"multy_match":{
"query":"python",
"fields":["title","desc"]
}
}
}
#可以指定多个字段
#比如查询title和desc这个两个字段中包含python关键词的文档
#"fields":["title^3","desc"]:权重,title中的python是desc中的三倍
1.8 指定返回的字段
GET lagou/_search
{
"query":{
"stored_fields":["title","company_name"]
"match":{
"title":"python"
}
}
}
#只返回title和company_name字段
#"stored_fields":["title","company_name",'dsc'],不会返回dsc,因为我们要求stroed_fields,之前desc字段设为false(默认),不会显示
1.9 sort 结果排序
GET lagou/_search
{
"query":{
"match_all":{}
},
"sort":[
{
"comments":{
"order":"desc"
}
}
]
}
#查询所有文档,按comments按desc降序排序
1.10 range范围查询
GET lagou/_search
{
"query":{
"range":{
"comments":{
"gte":10,
"lte":20,
"boost":2.0
}
}
}
}
#指定comments字段大于等于10,小于等于20
#boost:权重
GET lagou/_search
{
"query":{
"range":{
"add_time":{
"gte":"2019-10-11",
"lte":"now",
}
}
}
}
#对时间进行查询
1.11 wildcard查询
GET lagou/_search
{
"query":{
"wildcard":{
"title":{
"value":"pyth*n",
"boost":2.0
}
}
}
}
#模糊查询,title中,有pyth任意值n得都能查出来
二 组合查询
2.1 bool查询
#bool查询包括must should must_not filter
'''
bool:{
"filter":[], 字段过滤
"must":[], 所有查询条件都满足
"should":[], 满足一个或多个
"must_not":{} 都不满足于must相反
}
'''
# 建立测试数据
POST lago/testjob/_bulk
{"index":{"_id":1}}
{"salary":10,"title":"Python"}
{"index":{"_id":2}}
{"salary":20,"title":"Scrapy"}
{"index":{"_id":3}}
{"salary":30,"title":"Django"}
{"index":{"_id":4}}
{"salary":30,"title":"Elasticsearch"}
2.2 简单过滤查询
#select * from testjob where salary=20
GET lagou/testjob/_search
{
"query":{
"bool":{
"must":{
"match_all":{}
},
"filter":{
"term":{
"salary":20
}
}
}
}
}
1.3 查询多个值
#查询薪资是10k或20k的
GET lagou/testjob/_search
{
"query":{
"bool":{
"must":{
"match_all":{}
},
"filter":{
"terms":{
"salary":[10,20]
}
}
}
}
}
#select * from testjob where title="python"
GET lagou/testjob/_search
{
"query":{
"bool":{
"must":{
"match_all":{}
},
"filter":{
"term":{
"title":"Python"
}
}
}
}
}
#title 是text字段,会做大小写转换,term不会预处理,拿着大写Python去查查不到
#可以改成小写,或者用match来查询
'''
"filter":{
"match":{
"title":"Python"
}
}
'''
#查看分析器解析结果
GET _analyze
{
"analyzer":"ik_max_word",
"text":"python网络开发工程师"
}
1.4 bool过滤查询,可以做组合过滤查询
#select * from testjob where (salary=20 or title=Python) and (salary!=30)
#查询薪资等于20k或者工作为python的工作,排除价格为30k的
{
"query":{
"bool":{
"should":[
{"term":{"salary":20}},
{"term":{"title":"python"}}
],
"must_not":{
"term":{"salary":30}
}
}
}
}
#select * from testjob where title=python or (title=django and salary=30)
{
"query":{
"bool":{
"should":[
{"term":{"title":"python"}},
{
"bool":{
"must":[
{"term":{"title":"django"}},
{"term":{"salary":30}}
]
}
}
]
}
}
}
Elasticsearch之-Python使用
from elasticsearch import Elasticsearch
obj = Elasticsearch()
# 创建索引(Index)
result = obj.indices.create(index='user', body={"userid":'1','username':'lqz'},ignore=400)
# print(result)
# 删除索引
# result = obj.indices.delete(index='user', ignore=[400, 404])
# 插入数据
# data = {'userid': '1', 'username': 'lqz','password':'123'}
# result = obj.create(index='news', doc_type='politics', id=1, body=data)
# print(result)
# 更新数据
'''
不用doc包裹会报错
ActionRequestValidationException[Validation Failed: 1: script or doc is missing
'''
# data ={'doc':{'userid': '1', 'username': 'lqz','password':'123ee','test':'test'}}
# result = obj.update(index='news', doc_type='politics', body=data, id=1)
# print(result)
# 删除数据
# result = obj.delete(index='news', doc_type='politics', id=1)
# 查询
# 查找所有文档
query = {'query': {'match_all': {}}}
# 查找名字叫做jack的所有文档
# query = {'query': {'term': {'username': 'lqz'}}}
# 查找年龄大于11的所有文档
# query = {'query': {'range': {'age': {'gt': 11}}}}
allDoc = obj.search(index='news', doc_type='politics', body=query)
print(allDoc['hits']['hits'][0]['_source'])
Elasticsearch之-Django/Flask集成
一 elasticsearch-dsl
#安装: pip3 install elasticsearch-dsl
#示例
from datetime import datetime
from elasticsearch_dsl import Document, Date, Nested, Boolean, \
analyzer, InnerDoc, Completion, Keyword, Text
html_strip = analyzer('html_strip',
tokenizer="standard",
filter=["standard", "lowercase", "stop", "snowball"],
char_filter=["html_strip"]
)
class Comment(InnerDoc):
author = Text(fields={'raw': Keyword()})
content = Text(analyzer='snowball')
created_at = Date()
def age(self):
return datetime.now() - self.created_at
class Post(Document):
title = Text()
title_suggest = Completion()
created_at = Date()
published = Boolean()
category = Text(
analyzer=html_strip,
fields={'raw': Keyword()}
)
comments = Nested(Comment)
class Index:
name = 'blog'
def add_comment(self, author, content):
self.comments.append(
Comment(author=author, content=content, created_at=datetime.now()))
def save(self, ** kwargs):
self.created_at = datetime.now()
return super().save(** kwargs)
二 django集成
from datetime import datetime
from elasticsearch_dsl import Document, Date, Nested, Boolean,analyzer, InnerDoc, Completion, Keyword, Text,Integer
from elasticsearch_dsl.connections import connections
connections.create_connection(hosts=["localhost"])
class Article(Document):
title = Text(analyzer='ik_max_word', search_analyzer="ik_max_word", fields={'title': Keyword()})
author = Text()
class Index:
name = 'myindex'
def save(self, ** kwargs):
return super(Article, self).save(** kwargs)
if __name__ == '__main__':
# Article.init() # 创建映射
# 保存数据
# article = Article()
# article.title = "测试测试"
# article.save() # 数据就保存了
#查询数据
# s=Article.search()
# s = s.filter('match', title="测试")
#
# results = s.execute()
# print(results)
#删除数据
# s = Article.search()
# s = s.filter('match', title="测试").delete()
#修改数据
# s = Article().search()
# s = s.filter('match', title="测试")
# results = s.execute()
# print(results[0])
# results[0].title="xxx"
# results[0].save()
Elasticsearch高级之-集群搭建,数据分片
es使用两种不同的方式来发现对方:
- 广播
- 单播
也可以同时使用两者,但默认的广播,单播需要已知节点列表来完成
一 广播方式
当es实例启动的时候,它发送了广播的ping请求到地址224.2.2.4:54328。而其他的es实例使用同样的集群名称响应了这个请求。
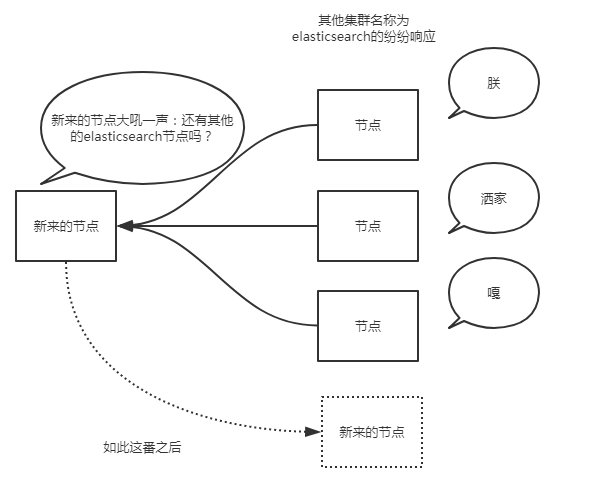
一般这个默认的集群名称就是上面的cluster_name对应的elasticsearch。通常而言,广播是个很好地方式。想象一下,广播发现就像你大吼一声:别说话了,再说话我就发红包了!然后所有听见的纷纷响应你。
但是,广播也有不好之处,过程不可控。
#1 在本地单独的目录中,再复制一份elasticsearch文件
# 2 分别启动bin目录中的启动文件
# 3 在浏览器里输入:http://127.0.0.1:9200/_cluster/health?pretty
-通过number_of_nodes可以看到,目前集群中已经有了两个节点了
二 单播方式
当节点的ip(想象一下我们的ip地址是不是一直在变)不经常变化的时候,或者es只连接特定的节点。单播发现是个很理想的模式。使用单播时,我们告诉es集群其他节点的ip及(可选的)端口及端口范围。我们在elasticsearch.yml配置文件中设置:
discovery.zen.ping.unicast.hosts: ["10.0.0.1", "10.0.0.3:9300", "10.0.0.6[9300-9400]"]
大家就像交换微信名片一样,相互传传就加群了.....
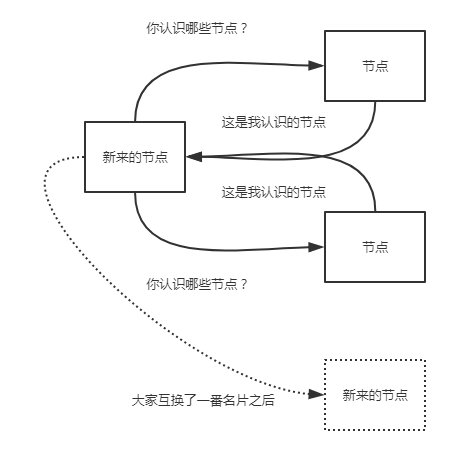
一般的,我们没必要关闭单播发现,如果你需要广播发现的话,配置文件中的列表保持空白即可。
#现在,我们为这个集群增加一些单播配置,打开各节点内的\config\elasticsearch.yml文件。每个节点的配置如下(原配置文件都被注释了,可以理解为空,我写好各节点的配置,直接粘贴进去,没有动注释的,出现问题了好恢复):
#1 elasticsearch1节点,,集群名称是my_es1,集群端口是9300;节点名称是node1,监听本地9200端口,可以有权限成为主节点和读写磁盘(不写就是默认的)。
cluster.name: my_es1
node.name: node1
network.host: 127.0.0.1
http.port: 9200
transport.tcp.port: 9300
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
# 2 elasticsearch2节点,集群名称是my_es1,集群端口是9302;节点名称是node2,监听本地9202端口,可以有权限成为主节点和读写磁盘。
cluster.name: my_es1
node.name: node2
network.host: 127.0.0.1
http.port: 9202
transport.tcp.port: 9302
node.master: true
node.data: true
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
# 3 elasticsearch3节点,集群名称是my_es1,集群端口是9303;节点名称是node3,监听本地9203端口,可以有权限成为主节点和读写磁盘。
cluster.name: my_es1
node.name: node3
network.host: 127.0.0.1
http.port: 9203
transport.tcp.port: 9303
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
# 4 elasticsearch4节点,集群名称是my_es1,集群端口是9304;节点名称是node4,监听本地9204端口,仅能读写磁盘而不能被选举为主节点。
cluster.name: my_es1
node.name: node4
network.host: 127.0.0.1
http.port: 9204
transport.tcp.port: 9304
node.master: false
node.data: true
discovery.zen.ping.unicast.hosts: ["127.0.0.1:9300", "127.0.0.1:9302", "127.0.0.1:9303", "127.0.0.1:9304"]
由上例的配置可以看到,各节点有一个共同的名字my_es1,但由于是本地环境,所以各节点的名字不能一致,我们分别启动它们,它们通过单播列表相互介绍,发现彼此,然后组成一个my_es1集群。谁是老大则是要看谁先启动了!
三 选取主节点
无论是广播发现还是到单播发现,一旦集群中的节点发生变化,它们就会协商谁将成为主节点,elasticsearch认为所有节点都有资格成为主节点。如果集群中只有一个节点,那么该节点首先会等一段时间,如果还是没有发现其他节点,就会任命自己为主节点。
对于节点数较少的集群,我们可以设置主节点的最小数量,虽然这么设置看上去集群可以拥有多个主节点。实际上这么设置是告诉集群有多少个节点有资格成为主节点。怎么设置呢?修改配置文件中的:
discovery.zen.minimum_master_nodes: 3
一般的规则是集群节点数除以2(向下取整)再加一。比如3个节点集群要设置为2。这么着是为了防止脑裂(split brain)问题。
四 什么是脑裂
脑裂这个词描述的是这样的一个场景:(通常是在重负荷或网络存在问题时)elasticsearch集群中一个或者多个节点失去和主节点的通信,然后各节点就开始选举新的主节点,继续处理请求。这个时候,可能有两个不同的集群在相互运行着,这就是脑裂一词的由来,因为单一集群被分成了两部分。为了防止这种情况的发生,我们就需要设置集群节点的总数,规则就是节点总数除以2再加一(半数以上)。这样,当一个或者多个节点失去通信,小老弟们就无法选举出新的主节点来形成新的集群。因为这些小老弟们无法满足设置的规则数量。
我们通过下图来说明如何防止脑裂。比如现在,有这样一个5个节点的集群,并且都有资格成为主节点:
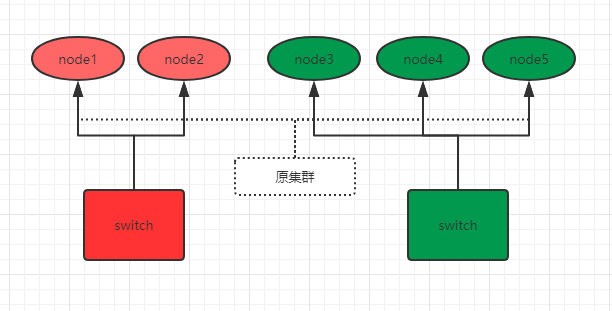
为了防止脑裂,我们对该集群设置参数:
discovery.zen.minimum_master_nodes: 3 # 3=5/2+1
之前原集群的主节点是node1,由于网络和负荷等原因,原集群被分为了两个switch:node1 、2和node3、4、5。因为minimum_master_nodes参数是3,所以node3、4、5可以组成集群,并且选举出了主节点node3。而node1、2节点因为不满足minimum_master_nodes条件而无法选举,只能一直寻求加入集群(还记得单播列表吗?),要么网络和负荷恢复正常后加入node3、4、5组成的集群中,要么就是一直处于寻找集群状态,这样就防止了集群的脑裂问题。
除了设置minimum_master_nodes参数,有时候还需要设置node_master参数,比如有两个节点的集群,如果出现脑裂问题,那么它们自己都无法选举,因为都不符合半数以上。这时我们可以指定node_master,让其中一个节点有资格成为主节点,另外一个节点只能做存储用。当然这是特殊情况。
那么,主节点是如何知道某个节点还活着呢?这就要说到错误识别了。
五 错误识别
其实错误识别,就是当主节点被确定后,建立起内部的ping机制来确保每个节点在集群中保持活跃和健康,这就是错误识别。
主节点ping集群中的其他节点,而且每个节点也会ping主节点来确认主节点还活着,如果没有响应,则宣布该节点失联。想象一下,老大要时不常的看看(循环)小弟们是否还活着,而小老弟们也要时不常的看看老大还在不在,不在了就赶紧再选举一个出来!
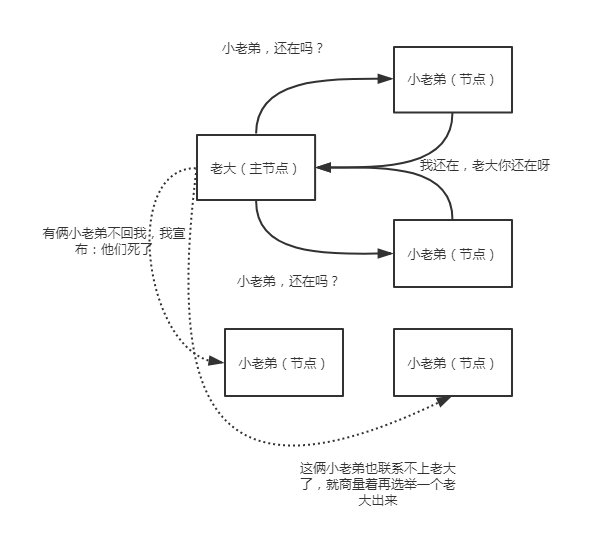
但是,怎么看?多久没联系算是失联?这些细节都是可以设置的,不是一拍脑门子,就说某个小老弟挂了!在配置文件中,可以设置:
discovery.zen.fd.ping_interval: 1
discovery.zen.fd.ping_timeout: 30
discovery_zen.fd.ping_retries: 3
每个节点每隔discovery.zen.fd.ping_interval的时间(默认1秒)发送一个ping请求,等待discovery.zen.fd.ping_timeout的时间(默认30秒),并尝试最多discovery.zen.fd.ping_retries次(默认3次),无果的话,宣布节点失联,并且在需要的时候进行新的分片和主节点选举。
根据开发环境,适当修改这些值。
Elasticsearch高级之-位置坐标实现附近的人搜索
一 创建mapping
PUT test
{
"mappings": {
"test":{
"properties": {
"location":{
"type": "geo_point"
}
}
}
}
}
二 导入数据
POST test/test
{
"location":{
"lat":12,
"lon":24
}
}
三 查询
3.1根据给定两个点组成的矩形,查询矩形内的点
GET test/test/_search
{
"query": {
"geo_bounding_box": {
"location": {
"top_left": {
"lat": 28,
"lon": 10
},
"bottom_right": {
"lat": 10,
"lon": 30
}
}
}
}
}
3.2根据给定的多个点组成的多边形,查询范围内的点
GET test/test/_search
{
"query": {
"geo_polygon": {
"location": {
"points": [
{
"lat": 11,
"lon": 25
},
{
"lat": 13,
"lon": 25
},
{
"lat": 13,
"lon": 23
},
{
"lat": 11,
"lon": 23
}
]
}
}
}
}
3.3查询给定1000KM距离范围内的点
GET test/test/_search
{
"query": {
"geo_distance": {
"distance": "1000km",
"location": {
"lat": 12,
"lon": 23
}
}
}
}
3.4查询距离范围区间内的点的数量
GET test/test/_search
{
"size": 0,
"aggs": {
"myaggs": {
"geo_distance": {
"field": "location",
"origin": {
"lat": 52.376,
"lon": 4.894
},
"unit": "km",
"ranges": [
{
"from": 50,
"to": 30000
}
]
}
}
}
}
ElasticSearch系列——查询、Python使用、Django/Flask集成、集群搭建,数据分片、位置坐标实现附近的人搜索的更多相关文章
- springCloud系列教程01:Eureka 注册中心集群搭建
springCloud系列教程包含如下内容: springCloud系列教程01:Eureka 注册中心集群搭建 springCloud系列教程02:ConfigServer 配置中心server搭建 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- kafka系列一:单节点伪分布式集群搭建
Kafka集群搭建分为单节点的伪分布式集群和多节点的分布式集群两种,首先来看一下单节点伪分布式集群安装.单节点伪分布式集群是指集群由一台ZooKeeper服务器和一台Kafka broker服务器组成 ...
- Kubernetes 系列(一):本地k8s集群搭建
我们需要做以下工作: (1)安装VMware,运行CentOs系统,一个做master,一个做node. (2)安装K8s. (3)安装docker和部分镜像会需要访问外网,所以你需要做些网络方面的准 ...
- Elasticsearch集群搭建及使用Java客户端对数据存储和查询
本次博文发两块,前部分是怎样搭建一个Elastic集群,后半部分是基于Java对数据进行写入和聚合统计. 一.Elastic集群搭建 1. 环境准备. 该集群环境基于VMware虚拟机.CentOS ...
- 和我一起打造个简单搜索之ElasticSearch集群搭建
我们所常见的电商搜索如京东,搜索页面都会提供各种各样的筛选条件,比如品牌.尺寸.适用季节.价格区间等,同时提供排序,比如价格排序,信誉排序,销量排序等,方便了用户去找到自己心里理想的商品. 站内搜索对 ...
- elasticsearch系列八:ES 集群管理(集群规划、集群搭建、集群管理)
一.集群规划 搭建一个集群我们需要考虑如下几个问题: 1. 我们需要多大规模的集群? 2. 集群中的节点角色如何分配? 3. 如何避免脑裂问题? 4. 索引应该设置多少个分片? 5. 分片应该设置几个 ...
- ElasticSearch的基本用法与集群搭建
一.简介 ElasticSearch和Solr都是基于Lucene的搜索引擎,不过ElasticSearch天生支持分布式,而Solr是4.0版本后的SolrCloud才是分布式版本,Solr的分布式 ...
- Elasticsearch集群搭建
现有两部机器:192.168.31.86,192.168.31.87 参考以往博文对Elasticsearch进行配置完成:http://www.cnblogs.com/zhongshengzhe ...
- ElasticSearch入门(1) —— 集群搭建
一.环境介绍与安装准备 1.环境说明 2台虚拟机,OS为ubuntu13.04,ip分别为xxx.xxx.xxx.140和xxx.xxx.xxx.145. 2.安装准备 ElasticSearch(简 ...
随机推荐
- 自动化SQL注入工具——Sqlmap
Sqlmap – 简介 Sqlmap是一个自动化检测和利用SQL注入漏洞的免费开源工具 1.支持对多种数据库进行注入测试,能够自动识别数据库类型并注入 2.支持多种注入技术,并且能够自动探测使用合适的 ...
- kubernetes(k8s):解决不在同一网段加入集群失败问题
执行下面命令,将内外网进行映射. iptables -t nat -A OUTPUT -d 10.140.128.121 -j DNAT --to-destination 10.170.129.153 ...
- 深入JS——理解闭包可以看作是某种意义上的重生
JS中有一个非常重要但又难以完全掌握的概念,那就是闭包.很多JS程序员自以为已经掌握了闭包,但实质上是一知半解,就像"JS中万物皆为对象"这个常见的错误说法一样,很多前端开发者到现 ...
- 【Springboot】拦截器
Springboot 拦截器 1.什么是拦截器? 拦截器可以根据 URL 对请求进行拦截,主要应用于登陆校验.权限验证.乱码解决.性能监控和异常处理等功能. 2.定义拦截器步骤 在 Spring Bo ...
- 关于 Task 简单梳理
〇.前言 Task 是微软在 .Net 4.0 时代推出来的,也是微软极力推荐的一种多线程的处理方式. 在 Task 之前有一个高效多线程操作累 ThreadPool,虽然线程池相对于 Thread, ...
- .NET Core中关于阿拉伯语环境下的坑:Input string was not in a correct format.
结论 .NET Core项目(.NET Framework没出现)在阿拉伯语(即语言名称是ar-开头的语言)环境下,将负数字符串转成数字,即int.Parse("-1")或Conv ...
- 【go语言】1.2.1 Go 环境安装
Go 语言的安装过程非常简单,无论你使用的是哪种操作系统,都可以按照下面的步骤来进行. Windows 系统 前往 Go 语言的官方下载页面:https://golang.org/dl/ 根据你的操作 ...
- 【JMeter】JMeter添加插件
JMeter添加插件 目录 JMeter添加插件 一.前言 二.插件管理器 三.推荐插件 1.Custom Thread Groups (1)Ultmate Thread Group (2)Stepp ...
- C# 多线程访问之 SemaphoreSlim(信号量)【进阶篇】
SemaphoreSlim 是对可同时访问某一共享资源或资源池的线程数加以限制的 Semaphore 的轻量替代,也可在等待时间预计很短的情况下用于在单个进程内等待. 由于 SemaphoreSlim ...
- [gin]基于切片实现crud
前言 代码参考自<Building Distributed Application in Gin> 需求:设计一个食谱相关的API,数据存放到切片中. 设计模型和API 模型 type R ...