apache kafka系列之在zookeeper中存储结构
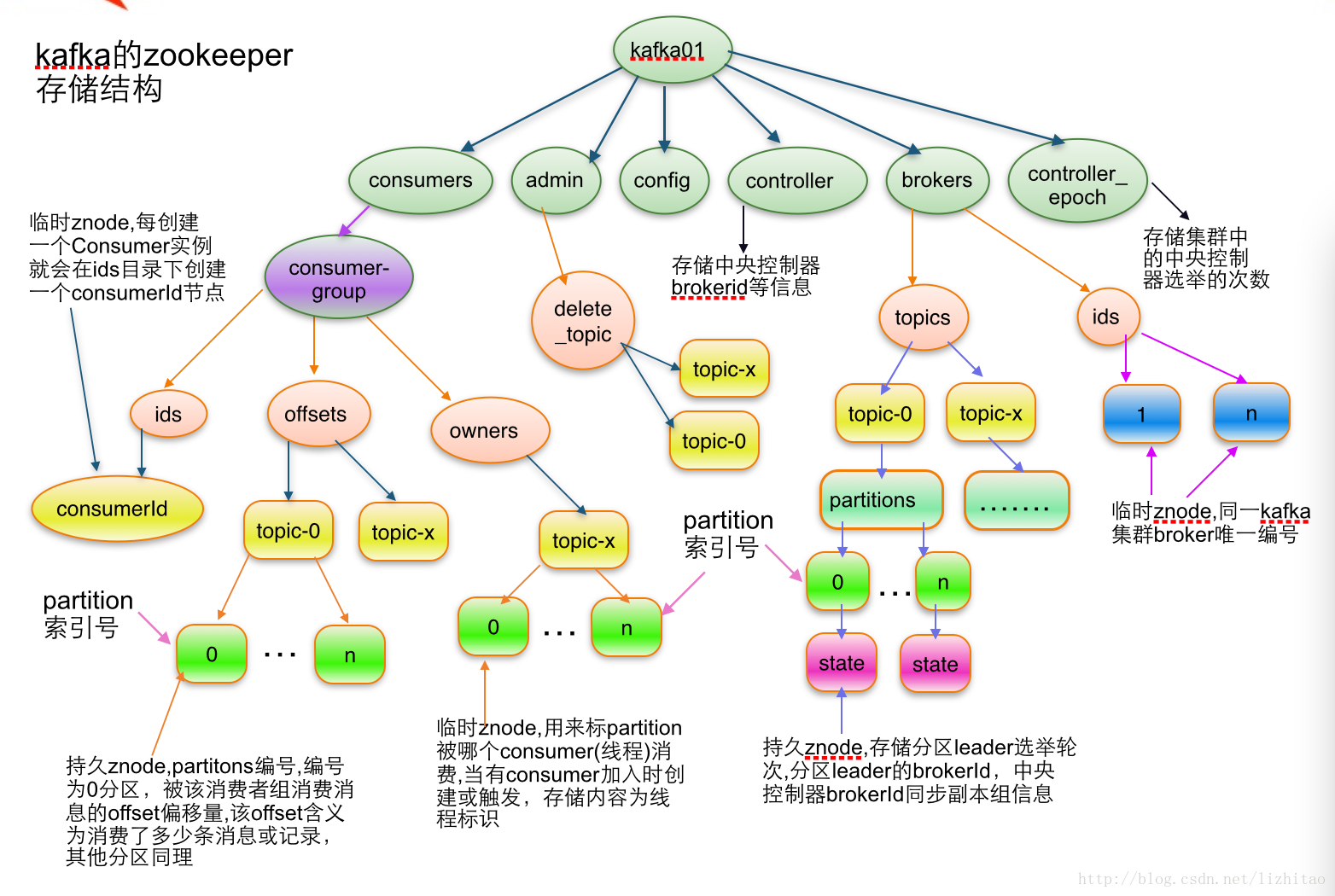
1.topic注册信息
/brokers/topics/[topic] :
存储某个topic的partitions所有分配信息
Schema:{ Example:{
"version": 1, "partitions": { "0": [1, 2], "1": [2, 1], "2": [1, 2], } } 说明:紫红色为patitions编号,蓝色为同步副本组brokerId列表
|
2.partition状态信息
/brokers/topics/[topic]/partitions/[0...N] 其中[0..N]表示partition索引号
/brokers/topics/[topic]/partitions/[partitionId]/state
Schema:{ Example:{ |
3. Broker注册信息
/brokers/ids/[0...N]
每个broker的配置文件中都需要指定一个数字类型的id(全局不可重复),此节点为临时znode(EPHEMERAL)
Schema:{ Example:{ "timestamp":"1403061899859"
"version": 1, "host": "192.168.1.148", "port": 9092 } |
4. Controller epoch:
/controller_epoch -> int (epoch)
此值为一个数字,kafka集群中第一个broker第一次启动时为1,以后只要集群中center controller中央控制器所在broker变更或挂掉,就会重新选举新的center controller,每次center controller变更controller_epoch值就会 + 1;
5. Controller注册信息:
/controller -> int (broker id of the controller) 存储center controller中央控制器所在kafka broker的信息
Schema:{ Example:{ |
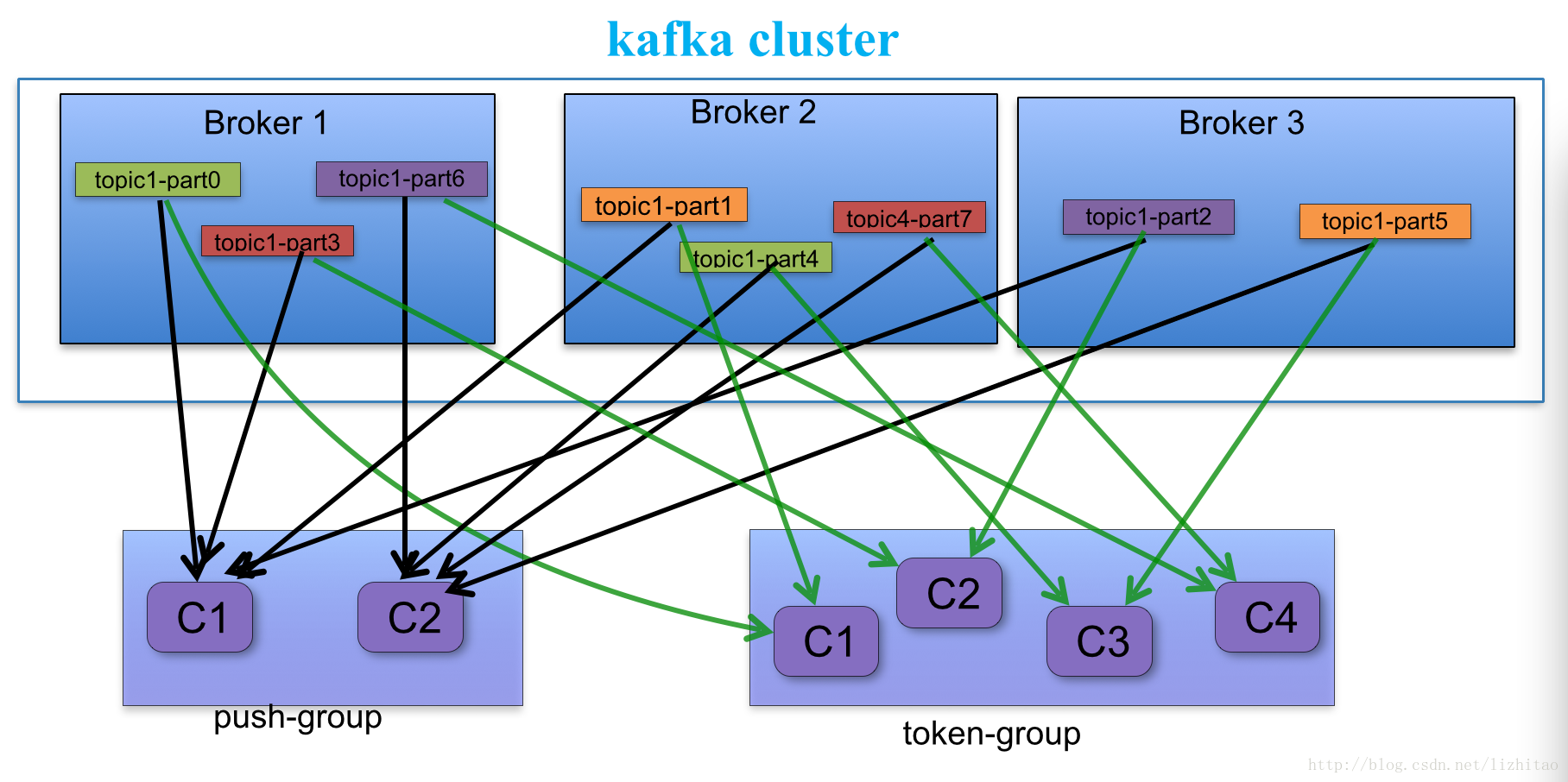
a.每个consumer客户端被创建时,会向zookeeper注册自己的信息;
b.此作用主要是为了"负载均衡".
c.同一个Consumer Group中的Consumers,Kafka将相应Topic中的每个消息只发送给其中一个Consumer。
d.Consumer Group中的每个Consumer读取Topic的一个或多个Partitions,并且是唯一的Consumer;
e.一个Consumer group的多个consumer的所有线程依次有序地消费一个topic的所有partitions,如果Consumer group中所有consumer总线程大于partitions数量,则会出现空闲情况;举例说明:kafka集群中创建一个topic为report-log 4 partitions 索引编号为0,1,2,3假如有目前有三个消费者node:注意-->一个consumer中一个消费线程可以消费一个或多个partition.如果每个consumer创建一个consumer thread线程,各个node消费情况如下,node1消费索引编号为0,1分区,node2费索引编号为2,node3费索引编号为3如果每个consumer创建2个consumer thread线程,各个node消费情况如下(是从consumer node先后启动状态来确定的),node1消费索引编号为0,1分区;node2费索引编号为2,3;node3为空闲状态总结:
从以上可知,Consumer Group中各个consumer是根据先后启动的顺序有序消费一个topic的所有partitions的。如果Consumer Group中所有consumer的总线程数大于partitions数量,则可能consumer thread或consumer会出现空闲状态。
Consumer均衡算法
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力.
1) 假如topic1,具有如下partitions: P0,P1,P2,P3
2) 加入group中,有如下consumer: C0,C1
3) 首先根据partition索引号对partitions排序: P0,P1,P2,P3
4) 根据(consumer.id + '-'+ thread序号)排序: C0,C1
5) 计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
6) 然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
6. Consumer注册信息:
每个consumer都有一个唯一的ID(consumerId可以通过配置文件指定,也可以由系统生成),此id用来标记消费者信息.
/consumers/[groupId]/ids/[consumerIdString]
是一个临时的znode,此节点的值为请看consumerIdString产生规则,即表示此consumer目前所消费的topic + partitions列表.
consumerId产生规则:
StringconsumerUuid = null;
if(config.consumerId!=null && config.consumerId)
consumerUuid = consumerId;
else {
String uuid = UUID.randomUUID()
consumerUuid = "%s-%d-%s".format(
InetAddress.getLocalHost.getHostName, System.currentTimeMillis,
uuid.getMostSignificantBits().toHexString.substring(0,8));
}
String consumerIdString = config.groupId + "_" + consumerUuid;
Schema:{ Example:{
"version": 1, "subscription": { "open_platform_opt_push_plus1": 5 }, "pattern": "static", "timestamp": "1411294187842" } |
7. Consumer owner:
/consumers/[groupId]/owners/[topic]/[partitionId] -> consumerIdString + threadId索引编号
当consumer启动时,所触发的操作:
a) 首先进行"Consumer Id注册";
b) 然后在"Consumer id 注册"节点下注册一个watch用来监听当前group中其他consumer的"退出"和"加入";只要此znode path下节点列表变更,都会触发此group下consumer的负载均衡.(比如一个consumer失效,那么其他consumer接管partitions).
c) 在"Broker id 注册"节点下,注册一个watch用来监听broker的存活情况;如果broker列表变更,将会触发所有的groups下的consumer重新balance.
8. Consumer offset:
/consumers/[groupId]/offsets/[topic]/[partitionId] -> long (offset)
用来跟踪每个consumer目前所消费的partition中最大的offset
此znode为持久节点,可以看出offset跟group_id有关,以表明当消费者组(consumer group)中一个消费者失效,
重新触发balance,其他consumer可以继续消费.
9. Re-assign partitions
/admin/reassign_partitions
{ "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition to be reassigned" }, { "name":"partition", "type":"int", "doc":"the partition to be reassigned" }, { "name":"replicas", "type":"array", "items":"int", "doc":"a list of replica ids" } ], } "doc":"an array of partitions to be reassigned to new replicas" } } ]}Example:{ "version": 1, "partitions": [ { "topic": "Foo", "partition": 1, "replicas": [0, 1, 3] } ] } |
10. Preferred replication election
/admin/preferred_replica_election
{ "fields":[ { "name":"version", "type":"int", "doc":"version id" }, { "name":"partitions", "type":{ "type":"array", "items":{ "fields":[ { "name":"topic", "type":"string", "doc":"topic of the partition for which preferred replica election should be triggered" }, { "name":"partition", "type":"int", "doc":"the partition for which preferred replica election should be triggered" } ], } "doc":"an array of partitions for which preferred replica election should be triggered" } } ]}例子:{ "version": 1, "partitions": [ { "topic": "Foo", "partition": 1 }, { "topic": "Bar", "partition": 0 } ] } |
11. 删除topics
/admin/delete_topics
Schema:{ "fields": [ {"name": "version", "type": "int", "doc": "version id"}, {"name": "topics", "type": { "type": "array", "items": "string", "doc": "an array of topics to be deleted"} } ]}例子:{ "version": 1, "topics": ["foo", "bar"]} |
Topic配置
/config/topics/[topic_name]
例子
{ "version": 1, "config": { "config.a": "x", "config.b": "y", ... }} |
apache kafka系列之在zookeeper中存储结构的更多相关文章
- Kafka在zookeeper中存储结构和查看方式
Zookeeper 主要用来跟踪Kafka 集群中的节点状态, 以及Kafka Topic, message 等等其他信息. 同时, Kafka 依赖于Zookeeper, 没有Zookeeper 是 ...
- kafka在zookeeper中存储结构
1.topic注册信息 /brokers/topics/[topic] : 存储某个topic的partitions所有分配信息 Schema: { "version": ...
- apache kafka系列之Producer处理逻辑
最近研究producer的负载均衡策略,,,,我在librdkafka里边用代码实现了partition 值的轮询方法,,,但是在现场验证时,他的负载均衡不起作用,,,所以来找找原因: 下文是一篇描 ...
- apache kafka系列之-监控指标
apache kafka中国社区QQ群:162272557 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提示 a.短信方式 b.邮件 2.监控内容 2.1 机器监控 ...
- apache kafka系列之客户端开发-java
1.依赖包 <dependency> <groupId>org.apache.kafka</groupId> <a ...
- 【转载】apache kafka系列之-监控指标
原文地址:http://blog.csdn.net/lizhitao/article/details/24581907 1.监控目标 1.当系统可能或处于亚健康状态时及时提醒,预防故障发生 2.报警提 ...
- apache kafka系列之性能优化架构分析
apache kafka中国社区QQ群:162272557 Apache kafka性能优化架构分析 应用程序优化:数据压缩 watermark/2/text/aHR0cDovL2Jsb2cuY3Nk ...
- 【Apache KafKa系列之一】KafKa安装部署
kafka是一种高吞吐量的分布式发布订阅消息系统,她有如下特性: 通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能. 高吞吐量:即使是非常普通的 ...
- apache kafka系列之server.properties配置文件参数说明
每个kafka broker中配置文件server.properties默认必须配置的属性如下: broker.id=0num.network.threads=2num.io.threads=8soc ...
随机推荐
- lxml简单用法 解析网页
import requests s=requests.Session() re=s.get(lgurl,headers=headers) #此处s可以直接换成requests the_page=re ...
- (C/C++学习笔记) 六. 表达式
六. 表达式 ● 表达式 表达式 expression An expression consists of a combination of operators and operands. (An o ...
- ubuntu多显示器单触摸屏校准
多显示器单触摸屏屏幕校准 0.触摸屏重定向 sudo xinput map-to-output 13 DP1 #将触摸屏映射到指定的显示器 其中:13为触摸屏设备id,可通过 xinput命令查看 ...
- Bootstrap中模态框多层嵌套时滚动条问题
在使用Bootstrap中模态框过程中,如果出现多层嵌套的时候,如打开模态框A,然后在A中打开模态框B,在关闭B之后,如果A的内容比较多,滚动条会消失,而变为Body的滚动条,这是由于模态框自带的遮罩 ...
- 缓存一致性协议 mesi
m : modified e : exlusive s : shared i : invalid 四种状态的转换略过,现在讨论为什么有了这个协议,i++在多线程上还不是安全的. 两个cpu A B同时 ...
- Oracle 12c中新建pdb用户登录问题分析
Oracle 12c新建用户登录问题分析1 用sys用户新建用户,提示公用用户名或角色名无效.原因:Oracle 12c中,在容器中建用户(或者应该称为使用者),须在用户名前加c##.默认登录连接的就 ...
- day 关于生成器的函数
def average(): count=0 toatal=0 average=0 while True: value=yield average toatal+=value count+=1 ave ...
- outlook vba开发要点
1.学学基础的VB语法 https://www.yiibai.com/vba/vba_programming_charts.html 2.找一个样例看看 VBA编程实现自动回复邮件 https://b ...
- sql order by 结合case when then
SELECT * FROM datav.a_current_per_entry_01 WHERE intime = (SELECT MAX(intime) FROM a_current_per_ent ...
- Python 内置函数2
print(list("胡辣汤")) lst = ["河南话", "四川话", "东北", "山东" ...