分布式文件系统HDFS,大数据存储实战(一)
本文进行了以下工作:
- OS中建立了两个文件,文件中保存了几组单词。
- 把这两个文件导入了hadoop自己的文件系统。
- 介绍删除已导入hadoop的文件和目录的方法,以便万一发生错误时使用。
- 使用列表命令查看导入的文件和新建的目录。
- 调用hadoop自带的示例jar包hadoop-0.20.2-example.jar中的程序wordcount,输出结果,以测试本hadoop系统是否可以正常工作。
- 在OS中查看hadoop所产生的文件。
- 在web页面中查看系统各状态。
预备知识
和各种大型关系型数据库(如sql server和oracle等)一样,Hadoop有自己的文件系统,在操作系统中只能看到文件,用文件工具强制打开以后是无法理解的乱码,只能通过Hadoop系统去管理和读取。
所以OS的文件系统和hadoop的文件系统是相互独立的,要用hadoop,需要从OS中把文件导入hadoop系统。
准备测试文件
OS中hadoop目录下新建input目录,之所以叫input,是因为相对hadoop系统来讲,这个目录是输入目录。
用echo “hello world” >test1.txt的方式,创建两个文件,当然可以用其它任何方式创建文件。结果如图所示:
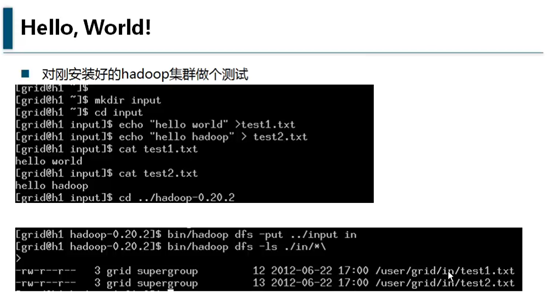
bin/hadoo dfs -put ../input in
-put的意思是把本地的input目录下的文件放到hadoop系统的in目录下。
完成以后可用以下命令查看:
bin/hadoop dfs -ls in/*
效果如上图。意思是:列出in目录下的所有目录及文件
如果要从hadoop中删除一个目录,则使用以下命令
bin/hadoop dfs -rmr 目录名
参数dfs表示对分布式文件系统进行操作,相应的还有jar,表示调用jar包中的程序。
运行java程序,对已配置完成的hadoop系统进行测试

运行bin/hadoop jar hadoop-0.20.2-examples.jar wordcount in out
jar表示运行java程序,一般是一个mapreduce的作业,即提交mapreduce作业。图中的hadoop-0.20.2是hadoop提供的示例jar包,wordcount程序在其中,in指出hadoop系统中的原始数据目录,out是hadoop系统中的输出数据目录,如果不存在,则自动创建。顾名可思义,wordcount是用来统计单词出现次数的程序。
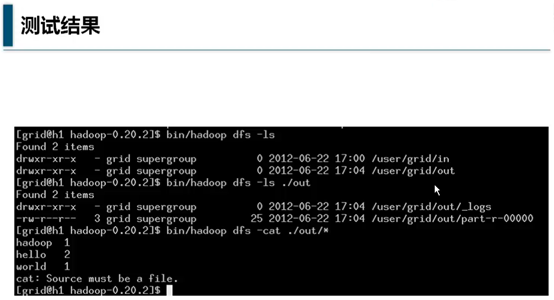
bin/hadooop dfs -ls,表示列出根目录的目录列表
bin/hadooop dfs -ls out,表示列出out目录的目录列表
输出后,执行结果放在了part-r-00000文件中,日志放在了_logs目录
hadoop dfs -cat out/part-r-00000
是显示part-r-00000的结果,可以看到
hadood 出现了1次,hello出现了2次,world出现了1次

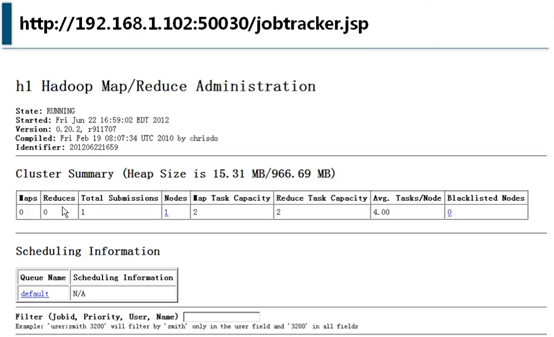
在namenode上可以用localhost:50030,远程可以用IP:50030,如http://192.168.1.8:50030
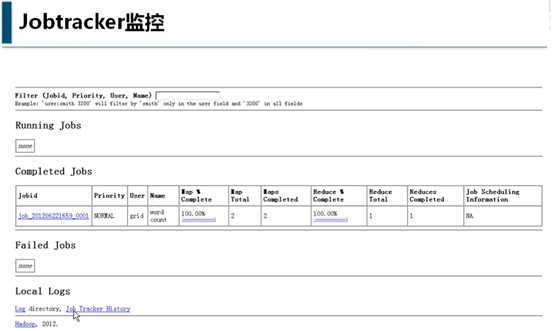
最后,再把前面提到的关于hadoop是一个独立的文件系统用实际数据展示一下:
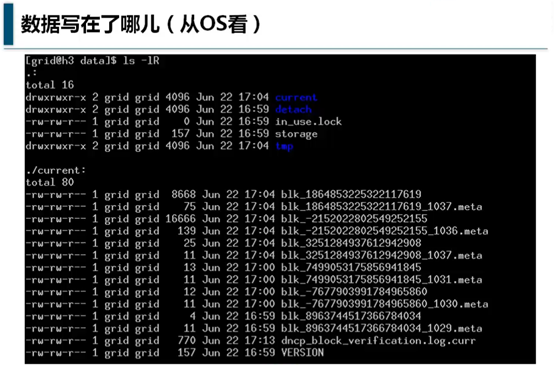
可以看到meta是原始数据,不带meta的是数据文件。
这些文件会保存在数据节点(小弟机、slaves)的hdfs-site.xml文件中的fs.data.dir所指向的目录,如/opt/hadoop/data。修改后此值后,master调用bin/stop-all.sh,再调用bin/start-all.sh后完成重新启动后,就能看到新的数据目录。
分布式文件系统HDFS,大数据存储实战(一)的更多相关文章
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 大数据 --> 分布式文件系统HDFS的工作原理
分布式文件系统HDFS的工作原理 Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- 【转载】Hadoop分布式文件系统HDFS的工作原理详述
转载请注明来自36大数据(36dsj.com):36大数据 » Hadoop分布式文件系统HDFS的工作原理详述 转注:读了这篇文章以后,觉得内容比较易懂,所以分享过来支持一下. Hadoop分布式文 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- 大数据技术原理与应用——分布式文件系统HDFS
分布式文件系统概述 相对于传统的本地文件系统而言,分布式文件系统(Distribute File System)是一种通过网络实现文件在多台主机上进行分布式存储的文件系统.分布式文件系统的设计一般采用 ...
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 大数据开发实战:HDFS和MapReduce优缺点分析
一. HDFS和MapReduce优缺点 1.HDFS的优势 HDFS的英文全称是 Hadoop Distributed File System,即Hadoop分布式文件系统,它是Hadoop的核心子 ...
随机推荐
- SQL Server 数据库基础笔记分享(下)
前言 本文是个人学习SQL Server 数据库时的以往笔记的整理,内容主要是对数据库的基本增删改查的SQL语句操作和约束,视图,存储过程,触发器的基本了解. 注:内容比较基础,适合入门者对SQL S ...
- [Aaronyang] 写给自己的WPF4.5 笔记11[自定义控件-AyImageButton的过程 1/4]
我的文章一定要对读者负责-否则不是好文章 ---- www.ayjs.net aaronyang技术分享 文章导航: 介绍vs2013 WPF开发,属性代码相关技巧 实战AyImage ...
- ASP.NET CORE下用盛派微信SDK取微信openid
用CORE做项目用到微信的相关东西,听说那个盛派微信SDK很火,自己弄了下,只是简单的用用,用户访问页面取微信openid
- PCA主成份分析学习记要
前言 主成份分析,简写为PCA(Principle Component Analysis).用于提取矩阵中的最主要成分,剔除冗余数据,同时降低数据纬度.现实世界中的数据可能是多种因数叠加的结果,如果这 ...
- Python--Redis实战:第四章:数据安全与性能保障:第7节:非事务型流水线
之前章节首次介绍multi和exec的时候讨论过它们的”事务“性质:被multi和exec包裹的命令在执行时不会被其他客户端打扰.而使用事务的其中一个好处就是底层的客户端会通过使用流水线来提高事务执行 ...
- 阿里巴巴CI:CD之分层自动化实践之路
阿里巴巴CI:CD之分层自动化实践之路 2018-05-30 摘自:阿里巴巴CI:CD之分层自动化实践之路 目录 1 自动化 1.1 为什么要做自动化? 1.2 自动化的烦恼 1.3 自动化的追 ...
- 【emWin】例程二十:窗口对象——Dropdown
简介: DROPDOWN 小工具用于从具有若干栏的列表中选择一个元素,它以非打开状态显示当前选择的项目.如果用户打开DROPDOWN 小工具,就会出现一个选择新项目的LISTBOX. 触摸校准(上电可 ...
- mysql 5.7 学习
MySQL5.7 添加用户.删除用户与授权 mysql -uroot -proot MySQL5.7 mysql.user表没有password字段改 authentication_string: ...
- ELK 性能(4) — 大规模 Elasticsearch 集群性能的最佳实践
ELK 性能(4) - 大规模 Elasticsearch 集群性能的最佳实践 介绍 集群规模 集群数:6 整体集群规模: 300 Elasticsearch 实例 141 物理服务器 4200 CP ...
- 聊聊Python中的闭包和装饰器
1. 闭包 首先我们明确一下函数的引用,如下所示: def test1(): print("--- in test1 func----") # 调用函数 test1() # 引用函 ...