HashMap的自定义实现
一、背景:
package com.cy.collection;
public class Wife {
String name;
public Wife(String name){
this.name = name;
}
@Override
public String toString() {
return "Wife [name=" + name + "]";
}
}
Map.java:
package com.cy.collection; /**
* 自定义实现Map
*/
public class Map {
private Entry[] arr = new Entry[1000]; //这里暂时不考虑扩容
private int size; //这里都是private的,不暴露size属性 /**
* 1.键不能重复,如果含有这个键,就替换value
* @param key
* @param value
*/
public void put(Object key, Object value){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
arr[i].value = value;
return;
}
}
arr[size++] = new Entry(key, value);
} //根据key获取
public Object get(Object key){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
return arr[i].value;
}
}
return null;
} //根据key删除
public boolean remove(Object key){
boolean success = false;
for(int i=0;i<size;i++){
if(arr[i].key.equals(key)){
success = true;
remove(i);
}
}
return success;
}
private void remove(int i){
int numMoved = size - i - 1;
if(numMoved>0){
System.arraycopy(arr, i+1, arr, i, numMoved);
}
arr[--size] = null; //Let gc do its work
} //containsKey
public boolean containsKey(Object key){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
return true;
}
}
return false;
} //containsValue 同containsKey //size
public int size(){
return size;
}
} /**
* 用来存放键值对的条目
*/
class Entry{
Object key;
Object value; public Entry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
}
Test.java测试代码:
package com.cy.collection;
public class Test {
public static void main(String[] args) {
Map map = new Map();
map.put("张三", new Wife("abc"));
map.put("李四", new Wife("def"));
map.put("王五", new Wife("ghi"));
System.out.println(map.get("张三"));
map.remove("李四");
System.out.println(map.size());
map.put("张三", new Wife("aaa"));
System.out.println(map.get("张三"));
System.out.println(map.containsKey("张三"));
}
}
输出:
Wife [name=abc]
2
Wife [name=aaa]
true
二、map改进,哈希算法实现,使用数组和链表
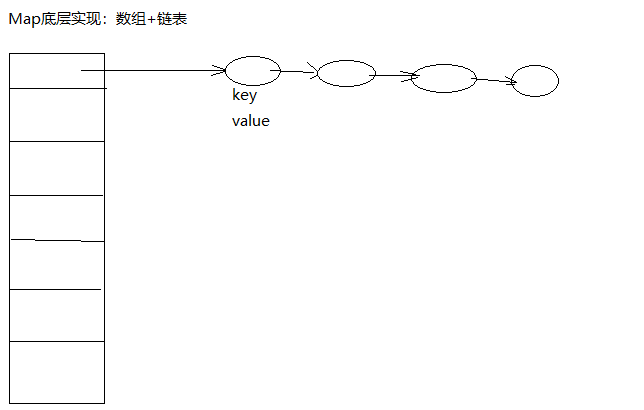
package com.cy.collection; import java.util.LinkedList; /**
* 自定义实现Map升级版
* 1.提高查询的效率
*/
public class Map {
private LinkedList[] arr = new LinkedList[1000]; //Map的底层结构就是:数组+链表
private int size; /**
* 1.键不能重复,如果含有这个键,就替换value
*/
public void put(Object key, Object value){
Entry e = new Entry(key, value);
int hash = key.hashCode();
hash = hash<0?-hash:hash;
int a = hash % arr.length;
if(arr[a]==null){
LinkedList list = new LinkedList();
arr[a] = list;
list.add(e);
}else{
LinkedList list = arr[a];
for(int i=0; i<list.size(); i++){
Entry en = (Entry) list.get(i);
if(en.key.equals(key)){
en.value = value; //键值重复,覆盖value
return;
}
}
list.add(e);
}
size++;
}
//根据key获取值
public Object get(Object key){
int a = key.hashCode() % arr.length;
if(arr[a]!=null){
LinkedList list = arr[a];
for(int i=0; i<list.size(); i++){
Entry e = (Entry) list.get(i);
if(e.key.equals(key)){
return e.value;
}
}
}
return null;
}
//size
public int size(){
return size;
}
}
/**
* 用来存放键值对的条目
*/
class Entry{
Object key;
Object value;
public Entry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
}
Test.java
package com.cy.collection;
public class Test {
public static void main(String[] args) {
Map map = new Map();
map.put("张三", new Wife("abc"));
map.put("李四", new Wife("def"));
map.put("张三", new Wife("ghi"));
System.out.println(map.get("张三"));
System.out.println(map.size());
}
}
输出:
Wife [name=ghi]
2
HashMap的自定义实现的更多相关文章
- HashMap存储自定义类型键值和LinkedHashMap集合
HashMap存储自定义类型键值 1.当给HashMap中存放自定义对象时,如果自定义对象是键存在,保证键唯一,必须复写对象的hashCode和equals方法. 2.如果要保证map中存放的key和 ...
- 集合框架-Map集合-HashMap存储自定义对象
1 package cn.itcast.p6.hashmap.demo; 2 3 import java.util.HashMap; 4 import java.util.Iterator; 5 im ...
- HashSet的自定义实现
package com.cy.collection; import java.util.HashMap; /** * HashSet自定义实现 * 是使用hashMap实现的 * 可以看一下HashS ...
- Java 集合学习--HashMap
一.HashMap 定义 HashMap 是一个基于散列表(哈希表)实现的键值对集合,每个元素都是key-value对,jdk1.8后,底层数据结构涉及到了数组.链表以及红黑树.目的进一步的优化Has ...
- springboot 简单自定义starter - beetl
使用idea新建springboot项目beetl-spring-boot-starter 首先添加pom依赖 packaging要设置为jar不能设置为pom<packaging>jar ...
- 通过简单的两数相加体会hashmap的好处
目录 引入题目:两数相加 HashMap相关知识: Map集合 Map集合的特点 Map常用子类 HashMap集合 LinkedHashMap集合 Map集合的常用方法 Map集合的第一种遍历方式: ...
- Java 之 HashMap 集合
一.HashMap 概述 java.util.HashMap<k,v> 集合 implements Map<k,v> 接口 HashMap 集合的特点: 1.HashMap 集 ...
- hashmap存储数据
在HashMap中,为什么不能使用基本数据类型作为key? 其实和HashMap底层的存储原理有关,HashMap存储数据的特点是:无序.无索引.不能存储重复元素. 存储元素采用的是hash表存储数据 ...
- HashMap -双列集合的遍历与常用的方法
package cn.learn.Map; /* java.util.Hashtable<k,y> implements Map<k,v> 早期双列集合,jdk1.0开始 同步 ...
随机推荐
- rsync命令
1.rsync命令(文件同步工具,可以理解为动态备份): rsync是linux系统下的数据镜像备份工具.使用快速增量备份工具Remote Sync可以远程同步,支持本地复制,或者与其他SSH.rsy ...
- PTA——各位数之和
PTA 7-28 求整数的位数及各位数字之和 我的程序: #include<stdio.h> #include<math.h> int main(){ ,t; scanf(&q ...
- PTA——类型转换
PTA习题 7-6 厘米换算英尺英寸 (15 分) #include<stdio.h> int main(){ int a; int b,c; scanf("%d",& ...
- 《DSP using MATLAB》Problem 5.19
代码: function [X1k, X2k] = real2dft(x1, x2, N) %% --------------------------------------------------- ...
- Spring 注解bean默认名称规则
在使用@Component.@Repository.@Service.@Controller等注解创建bean时,如果不指定bean名称,bean名称的默认规则是类名的首字母小写,如SysConfig ...
- XML之命名空间的作用(xmlns)
http://www.w3school.com.cn/xml/xml_namespaces.asp http://blog.csdn.net/zhch152/article/details/81913 ...
- Nginx学习安装配置和Ftp配置安装
什么是代理? 什么是正向代理? 什么是反向代理? Nginx与负载均衡有什么联系? 如何在centos7 中安装Nginx-------------安装配置---------------------- ...
- SQLite数据库下载
一:SQLite简介 SQLite是一种嵌入式数据库,它的数据库就是一个文件.体积很小,经常被集成到各种应用程序中,甚至在iOS和Android的App中都可以集成. 要操作关系数据库,首先需要连接到 ...
- adx-desc-adtype统计
数据分析脚本: filepath="request.log.2017-12-01-15" File.open("#{filepath}").each do |l ...
- Cassandra--启用用户认证和用户管理
======================================================== 启用用户认证和创建超级用户 需要针对每个节点进行配置修改和重启,但授权操作仅需要在任一 ...