NumPy(1)-常用的初始化方法
一、NumPy介绍
NumPy是Python中科学计算的基础包,它是一个Python库,提供多维数组对象,各种派生对象(如掩码数组和矩阵),以及用于数组快速操作的各种API,有包括数学、逻辑、形状操作、排序、选择、输入输出、离散傅立叶变换、基本线性代数,基本统计运算和随机模拟等等。
- 功能强大的N维数组对象。
- 精密广播功能函数。
- 集成 C/C+和Fortran 代码的工具。
- 强大的线性代数、傅立叶变换和随机数功能。
二、Ndarray介绍
NumPy 最重要的一个特点是其 N 维数组对象 ndarray,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引。ndarray 对象是用于存放同类型元素的多维数组。ndarray 中的每个元素在内存中都有相同存储大小的区域。
三、Ndarray和python中的list列表的区别
C数组:学过C语言的都知道,在C语言中数组是一个连续的内存空间,并且数组中的数据的类型也是一致的。
python列表:python中的列表里面存放的对象,可以是不同的数据类型。其底层实现是通过类似C语言中的指针数组来实现,即python的列表中存放的数据的指针即他们的地址,然后再根据这个指针找到具体的数据。
Ndarray数组:和C语言数组实现类似,也是一段连续的内存空间,里面存放的也是相同的数据类型。
详细如下:
- NumPy 数组在创建时具有固定的大小,与Python的原生数组对象(可以动态增长)不同。更改ndarray的大小将创建一个新数组并删除原来的数组。
- NumPy 数组中的元素都需要具有相同的数据类型,因此在内存中的大小相同。
- NumPy 数组有助于对大量数据进行高级数学和其他类型的操作。通常,这些操作的执行效率更高,比使用Python原生数组的代码更少。
四、初始化NumPy数组
1、安装 numpy 包
pip3 install numpy
2、导入 numpy 包
import numpy
3、使用一个列表初始化一个NumPy数组
函数作用:初始化一个NumPy数组
函数原型:numpy.array(object, dtype=None, *, copy=True, order='K', subok=False, ndmin=0)
参数示例:
* object: 必填参数:即创建NumPy数组的数据对象
* dtype: 可选参数,通过它可以更改数组的数据类型---可将原来的整型或者其他类型进行强制转换
* copy: 可选参数,当数据源是ndarray 时表示数组能否被复制,默认是True
* order: 可选参数,以哪种内存布局创建数组,有3个可选值,分别是C(行序列)/F(列序列)/A(默认)
* ndmin: 可选参数,用于指定数组的维度--例如 一维数组、二维数组、三维数组等
* subok: 可选参数,类型为bool值,默认为False。 为True,使用object的内部数据类型; 为False 使用object数组的数据类型
代码示例:
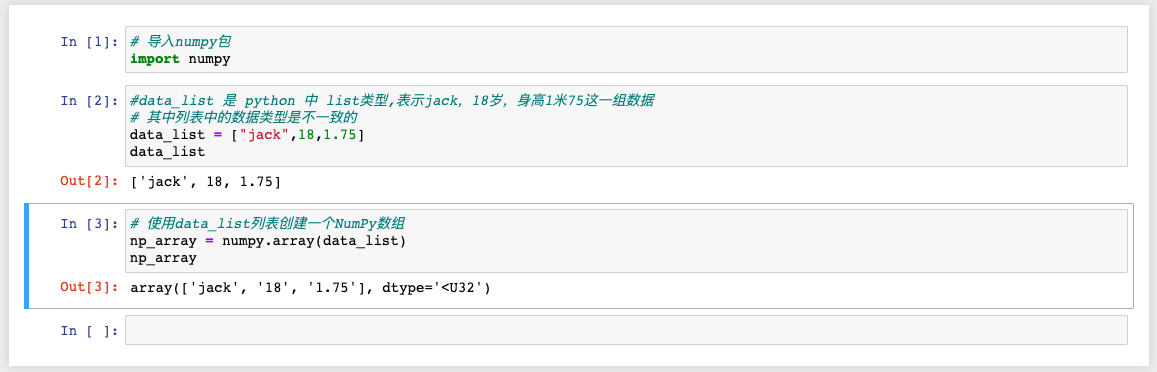
注意:
* 其中np_array就是Ndarray类型。
* data_list中的数据类型是不一致,但是转化成np_array后,数据格式一致了,都变成了字符串类型。
* 如果传进来的列表包含不同的类型,则统一转化为同一类型,转化的优先级:str>float>int,即有str则都转化为str,这样才能保证NumPy数组中数组的一致性。
4、numpy.ones()
函数作用:创造出来的数组里面填充的都是1
函数原型:numpy.ones(shape, dtype=None, order='C', *, like=None)
参数解释:
* shape:创建出来数组的形状,是一维数组,还是二维数组,还是多维数组等等
* dtype:数据的类型
* order:指定内存重以行优先(‘C’)还是列优先(‘F’)顺序存储多维数组。
代码示例:
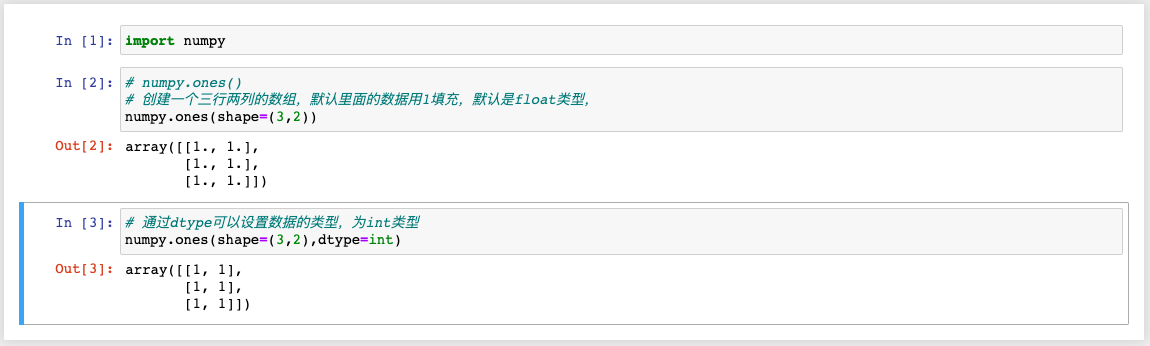
注意:
* shape = (m,n) m行n列 二位数组
* shape = (m) m个元素的一维数组 [1,2,3]
* shape = (m,) m个元素的一维数组
* shape = (m, 1) m行1列 二维数组 [[1],[2],[3]]
* shape = (1,m) 1行m列 二维数组 [[1,2,3]]
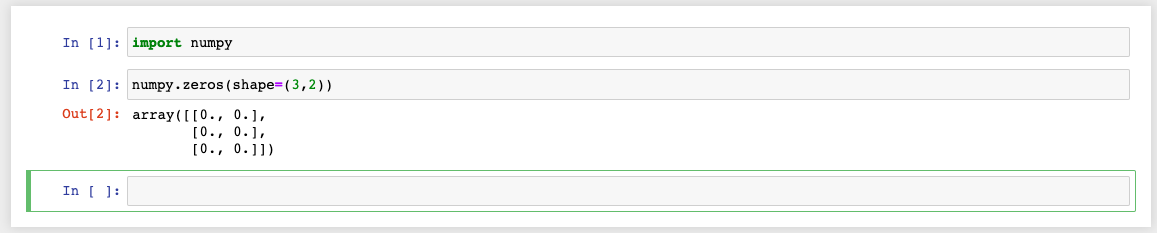
5、numpy.zeros()
函数作用:其用法和ones()一样,只不过被填充的由1变成了0
6、numpy.ful()
函数作用:使用自己指定数字填充数组内容
函数原型:numpy.full(shape, fill_value, dtype=None, order='C', *, like=None)
代码示例:

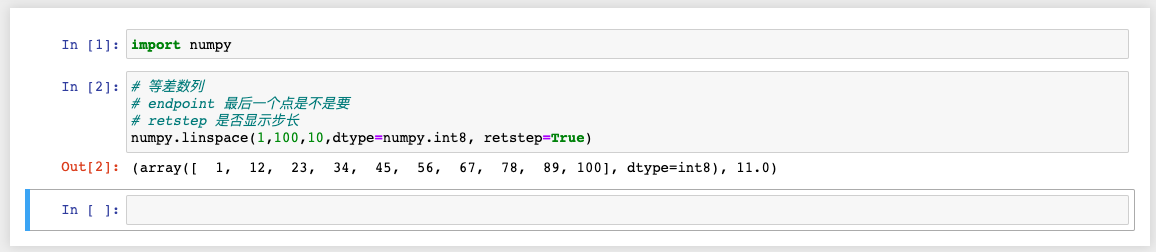
7、numpy.linspace()
函数作用: 生成等差数列的数组
函数原型:linspace(start, stop, num=50,endpoint=True,retstep=False,dtype=None)
参数解释:
* start,起始点
* stop,结束点
* num,元素个数,默认 50
* endpoint,是否包含 stop 数值,默认为 True,包含 stop 值;若为 False,则不包含 stop 值
* retstep,返回值形式,默认为 False,返回等差数列组,若为True,则返回结果 (array([‘samples’, ‘step’]))
* dtype,返回结果的数据类型,默认无,若无,则参考输入数据类型
代码示例:
8、numpy.arange()
函数作用:根据步长生成等差数列
函数原型:arange([start,] stop[, step,], dtype=None, *, like=None)
代码示例:

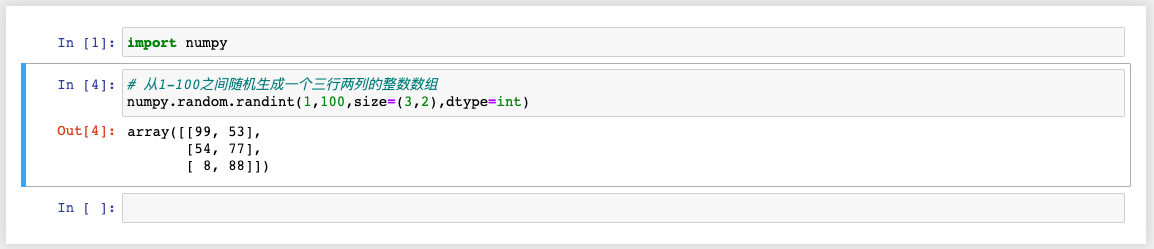
9、numpy.random.randint()
函数作用:使用随机数创建NumPy数组
函数原型:randint(low, high=None, size=None, dtype=int)
参数示例:
* low:随机数的最小值
* higt:随机数的最大值
* size:生出数组的形状
* dtype:数据类型
代码示例:
注意:类似的函数还有下面几个,用法也类似
* numpy.random.random(size): 随机生成小数的NumPy的数组
* numpy.random.randn(d0, d1, ..., dn): 标准正态分布
* np.random.normal(): 普通正态分布
五、ndarray的属性
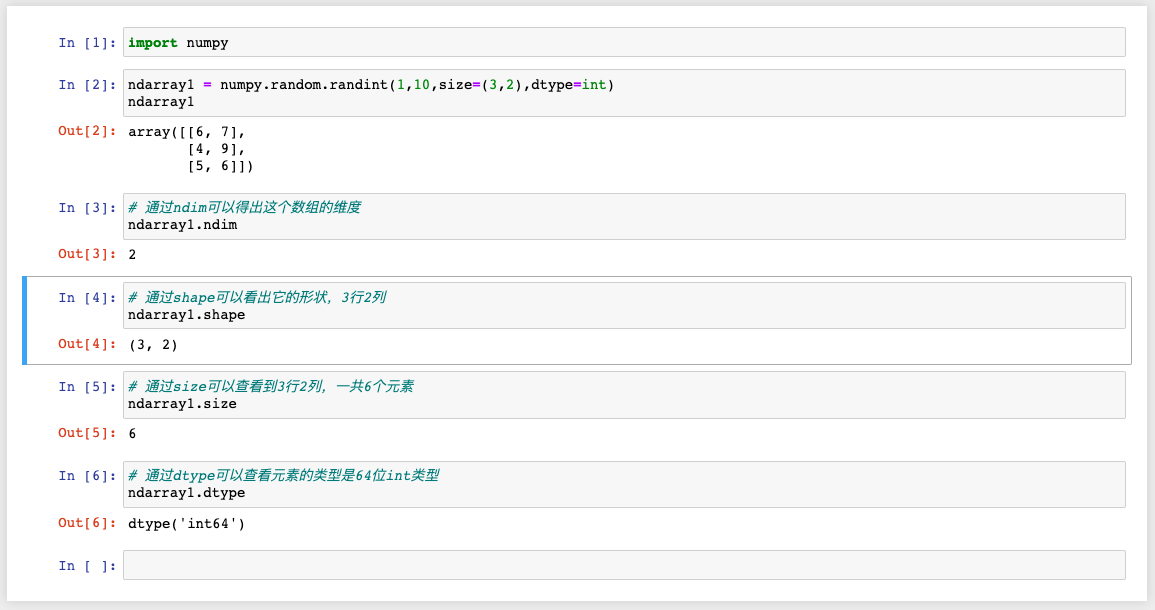
通过上面的示例,我们看到有几个属性是ndarray常用的属性,这里我们总结如下:
四个必记的属性
* ndim: 维度
* shape: 形状
* size: 总长度
* dtype: 元素类型
代码示例:
NumPy(1)-常用的初始化方法的更多相关文章
- PyTorch常用参数初始化方法详解
1. 均匀分布 torch.nn.init.uniform_(tensor, a=0, b=1) 从均匀分布U(a, b)中采样,初始化张量. 参数: tensor - 需要填充的张量 a - 均匀分 ...
- numpy.ndarray常用属性和方法
import numpy as np a = np.array([[1,2,3],[4,3,2],[6,3,5]])print(a) [[1 2 3] [4 3 2] [6 3 5]] print(a ...
- 干货:结合Scikit-learn介绍几种常用的特征选择方法
原文 http://dataunion.org/14072.html 主题 特征选择 scikit-learn 作者: Edwin Jarvis 特征选择(排序)对于数据科学家.机器学习从业者来说非 ...
- 结合Scikit-learn介绍几种常用的特征选择方法
特征选择(排序)对于数据科学家.机器学习从业者来说非常重要.好的特征选择能够提升模型的性能,更能帮助我们理解数据的特点.底层结构,这对进一步改善模型.算法都有着重要作用. 特征选择主要有两个功能: 减 ...
- [转载]Scikit-learn介绍几种常用的特征选择方法
#### [转载]原文地址:http://dataunion.org/14072.html 特征选择(排序)对于数据科学家.机器学习从业者来说非常重要.好的特征选择能够提升模型的性能,更能帮助我们理解 ...
- caffe中权值初始化方法
首先说明:在caffe/include/caffe中的 filer.hpp文件中有它的源文件,如果想看,可以看看哦,反正我是不想看,代码细节吧,现在不想知道太多,有个宏观的idea就可以啦,如果想看代 ...
- oc实例变量初始化方法
1 使用实例setter方法 默认初始化方法 + setName:xxx setAge:xxx 2 使用实例功能类方法,默认初始化方法 + setName:xxx age:xxx3 使用实例初始化方法 ...
- ios基础篇(四)——UILabel的常用属性及方法
UILabel的常用属性及方法:1.text //设置和读取文本内容,默认为nil label.text = @”文本信息”; //设置内容 NSLog(@”%@”, label.text); //读 ...
- UITableView常用属性和方法 - 永不退缩的小白菜
UITableView常用属性和方法 - 永不退缩的小白菜 时间 2014-05-27 01:21:00 博客园精华区原文 http://www.cnblogs.com/zhaofucheng11 ...
- UIView的一些常用属性和方法
UIView的一些常用属性和方法 1. UIView的属性 UIView继承自UIResponder,拥有touches方法. - (instancetype)initWithFrame:(CGRec ...
随机推荐
- ubuntu容器的远程xface桌面环境搭建
一.container: ubuntu20.04 二.commands: apt install xfce4 tigervnc-standalone-server # xface使用gdm3启动器 ...
- 关于在visual Studio 2022中无法找到 ASP.NET Core Web Application 或 ASP.NET Core Web 应用程序
在学习 ASP.NET Core Web Application 时 发现无论如何都无法找到这个模板,在翻遍论坛后都没有看到解决的方法,在我下载 visual Studio 2017 中终于找到了 但 ...
- python pyinstaller库
简要 pyinstaller模块主要用于python代码打包成exe程序直接使用,这样在其它电脑上即使没有python环境也是可以运行的. 用法 一.安装 pyinstaller属于第三方库,因此在使 ...
- 第一个c语言项目
怎么写代码呢 工具:编译器 市面上编译器主要有:clang,gcc,win-tc,msvc,turbo c等 怎么写呢 1.创建一个项目(项目名字不能以中文文字命名) 2.创建一个文件(项目名字不能以 ...
- 带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性
带你简单了解Chatgpt背后的秘密:大语言模型所需要条件(数据算法算力)以及其当前阶段的缺点局限性 1.什么是语言模型? 大家或多或少都听过 ChatGPT 是一个 LLMs,那 LLMs 是什么? ...
- 2023-04-15:ffmpeg的filter_audio.c的功能是生成一个正弦波音频,然后通过简单的滤镜链,最后输出数据的MD5校验和。请用go语言改写。
2023-04-15:ffmpeg的filter_audio.c的功能是生成一个正弦波音频,然后通过简单的滤镜链,最后输出数据的MD5校验和.请用go语言改写. 答案2023-04-15: 代码见gi ...
- Django django-rest-framework-simplejwt
Django(75)django-rest-framework-simplejwt「建议收藏」 发布于2022-09-16 11:56:13阅读 2440 大家好,又见面了,我是你们的朋友全栈君. ...
- SpringMVC 后台从前端获取单个参数
1.编写web.xml(模板) 2.springmvc配置文件 3.编写对应数据库字段的pojo实体类 @Data @AllArgsConstructor @NoArgsConstructor pub ...
- Must use destructuring props assignmenteslint
eslint 检测提示Must use destructuring props assignmenteslint 使用对象结构就可以解决了
- 代码随想录算法训练营Day12 栈与队列
代码随想录算法训练营 代码随想录算法训练营Day12 栈与队列| 239. 滑动窗口最大值 347.前 K 个高频元素 总结 239. 滑动窗口最大值 给定一个数组 nums,有一个大小为 k 的 ...