02 elasticsearch学习笔记-ES核心概念
一. 前序
sh
Elasticsearch是一个基于Apache Lucene(TM)的开源搜索引擎。无论在开源还是专有领域,Lucene
可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
但是,Lucene只是一个库。想要 使用它,你必须使用Java来作为开发语言并将其直接集成到你的
应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目
的是通过简单的 RESTful API 来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch的中文网址:https://www.elastic.co/cn/products/elasticsearch
1.1 正向索引和倒排索引
正向索引与倒排索引,这是在搜索领域中非常重要的两个名词,正向索引通常用于数据库中,在搜
索引擎领域使用的最多的就是倒排索引,我们根据如下两个网页来对这两个概念进行阐述:
html1
我爱我的祖国,我爱编程
html2
我爱编程,我是个快乐的小码农
1.1.1 正向索引
假设我们使用mysql的全文检索,会对如上两句话分别进行分词处理,那么预计得到的结果如下:
我 爱 爱我 祖国 我的祖国 编程 爱编程 我爱编程
我 我爱 爱 编程 爱编程 我爱编程 快乐 码农 小码农
假设我们现在使用正向索引搜索 编程 这个词,那么会到第一句话中去查找是否包含有 编程 这
个关键词,如果有则加入到结果集中;第二句话也是如此。假设现在有成千上百个网页,每个网页
非常非常的分词,那么搜索的效率将会非常非常低些。
1.1.2 倒排索引
倒排索引是按照分词与文档进行映射,我们来看看如果按照倒排索引的效果:
| 姓名 | 工作 |
|---|---|
| 我 | html1,html2,html3 |
| 爱 | html1,html2 |
| 爱我 | html1 |
| 我爱 | html2 |
| 祖国 | html1 |
| 我的祖国 | html1 |
| 编程 | html1,html2 |
| 我爱编程 | html1,html2 |
| 爱编程 | html1,html2 |
| 快乐 | html2 |
| 码农 | html2 |
| 小码农 | html2 |
如果采用倒排索引的方式搜索 编程 这个词,那么会直接找到关键词中查找到 编程 ,然后查找
到对应的文档,这就是所谓的倒排索引
二. 软件简介以及启动
https://www.cnblogs.com/haima/p/14225596.html
三. Elasticsearch的基本概念
ES核心概念
- 索引(index)
- 字段类型(type)
- 文档(documents)
概述
在前面学习中,我们已经掌握了es是什么,同时也把es服务已经安装启动,那es是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?我们先来聊聊es的相关概念
集群,节点,索引,类型,文档,分片,映射是什么?
es是面向文档,关系行数据库和es客观的对比!一切都是JSON!
| Ralational DB | ElasticSearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | type |
| 行(rows) | documents |
| 字段(字段) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),
每个索引中可以包含多个类型(表),
每个类型下又包含多个文档(行),
每个文档行中又包含多个字段 (列)。
物理设计:
elasticseach在后台把每个索引划分成多个分片,每个分片可以在集群中的不同服务器间迁移。
一个人就是一个集群!默认的集群名称就是elaticsearch
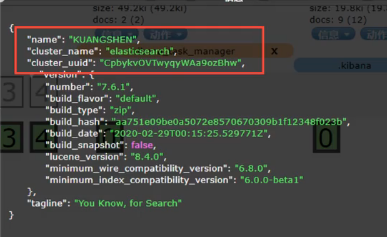
逻辑设计
一个索引类型中,包含多个文档,比较说文档1,文档2。当我们索引一篇文档时,可以通过这样的顺序找到它:索引-》类型-文档ID,通过这个组合我们就能索引到某个具体的文档,注意:ID不必是整数,实际上它是一个字符串。
文档
就是我们的一条条的记录
user
1 kuangsan 18
2 kuanshen 27
之前说elasticsearch是面向文档的,那么就意味着索引和搜索数据的最小单位是文档, elasticsearch中,文档有几个重要属性:
- 自我包含, 一篇文档同时包含字段和对应的值,也就是同时包含key:value !
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在elasticsearch中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为elasticsearch会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在elasticsearch中,类型有时候也称为映射类型。
类型
类型mysql里的字段类型

类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。类型中对于字段的定 义称为映射,比如name映射为字符串类型。我们说文档是无模式的 ,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么elasticsearch是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型, elasticsearch就开始猜,如果这个值是18 ,那么elasticsearch会认为它是整形。但是elasticsearch也可能猜不对 ,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。
索引
就数据库
索引是映射类型的容器,elasticsearch中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其它设置。然后它们被存储到了各个分片上了。我们来研究下分片是如何工作的。
物理设计 :节点和分片 如何工作

一个集群至少有一个节点,而一个节点就是elaticsearch的一个进程,节点可以有多个索引,默认的,如果你创建索引,那索引将会有5个分片(primary shard,又称主分片)构成的,每一个主分片会有一个副本(replica shard,又称为复制分片)

上图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。实际上, 一个分片是一个Lucene索引, 一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch使用的是一种称为倒排索引 |的结构,采用Lucene倒排索作为底层。这种结构适用于快速的全文搜索,一个索引由文
档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档,每个文档包含如下内容:
Study every day, good good up to forever # 文 档1包含的内容
To forever, study every day,good good up # 文档2包含的内容
为为创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens) ,然后创建一个包含所有不重 复的词条的排序列表,然后列出每个词条出现在哪个文档:
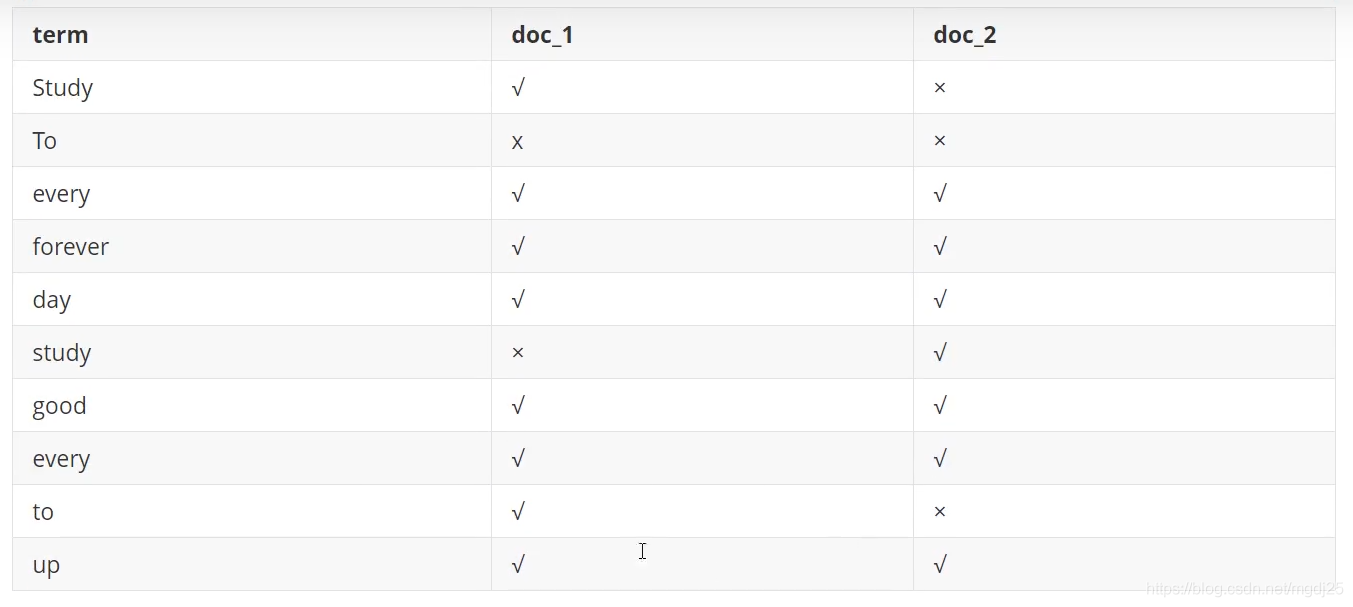
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
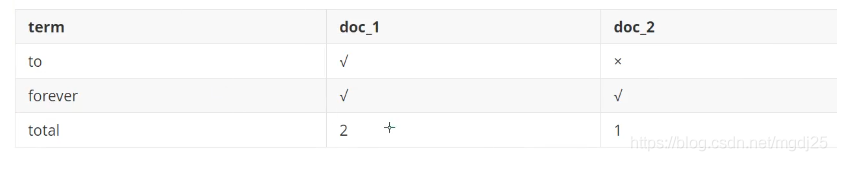
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构:
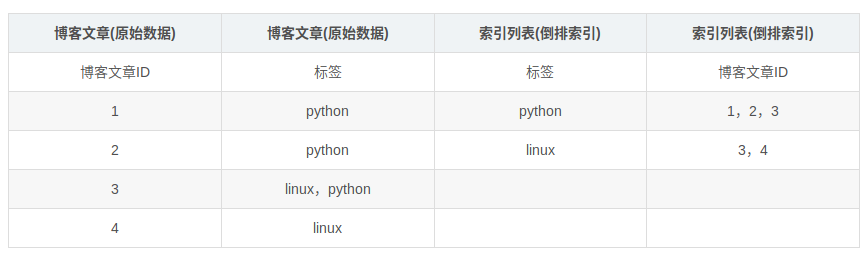
如果要搜索含有python标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
elasticsearch的索引和Lucene的索引对比
在elasticsearch中,索引(库)这个词被频繁使用,这就是术语的使用。在elasticsearch中 ,索引被分为多个分片,每份分片是一个Lucene的索引。所以一个elasticsearch索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢!如无特指,说起索引都是指elasticsearch的索引。
接下来的一切操作都在kibana中Dev Tools下的Console里完成。基础操作!
更多文章:
Elasticsearch简介、正向索引、倒排索引(系列一)---正井猫
https://www.jianshu.com/p/76481ae20f66
02 elasticsearch学习笔记-ES核心概念的更多相关文章
- Elasticsearch学习之基本核心概念
在Elasticsearch中有许多术语和概念 1. 核心概念 Elasticsearch集群可以包含多个索引(indices)(数据库),每一个索引可以包含多个类型(types)(表),每一个类型包 ...
- Docker 学习笔记之 核心概念
Docker核心概念: Docker Daemon Docker Container Docker Registry Docker Client 通过rest API 和Docker Daemon进程 ...
- ElasticSearch学习笔记(超详细)
文章目录 初识ElasticSearch 什么是ElasticSearch ElasticSearch特点 ElasticSearch用途 ElasticSearch底层实现 ElasticSearc ...
- Elasticsearch学习笔记一
Elasticsearch Elasticsearch(以下简称ES)是一款Java语言开发的基于Lucene的高效全文搜索引擎.它提供了一个分布式多用户能力的基于RESTful web接口的全文搜索 ...
- Elasticserach学习笔记-01基础概念
本文系本人根据官方文档的翻译,能力有限.水平一般,如果对想学习Elasticsearch的朋友有帮助,将是本人的莫大荣幸. 原文出处:https://www.elastic.co/guide/en/e ...
- elasticsearch学习笔记——相关插件和使用场景
logstash-input-jdbc学习 ES(elasticsearch缩写)的一大优点就是开源,插件众多.所以扩展起来非常的方便,这也造成了它的生态系统越来越强大.这种开源分享的思想真是与天朝格 ...
- Docker:学习笔记(1)——基础概念
Docker:学习笔记(1)——基础概念 Docker是什么 软件开发后,我们需要在测试电脑.客户电脑.服务器安装运行,用户计算机的环境各不相同,所以需要进行各自的环境配置,耗时耗力.为了解决这个问题 ...
- JavaScript:学习笔记(2)——基本概念与数据类型
JavaScript:学习笔记(2)——基本概念与数据类型 语法 1.区分大小写.Test 和 test 是完全不同的两个变量. 2.语句最好以分号结束,也就是说不以分号结束也可以. 变量 1.JS的 ...
- ElasticSearch学习笔记-01 简介、安装、配置与核心概念
一.简介 ElasticSearch是一个基于Lucene构建的开源,分布式,RESTful搜索引擎.设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便.支持通过HTTP使用JSON进 ...
- Elasticsearch学习笔记(六)核心概念和分片shard机制
一.核心概念 1.近实时(Near Realtime NRT) (1)从写入数据到数据可以被搜索到有一个小延迟(大概1秒): (2)基于es执行搜索和分析可以达到秒级 2.集群(Cluster) 一个 ...
随机推荐
- Kingbase ES 函数返回-return语句
文章概要: 本文在https://www.cnblogs.com/kingbase/p/15703611.html 一文的基础上总结了Kingbase ES中函数能支持的return语句,整体上兼容o ...
- .net跨平台运行实践
一个偶然的机会,一个朋友想做一个程序,同时支持windows和linux,本来想用go来写,奈何不太熟练,突然想到.net不是也支持跨平台了吗,还没有操作过,刚好可以试验一下. 最新的.net 6已经 ...
- Jenkins设置定时触发器执行任务
1. 选中任务,选择配置/构建触发器,选择定时构建 2. 填写定时器参数,格式说明如下,共五个参数,参数之间空格隔开,不需要填的直接*号即可. 此处d定时任务的格式遵循 cron 的语法(可以与 c ...
- 诚邀报名丨首期OpenHarmony开发者成长计划分享日
OpenAtom OpenHarmony(以下简称"OpenHarmony")开源开发者成长计划,是一项为了鼓励开发者积极参与开源软件的开发维护.帮助开发者在开源项目中成长的社会 ...
- HE琥珀虚颜破解自由安装程序教程(001)
HE琥珀虚颜破解自由安装程序教程(001) 前言 自从狗尾草跑路后,HE琥珀就没法用了,当前APP还没法破解,但是笔者找到了HE琥珀存在的一些漏洞,可以实现安装自己的APP. 所需工具 所需工具 1. ...
- 高并发报错too many clients already或无法创建线程
高并发报错 too many clients already 或无法创建线程 本文出处:https://www.modb.pro/db/432236 问题现象 高并发执行 SQL,报错"so ...
- 从 Oracle 到 MySQL 数据库的迁移之旅
目录 引言 一.前期准备工作 1.搭建新的MySQL数据库 2 .建立相应的数据表 2.1 数据库兼容性分析 2.1.1 字段类型兼容性分析 2.1.2 函数兼容性分析 2.1.3 是否使用存储过程? ...
- 3.1版本【HarmonyOS 第一课】正式上线!参与学习赢官方好礼>>
[课程介绍] <HarmonyOS第一课>是跟随版本迭代不断推出的系列化课程,本期课程基于HarmonyOS 3.1版本的新技术和特性,每个课程单元里面都包含视频.Codelab.文章 ...
- Node.js 与前端开发实战
0x1 Node.js 的应用场景 前端工程化 打包工具:webpack.vite.esbuild.parce 代码压缩:uglifyjs 语法转换:babeljs,typescript 难以替代 W ...
- Android 开发入门(3)
0x05 活动 Activity (1)启停活动页面 a. 启动和结束 从当前页面跳转至新页面 startActivity(new Intent(this, [targetPage].class)) ...