异常检测LOF
局部异常因子算法-Local Outlier Factor(LOF)
在数据挖掘方面,经常需要在做特征工程和模型训练之前对数据进行清洗,剔除无效数据和异常数据。异常检测也是数据挖掘的一个方向,用于反作弊、伪基站、金融诈骗等领域。
异常检测方法,针对不同的数据形式,有不同的实现方法。常用的有基于分布的方法,在上、下α分位点之外的值认为是异常值(例如图1),对于属性值常用此类方法。基于距离的方法,适用于二维或高维坐标体系内异常点的判别,例如二维平面坐标或经纬度空间坐标下异常点识别,可用此类方法。 
这次要介绍一下一种基于密度的异常检测算法,局部异常因子LOF算法(Local Outlier Factor)
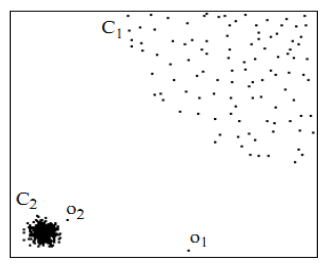
用视觉直观的感受一下,如图2,对于C1集合的点,整体间距,密度,分散情况较为均匀一致,可以认为是同一簇;对于C2集合的点,同样可认为是一簇。o1、o2点相对孤立,可以认为是异常点或离散点。现在的问题是,如何实现算法的通用性,可以满足C1和C2这种密度分散情况迥异的集合的异常点识别。LOF可以实现我们的目标。
下面介绍LOF算法的相关定义:
1) d(p,o):两点p和o之间的距离。
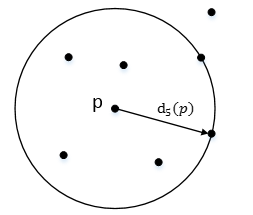
2) k-distance:第k距离
对于点p的第k距离dk(p)定义如下:
dk(p)=d(p,o),并且满足:
a) 在集合中至少有不包括p在内的k个点o' ∈ C{x ≠ p}, 满足d(p,o') ≤ d(p,o) 。
b) 在集合中最多有不包括p在内的k−1个点o' ∈ C{x ≠ p},满足d(p,o') < d(p,o)。
如下图,离p第5远的点在以p为圆心,d5(p)为半径的
点p的第k距离邻域Nk(p),就是p的第k距离即以内的所有点,包括第k距离。
因此p的第k邻域点的个数 |Nk(p)| ≥ k。
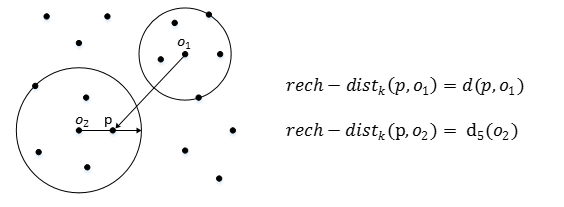
4) reach-distance:可达距离
点o到点p的第k可达距离定义为:reach−distancek(p,o) = max{dk(o), d(p,o)}
也就是,点o到点p的第k可达距离,至少是o的第k距离,或者为o、p间的真实距离。
5) local reachability density:局部可达密度
点p的局部可达密度表示为: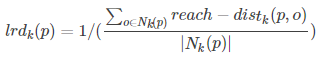 表示点p的第k邻域内的点到p的平均可达距离的倒数。
表示点p的第k邻域内的点到p的平均可达距离的倒数。
6) local outlier factor:局部离群因子
点p的局部离群因子表示为:
表示点p的邻域点Nk(p)的局部可达密度与点p的局部可达密度之比的平均数。
local outlier factor越接近1,说明p的其邻域点密度差不多,p可能和邻域同属一簇;
local outlier factor越小于1,说明p的密度高于其邻域点密度,p为密集点;
local outlier factor越大于1,说明p的密度小于其邻域点密度,p越可能是异常点。
因为LOF对密度的是通过点的第k邻域来计算,而不是全局计算,因此得名为“局部”异常因子,这样,对于图1的两种数据集C1和C2,LOF完全可以正确处理,而不会因为数据密度分散情况不同而错误的将正常点判定为异常点。
转自:https://blog.csdn.net/wangyibo0201/article/details/51705966
异常检测LOF的更多相关文章
- 【R笔记】使用R语言进行异常检测
本文转载自cador<使用R语言进行异常检测> 本文结合R语言,展示了异常检测的案例,主要内容如下: (1)单变量的异常检测 (2)使用LOF(local outlier factor,局 ...
- sklearn异常检测demo
sklearn 异常检测demo代码走读 # 0基础学python,读代码学习python组件api import time import numpy as np import matplotlib ...
- <数据挖掘导论>读书笔记11异常检测
异常检测的目标是发现与大部分其他对象不同的对象.通常,异常对象被称作离群点(Outlier). 异常检测也称偏差检测(Deviation detection),因为异常对象的属性值明显偏离期望的或者常 ...
- 26.异常检测---孤立森林 | one-class SVM
novelty detection:当训练数据中没有离群点,我们的目标是用训练好的模型去检测另外发现的新样本 outlier dection:当训练数据中包含离群点,模型训练时要匹配训练数据的中心样 ...
- 异常检测-基于孤立森林算法Isolation-based Anomaly Detection-1-论文学习
论文http://202.119.32.195/cache/10/03/cs.nju.edu.cn/da2d9bef3c4fd7d2d8c33947231d9708/tkdd11.pdf 1. INT ...
- 【异常检测】孤立森林(Isolation Forest)算法简介
简介 工作的过程中经常会遇到这样一个问题,在构建模型训练数据时,我们很难保证训练数据的纯净度,数据中往往会参杂很多被错误标记噪声数据,而数据的质量决定了最终模型性能的好坏.如果进行人工二次标记,成本会 ...
- 利用KD树进行异常检测
软件安全课程的一次实验,整理之后发出来共享. 什么是KD树 要说KD树,我们得先说一下什么是KNN算法. KNN是k-NearestNeighbor的简称,原理很简单:当你有一堆已经标注好的数据时,你 ...
- 5-Spark高级数据分析-第五章 基于K均值聚类的网络流量异常检测
据我们所知,有‘已知的已知’,有些事,我们知道我们知道:我们也知道,有 ‘已知的未知’,也就是说,有些事,我们现在知道我们不知道.但是,同样存在‘不知的不知’——有些事,我们不知道我们不知道. 上一章 ...
- 异常检测算法--Isolation Forest
南大周志华老师在2010年提出一个异常检测算法Isolation Forest,在工业界很实用,算法效果好,时间效率高,能有效处理高维数据和海量数据,这里对这个算法进行简要总结. iTree 提到森林 ...
随机推荐
- Python 标准输出 sys.stdout 重定向(转)
add by zhj: 其实很少使用sys.stdout,之前django的manage.py命令的源码中使用了sys.stdout和sys.stderr,所以专门查了一下 这两个命令与print的区 ...
- jenkins 下载和安装
jenkins 下载和安装 地址:http://jenkins.io/download/ 下载完成后,点击安装,安装完会发现电脑里多了个jenkins文件夹,打开发现 jenkins.war, 然后点 ...
- nodejs 学习五 单元测试一
一. chai chai 自身是依赖nodejs的 assert,让检测更加语义化. chai 采用两种模式,TDD和BDD, TDD是类似自然语言方式 BDD是结构主义 chai文旦地址 二.moc ...
- (4.1)mysql备份还原——mysql常见故障
(4.1)mysql备份还原——mysql常见故障 1.常见故障类型 在数据库环境中,常见故障类型: 语句失败,用户进程失败,用户错误 实例失败,介质故障,网络故障 其中最严重的故障主要是用户错误和介 ...
- php程序猿面试分享
面试总结 今天去了北京著名IT公司进行PHP程序猿的面试.这是人生第一次么,怎么不紧张?我是不是有病.不是.这叫自信呵. 首先是做一些笔试题. 1.mysql数据库索引使用的数据结构?这样做的优点是? ...
- UICollectionView横向分页
效果图: 代码: HCollectionViewCell.h #import <UIKit/UIKit.h> @interface HCollectionViewCell : UIColl ...
- 【剑指offer】两个链表的第一个公共结点
一.题目: 输入两个链表,找出它们的第一个公共结点. 二.思路: 思路一:模拟数组,进行两次遍历,时间复杂度O(n2) 思路二:假定 List1长度: a+n List2 长度:b+n, 且 a&l ...
- [LeetCode] 598. Range Addition II_Easy tag: Math
做个基本思路可以用 brute force, 但时间复杂度较高. 因为起始值都为0, 所以肯定是左上角的重合的最小的长方形就是结果, 所以我们求x, y 的最小值, 最后返回x*y. Code ...
- electron 前端开发桌面应用
electron是由Github开发,是一个用Html.css.JavaScript来构建桌面应用程序的开源库,可以打包为Mac.Windows.Linux系统下的应用. 快速开始 接下来,让代码来发 ...
- TensorFlow读取CSV数据(批量)
直接上代码: # -*- coding:utf-8 -*- import tensorflow as tf def read_data(file_queue): reader = tf.TextLin ...