Scrapy官方文档爬取
最近想爬点啥东西看看,
所以接着学习了一点Scrapy,
学习过程中就试着去爬取Scrapy的官方文档作为练习之用,
现在已经基本完成了。
实现原理:
以 overview.html 为起点,通过 response.selector.xpath 获取到 next page路径下载到本地。
最终的结果是下载了一份完成的Scrapy的官方离线文档,
因为页面之间采用的是相对路径。
完整代码如下:
import scrapy,os class ScrapyDocSpider(scrapy.Spider):
name = "scrapy_doc"
urls = []
inited = False def start_requests(self):
if not os.path.exists(self.name):
os.makedirs(self.name)
self.rootPage = ""
yield scrapy.Request(url="https://doc.scrapy.org/en/1.5/intro/overview.html", callback=self.parse) def parse(self, response):
self.log("LOADED:"+response.url)
last_index = len(response.url) - response.url[::-1].index("/")
self.rootPage = response.url[:last_index]
page = response.url.split("/")[-1]
filename = self.name+"/"+page
# self.log("parseSubPage:"+filename)
with open(filename, "wb") as f:
f.write(response.body)
f.close()
self.log("Save file %s" % filename) pages = response.selector.xpath('//div/section/div/div/footer/div/a[@rel="next"]/@href').extract()
if len(pages) != 0 :
next_page = str(pages[0])
self.log("ROOT PAGE")
self.log(self.rootPage)
self.log(next_page)
self.log(type(next_page))
if next_page.startswith(".") or next_page.startswith("/") :
next_page = self.rootPage+next_page
yield response.follow(url=next_page,callback=self.parse,errback=self.errcallback) def errcallback(self, failure):
self.logger.error(failure)
爬取到的结果如下:
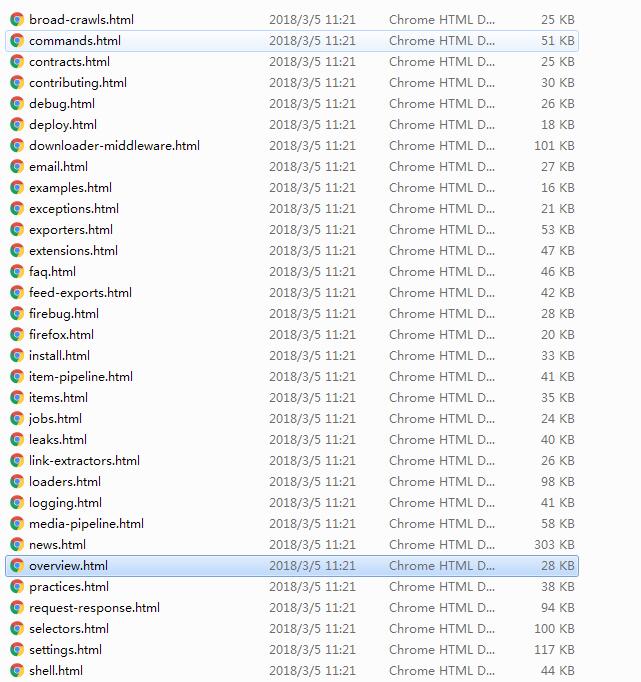
Scrapy官方文档爬取的更多相关文章
- Python3 Scrapy + Selenium + 阿布云爬取拉钩网学习笔记
1 需求分析 想要一个能爬取拉钩网职位详情页的爬虫,来获取详情页内的公司名称.职位名称.薪资待遇.学历要求.岗位需求等信息.该爬虫能够通过配置搜索职位关键字和搜索城市来爬取不同城市的不同职位详情信息, ...
- scrapy spider官方文档
Spiders Spider类定义了如何爬取某个(或某些)网站.包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item). 换句话说,Spider就是您定义爬取的动作 ...
- Hui之Hui.js 官方文档
基础 // 判断值是否是指定数据类型 var result = hui.isTargetType("百签软件", "string"); //=>true ...
- Spark Streaming官方文档学习--上
官方文档地址:http://spark.apache.org/docs/latest/streaming-programming-guide.html Spark Streaming是spark ap ...
- TestNG官方文档中文版(2)-annotation(转)
1. 介绍 TestNG是一个设计用来简化广泛的测试需求的测试框架,从单元测试(隔离测试一个类)到集成测试(测试由有多个类多个包甚至多个外部框架组成的整个系统,例如运用服务器). 编写一个测试的 ...
- OpenGL ES着色器语言之操作数(官方文档第五章)
OpenGL ES着色器语言之操作数(官方文档第五章) 5.1操作数 OpenGL ES着色器语言包含如下操作符. 5.2数组下标 数组元素通过数组下标操作符([ ])进行访问.这是操作数组的唯一操作 ...
- OpenGL ES着色器语言之变量和数据类型(一)(官方文档第四章)和varying,uniform,attribute修饰范围
OpenGL ES着色器语言之变量和数据类型(一)(官方文档第四章) 所有变量和函数在使用前必须声明.变量和函数名是标识符. 没有默认类型,所有变量和函数声明必须包含一个声明类型以及可选的修饰符. ...
- Spring Cloud官方文档中文版-Spring Cloud Config(上)
官方文档地址为:http://cloud.spring.io/spring-cloud-static/Dalston.SR2/#spring-cloud-feign 文中例子我做了一些测试在:http ...
- cassandra 3.x官方文档(5)---探测器
写在前面 cassandra3.x官方文档的非官方翻译.翻译内容水平全依赖本人英文水平和对cassandra的理解.所以强烈建议阅读英文版cassandra 3.x 官方文档.此文档一半是翻译,一半是 ...
- cassandra 3.x官方文档(7)---内部原理之如何读写数据
写在前面 cassandra3.x官方文档的非官方翻译.翻译内容水平全依赖本人英文水平和对cassandra的理解.所以强烈建议阅读英文版cassandra 3.x 官方文档.此文档一半是翻译,一半是 ...
随机推荐
- 魔力屏障 (magic) 题解
魔力屏障 (magic) [问题描述] 小 Z 生活在神奇的魔法大陆上.今天他的魔法老师给了它这样一个法阵作为它 的期末考试题目: 法阵由从左至右 n 道魔力屏障组成,每道屏障有一个临界值 a,如果它 ...
- k8s实战案例之部署Nginx+Tomcat+NFS实现动静分离
1.基于镜像分层构建及自定义镜像运行Nginx及Java服务并基于NFS实现动静分离 1.1.业务镜像设计规划 根据业务的不同,我们可以导入官方基础镜像,在官方基础镜像的基础上自定义需要用的工具和环境 ...
- 使用CNI网络插件(calico)实现docker容器跨主机互联
目录 一.系统环境 二.前言 三.CNI网络插件简介 四.常见的几种CNI网络插件对比 五.Calico网络之间是如何通信的 六.配置calico让物理机A上的docker容器c1可以访问物理机B上的 ...
- Leecode SQL
618 学生地理信息报告 一所学校有来自亚洲.欧洲和美洲的学生.写一个查询语句实现对大洲(continent) 列的透视表操作,使得每个学生按照姓名的字母顺序依次排列在对应的大洲下面.输出的标题应依次 ...
- RocketMq5.0 任意延迟时间 TimerMessageStore 源码解析
TimerMessageStore 简略介绍 延迟队列 rmq_sys_wheel_timer 指定时间的延迟消息.会先投递到 rmq_sys_wheel_timer 队列中 然后由 TimerMes ...
- clickhouse使用入门
转载请注明出处(- ̄▽ ̄)-严禁用于商业目的的转载- 导语:同学,你也不想你根本不懂ClickHouse,却赶鸭子上架使用的事情被其他人知道吧? 写在前面:本文旨在让原先有一定SQL基础的人快速简单了 ...
- Java版人脸跟踪三部曲之二:开发设计
如何开发Java版人脸跟踪应用?本篇给出了设计大纲,并解释了相关的重要知识点 欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599 ...
- 软件设计 day1
Software Design Methodology 软件设计方法学 中国石油大学(华东)2022-2023-3 国际周课程 Advanced software design 张晓东老师邀请在日本广 ...
- Idea报错:无法创建java虚拟机
报错如下: 我怀疑是在配置algo4环境时,将系统变量改变了 于是我又重新配置了一下环境变量 然后运行 cmd 执行 java -version 还是报错 <JAVA_HOME>/lib/ ...
- Linux下Oracle单实例配置多监听
Oracle单实例配置多监听 一.前言 有时候我们项目中需要使用Oracle数据库,同时要需要不同的数据源,而Oracle不像Mysql那样直接建个库即可,Oracle是以账号为单位,可以理解为一个账 ...