python selenium-webdriver 生成测试报告 (十四)
测试最后的一个重要的过程就是生成一份完整的测试报告,生成测试报告的主要是通过python的一个第三方模块HTMLTestRunner.py生成,但是生成的测试报告不是特别的美观,而且没有办法统计测试结果分类,同时也没有办法把测试结果的图片保存下来。通过github 查找到一个改版后的HTMLTestRunner,但是发现美观是美观些,但是有些小问题,而且也不能把我的测试结果截图显示,所以自己又在其基础上增加了图片、测试结果的饼图分布、对测试结果进行错误、失败、通过进行分类。
生成的报告
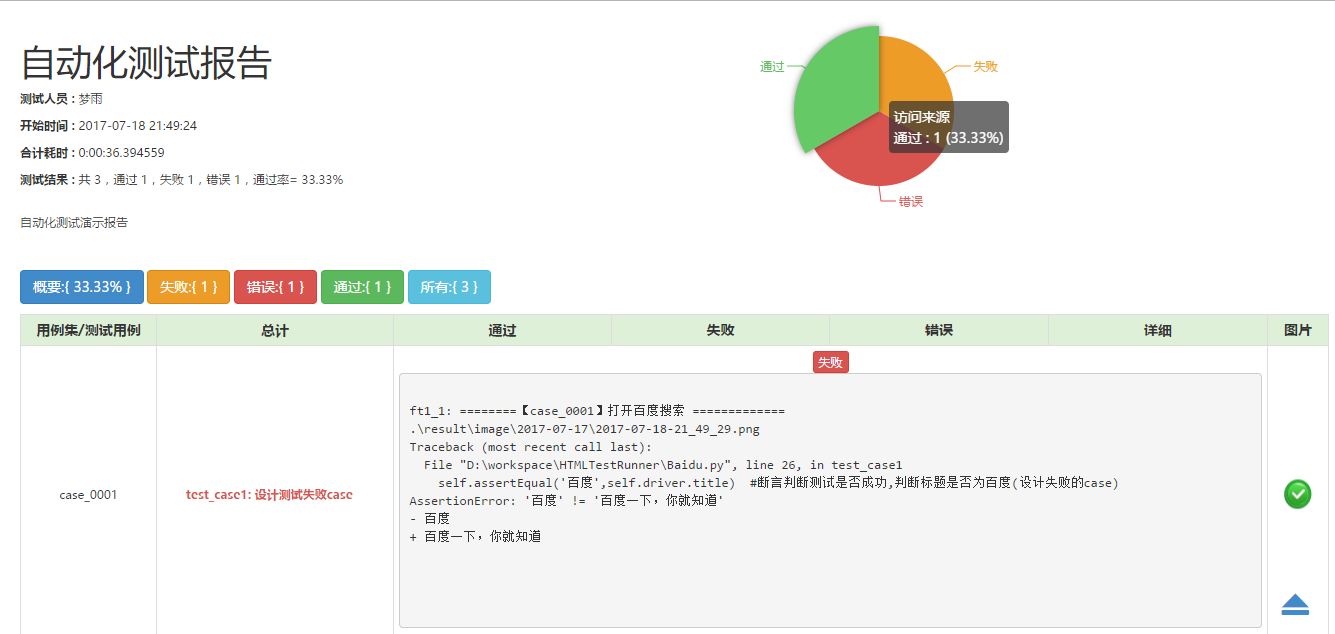
下面看下如何生成报告,接下来我们为写一个测试演示的代码生成一份报告,生成报告的时候主要利用unittest和HTMLTestReport构建。
# -*- coding: utf-8 -*-
from selenium import webdriver
import unittest
import os,sys,time
import HTMLTestReport class Baidu(unittest.TestCase): def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.driver.maximize_window()
self.base_url = "https://www.baidu.com"
self.driver.get(self.base_url) def test_case1(self):
'''设计测试失败case'''
print ("========【case_0001】打开百度搜索 =============")
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
# 必须打印图片路径HTMLTestRunner才能捕获并且生成路径,\image\**\\**.png 是获取路径的条件,必须这样的目录
pic_path = '.\\result\\image\\' + '2017-07-17\\' + current_time +'.png' #设置存储图片路径,测试结果图片可以按照每天进行区分
print (pic_path) #打印图片路径
time.sleep(2)
self.driver.save_screenshot(pic_path) #截图,获取测试结果
self.assertEqual('百度',self.driver.title) #断言判断测试是否成功,判断标题是否为百度(设计失败的case) def test_case2(self):
'''设计测试过程中报错的case'''
print ("========【case_0002】搜索selenium =============")
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(u"selenium")
self.driver.find_element_by_id('su').click()
time.sleep(2)
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
pic_path = '.\\result\\image\\'+ '2017-07-17\\' + current_time + '.png'
print (pic_path)
self.driver.save_screenshot(pic_path) #截图测试结果
self.assertIn1('selenium',self.driver.title) #断言书写错误,导致case出错 def test_case3(self):
'''设计测试成功的case'''
print ("========【case_0003】 搜索梦雨情殇博客=============")
self.driver.find_element_by_id("kw").clear()
self.driver.find_element_by_id("kw").send_keys(u"梦雨情殇")
self.driver.find_element_by_id('su').click()
time.sleep(2)
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
pic_path = '.\\result\\image\\'+ '2017-07-17\\' + current_time + '.png'
print (pic_path)
self.driver.save_screenshot(pic_path)
self.assertIn('梦雨情殇',self.driver.title) def tearDown(self):
self.driver.quit() if __name__ == "__main__":
'''生成测试报告'''
current_time = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
testunit = unittest.TestSuite() #构建测试套件
testunit.addTest(Baidu("test_case1"))
testunit.addTest(Baidu("test_case2"))
testunit.addTest(Baidu("test_case3"))
report_path = ".\\result\\SoftTestReport_" + current_time + '.html' #生成测试报告的路径
fp = open(report_path, "wb")
runner = HTMLTestReport.HTMLTestRunner(stream=fp, title=u"自动化测试报告",description='自动化测试演示报告',tester='梦雨')
runner.run(testunit)
fp.close()
过程很简单,过程需要理解整个过程,HTMLTestReport代码已经共享,请下载整体工程。
python selenium-webdriver 生成测试报告 (十四)的更多相关文章
- Python+selenium自动化生成测试报告
批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLTest ...
- Python+Selenium+webdriver环境搭建(windows)以及相关资源下载链接
今天记录一下测试小菜鸟alter在测试入门的一点关于python+Selenium+webdriver环境搭建的经历以及资源分享.欢迎交流学习,批评指正. 一.Python的下载与安装 1.pytho ...
- Python Selenium Webdriver常用方法总结
Python Selenium Webdriver常用方法总结 常用方法函数 加载浏览器驱动: webdriver.Firefox() 打开页面:get() 关闭浏览器:quit() 最大化窗口: m ...
- Python之路【第十四篇】:AngularJS --暂无内容-待更新
Python之路[第十四篇]:AngularJS --暂无内容-待更新
- python selenium webdriver入门基本操作
python selenium webdriver入门基本操作 未经作者允许,禁止转载! from selenium import webdriver import time driver=webdr ...
- selenium webdriver学习(十)------------如何把一个元素拖放到另一个元素里面(转)
selenium webdriver学习(十)------------如何把一个元素拖放到另一个元素里面 博客分类: Selenium-webdriver 元素拖放drag and drop Q群里 ...
- python+selenium +unittest生成HTML测试报告
python+selenium+HTMLTestRunner+unittest生成HTML测试报告 首先要准备HTMLTestRunner文件,官网的HTMLTestRunner是python2语法写 ...
- Python脚本控制的WebDriver 常用操作 <十四> 处理button dropdown 的定位
测试用例场景 模拟选择下拉菜单中数据的操作 Python脚本 测试用HTML代码: <html> <body> <form> <select name=&qu ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Python+Selenium WebDriver API:浏览器及元素的常用函数及变量整理总结
由于网页自动化要操作浏览器以及浏览器页面元素,这里笔者就将浏览器及页面元素常用的函数及变量整理总结一下,以供读者在编写网页自动化测试时查阅. from selenium import webdrive ...
随机推荐
- mysql字段添加修改删除
MySQL添加字段和修改字段 MySQL添加字段的方法并不复杂,下面将为您详细介绍MYSQL添加字段和修改字段等操作的实现方法,希望对您学习MySQL添加字段方面会有所帮助. 1添加表字段 alt ...
- python flask大型项目目录
Hello World 作者背景 应用程序简介 要求 安装 Flask 在 Flask 中的 “Hello, World” 下一步? 模板 回顾 为什么我们需要模板 模板从天而降 模板中控制语句 模板 ...
- 爬虫系列3:scrapy技术进阶(xpath、rules、shell等)
本文主要介绍与scrapy应用紧密相关的关键技术,不求很深入,但求能够提取要点.内容包括: 1.xpath选择器:选择页面中想要的内容 2.rules规则:定义爬虫要爬取的域 3.scrapy she ...
- 【MySQL】5.6.x InnoDB Error Table mysql.innodb_table_stats not found
[问题描述]: 检查error log的时候发现大量warnings: [Warning] InnoDB Error Table mysql.innodb_index_stats not found ...
- C#类中字段封装为属性
本文描述内容转载 https://zhidao.baidu.com/question/1174413218458798139.html 感谢 冥冥有你PD 的解答!!! 问题思索1 类成员包括变量和方 ...
- ELF文件加载与动态链接(二)
GOT应该保存的是puts函数的绝对虚地址,这里为什么保存的却是puts@plt的第二条指令呢? 原来“解释器”将动态库载入内存后,并没有直接将函数地址更新到GOT表中,而是在函数第一次被调用时,才会 ...
- Django之模型层-多表操作
多表操作 数据库表关系 一对多:两个表之间的关系一旦确定为一对多,必须在数据多的表中创建关联字段 多对多:两个表之间的关系一定确定为多对多,必须创建第三张表(关联表) 一对一:一旦两个表之间的关系确定 ...
- 双向重定向tee命令详解
vim一般在训练网络的时候需要保存log文件,同时需要在屏幕上网络的输出信息,在shell文件中常常会看到如下代码 执行的命令 2>&1 | tee log.txt tee是linux中 ...
- tomcat:利用tomcat部署war包格式的项目
配置jdk环境变量, 配置TOMCAT_HOME 变量, 将war包放入webapps中. 运行tomcar-bin文件夹中的startup.bat. tomcat会自动解压war包. 进入项目:
- macbook air 获取root权限
以下内容为转载 原创连接:http://blog.itpub.net/26148431/viewspace-1401745/ 1. 从 Apple 菜单中选取系统偏好设置,从显示菜单中选取用户与群组. ...