HashMap的自定义实现
一、背景:
package com.cy.collection;
public class Wife {
String name;
public Wife(String name){
this.name = name;
}
@Override
public String toString() {
return "Wife [name=" + name + "]";
}
}
Map.java:
package com.cy.collection; /**
* 自定义实现Map
*/
public class Map {
private Entry[] arr = new Entry[1000]; //这里暂时不考虑扩容
private int size; //这里都是private的,不暴露size属性 /**
* 1.键不能重复,如果含有这个键,就替换value
* @param key
* @param value
*/
public void put(Object key, Object value){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
arr[i].value = value;
return;
}
}
arr[size++] = new Entry(key, value);
} //根据key获取
public Object get(Object key){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
return arr[i].value;
}
}
return null;
} //根据key删除
public boolean remove(Object key){
boolean success = false;
for(int i=0;i<size;i++){
if(arr[i].key.equals(key)){
success = true;
remove(i);
}
}
return success;
}
private void remove(int i){
int numMoved = size - i - 1;
if(numMoved>0){
System.arraycopy(arr, i+1, arr, i, numMoved);
}
arr[--size] = null; //Let gc do its work
} //containsKey
public boolean containsKey(Object key){
for(int i=0; i<size; i++){
if(arr[i].key.equals(key)){
return true;
}
}
return false;
} //containsValue 同containsKey //size
public int size(){
return size;
}
} /**
* 用来存放键值对的条目
*/
class Entry{
Object key;
Object value; public Entry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
}
Test.java测试代码:
package com.cy.collection;
public class Test {
public static void main(String[] args) {
Map map = new Map();
map.put("张三", new Wife("abc"));
map.put("李四", new Wife("def"));
map.put("王五", new Wife("ghi"));
System.out.println(map.get("张三"));
map.remove("李四");
System.out.println(map.size());
map.put("张三", new Wife("aaa"));
System.out.println(map.get("张三"));
System.out.println(map.containsKey("张三"));
}
}
输出:
Wife [name=abc]
2
Wife [name=aaa]
true
二、map改进,哈希算法实现,使用数组和链表
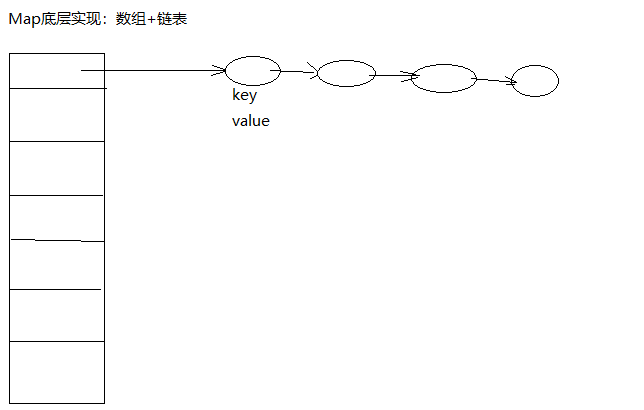
package com.cy.collection; import java.util.LinkedList; /**
* 自定义实现Map升级版
* 1.提高查询的效率
*/
public class Map {
private LinkedList[] arr = new LinkedList[1000]; //Map的底层结构就是:数组+链表
private int size; /**
* 1.键不能重复,如果含有这个键,就替换value
*/
public void put(Object key, Object value){
Entry e = new Entry(key, value);
int hash = key.hashCode();
hash = hash<0?-hash:hash;
int a = hash % arr.length;
if(arr[a]==null){
LinkedList list = new LinkedList();
arr[a] = list;
list.add(e);
}else{
LinkedList list = arr[a];
for(int i=0; i<list.size(); i++){
Entry en = (Entry) list.get(i);
if(en.key.equals(key)){
en.value = value; //键值重复,覆盖value
return;
}
}
list.add(e);
}
size++;
}
//根据key获取值
public Object get(Object key){
int a = key.hashCode() % arr.length;
if(arr[a]!=null){
LinkedList list = arr[a];
for(int i=0; i<list.size(); i++){
Entry e = (Entry) list.get(i);
if(e.key.equals(key)){
return e.value;
}
}
}
return null;
}
//size
public int size(){
return size;
}
}
/**
* 用来存放键值对的条目
*/
class Entry{
Object key;
Object value;
public Entry(Object key, Object value) {
super();
this.key = key;
this.value = value;
}
}
Test.java
package com.cy.collection;
public class Test {
public static void main(String[] args) {
Map map = new Map();
map.put("张三", new Wife("abc"));
map.put("李四", new Wife("def"));
map.put("张三", new Wife("ghi"));
System.out.println(map.get("张三"));
System.out.println(map.size());
}
}
输出:
Wife [name=ghi]
2
HashMap的自定义实现的更多相关文章
- HashMap存储自定义类型键值和LinkedHashMap集合
HashMap存储自定义类型键值 1.当给HashMap中存放自定义对象时,如果自定义对象是键存在,保证键唯一,必须复写对象的hashCode和equals方法. 2.如果要保证map中存放的key和 ...
- 集合框架-Map集合-HashMap存储自定义对象
1 package cn.itcast.p6.hashmap.demo; 2 3 import java.util.HashMap; 4 import java.util.Iterator; 5 im ...
- HashSet的自定义实现
package com.cy.collection; import java.util.HashMap; /** * HashSet自定义实现 * 是使用hashMap实现的 * 可以看一下HashS ...
- Java 集合学习--HashMap
一.HashMap 定义 HashMap 是一个基于散列表(哈希表)实现的键值对集合,每个元素都是key-value对,jdk1.8后,底层数据结构涉及到了数组.链表以及红黑树.目的进一步的优化Has ...
- springboot 简单自定义starter - beetl
使用idea新建springboot项目beetl-spring-boot-starter 首先添加pom依赖 packaging要设置为jar不能设置为pom<packaging>jar ...
- 通过简单的两数相加体会hashmap的好处
目录 引入题目:两数相加 HashMap相关知识: Map集合 Map集合的特点 Map常用子类 HashMap集合 LinkedHashMap集合 Map集合的常用方法 Map集合的第一种遍历方式: ...
- Java 之 HashMap 集合
一.HashMap 概述 java.util.HashMap<k,v> 集合 implements Map<k,v> 接口 HashMap 集合的特点: 1.HashMap 集 ...
- hashmap存储数据
在HashMap中,为什么不能使用基本数据类型作为key? 其实和HashMap底层的存储原理有关,HashMap存储数据的特点是:无序.无索引.不能存储重复元素. 存储元素采用的是hash表存储数据 ...
- HashMap -双列集合的遍历与常用的方法
package cn.learn.Map; /* java.util.Hashtable<k,y> implements Map<k,v> 早期双列集合,jdk1.0开始 同步 ...
随机推荐
- (18)模型层 -ORM之msql 多表操作(字段的属性)
数据库表的对应关系 1.一对一 #关联字段写在那张表都可以 PS:只要写OneToOneField就会自动加一个id 2.一对多 #关系确立,关联字段写在多的一方 3.多对多 #多对多的关系 ...
- url和资源的再理解
元数据管理系统中, 确实是所有的静态资源都放在WebContent 不在dgs这个主项目中,通过url访问了 下面的这个项目在dgs中
- mysql之commit,transaction事物控制
简单来说,transaction就是用来恢复为以前的数据. 举个例子,我想把今天输入到数据库里的数据在晚上的时候全部删除,那么我们就可以在今天早上的时候开始transaction事物,令autocom ...
- <--------------------------构造方法------------------------------>
1 构造方法 初始化阶段 给对象的属性进行赋值 构造方法 什么是构造方法 : 字面 方法构建时 就使用的方法 对象创建的时候就使用的方法 作用:对象的属性值初始化2 如何用构造方法 修饰符 构造方法名 ...
- replicatedhq-ship 基于Kustomize 项目的快速kubernetes 应用部署工具
replicatedhq-ship 是对Kustomize 项目的扩展,我们可以用它来快速的进行三方应用的管理部署, 可以和helm,kubernetes 清单文件,knative 集成,我们可以方便 ...
- 03C++语言对C的增强——实用性、变量检测、struct类型、C++中所有变量和函数都必须有类型、bool类型、三目运算符
1.“实用性”增强 C语言中的变量都必须在作用域开始的位置定义,C++中更强调语言的“实用性”,所有的变量都可以在需要使用时再定义. 2.C++对c语言register的增强 register关键字 ...
- ESB雏形 -- 项目企业服务总线初始
今天要厚着脸皮给大家推荐一个自己做的通信中间件——ServiceAnt,目前已经在我们团队的两个产品线上投入了使用. ServiceAnt是什么 它最初的定位是ESB(企业服务总线),但目前还没有达到 ...
- str_replace中的匹配空白符,必须用双引号
例: $minUnit = str_replace(array('\r','\n'),"",$content); 执行上面的语句,你会发现,文本没有任何变化,该换行的地方还是换行. ...
- 深入详解美团点评CAT跨语言服务监控(八)报表持久化
周期结束 我们从消息分发章节知道,RealtimeConsumer在初始化的时候,会启动一个线程,每隔1秒钟就去从判断是否需要开启或结束一个周期(Period),如下源码,如果 value < ...
- SqlServer语句
1.增加列 增加int列,不为空并赋默认值为0 alter table Department add Status int not null default 0 with values 2.新建表:c ...