目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)
Spatial pyramid pooling in deep convolutional networks for visual recognition
作者: Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun
引用: He, Kaiming, et al. "Spatial pyramid pooling in deep convolutional networks for visual recognition." IEEE transactions on pattern analysis and machine intelligence,37(9) (2015): 1904-1916.
引用次数: 399+120(Google Scholar, By 2016/11/24).
项目地址:
1 介绍
这是何凯明大神2015年在PAMI上发表的论文,在2014年时候已经在ECCV会议上发表过.
原AlexNet中(如图1所示),conv5生成的特征maps数目为256个,大小为13*13,后面紧接着是max-pooling层(pool5层),然后是fc6,fc7的全连接层.对于AlexNet而言,输入图像的大小为224*224,实验的时候无论你图像的大小是多大,都要resize到这个设定的值,这样才能保证后面的一致性.但是这样做有个问题就是有些图像可能与224*224相差很大,强行resize到这个尺寸会有问题,原因有两个: (1)这个值(224*224)的设定是人为的,不一定是最好的;(2)将图像强行resize到这个尺寸可能会破坏图像原本的结构.于是就有了现在这篇文章.

图1 AlexNet网络的结构图
2 SPP-net网络结构
2.1 SPP-net思路介绍
OK,那我们就不对每张输入图像都进行resize,这样保持了图像的原有结构,这是个优点! 但是这样也会带来问题,输入图像什么大小的都有,这样不同尺寸的图像前向传播到pool5层之后(将要进入全连接层时),输出的向量的维度不相同.全连接层的神经元节点数目是固定的,如果pool5之后输出的向量维度不确定,况会使得网络没有办法训练.图像大小虽然不同,但是不影响卷积层和池化层,影响的就是全连接层与最后一个池化层之间的连接,所以我们如果想解决这个问题,就要在pool5这里下功夫(因为它的下一层就是全连接层,如果这一层能对任何尺寸图像都能输出固定长度的特征向量,那全连接层参数不需要改变,其他的啥也都不需要改变)

图2 SPP-net结构
为了解决这个问题,作者提出了使用SPP层来代替网络最后的池化层pool5,使得对于任意尺寸的conv5特征图(输入图像尺寸的不同表现在conv5特征maps大小的不同)经过它之后都能得到固定长度的输出.下面我们来看看是怎么做到的.
其实做法很简单: 输入图像的尺寸不同,导致conv5输出的map尺寸也不同,比如224x224的输出图像的conv5输出map尺寸为13x13,180x180尺寸的输入图像的conv5输出map尺寸为10x10,如何在13x13的map和10x10的map上进行池化,使得池化后得到的向量维度相同呢? 首先:设置3种bin(3种只是举例,你可以设置任意多种),分别是1x1,2x2,4x4,对于1x1的bin,无论对14x14还是10x10,池化后的输出数据维度都是1(它们不同的是前者的池化核大小为14x14,后者为10x10),对于2x2的bin,池化后输出数据维度都是4(它们不同的也是池化核),对于4x4的bin,池化后输出数据的维度都是16(它们不同的也是池化核大小),所以无论你conv5后的map大小是多少,在一张map上池化后得到的向量维度都是1+4+16=21,这就得到了我们的目的:对不同大小的输入图像得到定长输出!!!
虽然对不同尺寸的输入图像,多级池化后的输出向量维度是相同的,但是池化的时候对不同的图像采用的池化核大小和步长却是要自适应改变的,这点很重要,否则无法进行下去,下面来讲述如何根据map尺寸来计算池化核大小与步长来满足要求:
bin的size(在一张map上等距划分的网格的数目)可以设置为n*n: 1*1,2*2,3*3,4*4,...
conv5的map大小为a*a,比如13*13,map数目为256个
这样:
(1) n=1 --> win=ceil(a/n)=ceil(13/1)=13,str=floor(13/1)=13 --> 输出256*1*1维度的向量
(2) n=2 --> win=ceil(a/n)=ceil(13/2)=7,str=floor(13/2)=6 --> 输出256*2*2维度的向量
(3) n=3 --> win=ceil(a/n)=ceil(13/3)=5,str=floor(13/3)=4 --> 输出256*3*3维度的向量
(3) n=4 --> win=ceil(a/n)=ceil(13/4)=4,str=floor(13/4)=3 --> 输出256*4*4维度的向量
其中: ceil(1/3)=1; ceil(2/3)=1; floor(1/3)=0; floor(2/3)=0;
下图展示了一个三级的金字塔池化(3x3,2x2,1x1),sizeX为池化核大小,stride为池化时的步长;

可以设置多种bin,每个bin的大小可以设置为1x1或2x2或3x3或4x4,...,
2.2 多尺寸输入图像情况下的训练
面对多尺寸问题时,采用交替训练的方式,比如第一个epoch采用224x224大小的训练图像对Net1进行训练,第二个epoch的时候改用180x180大小的图像对Net2进行训练! 依次类推.这里要问,问什么会有两个Net? 其实它们可以看做是一个,两者的差别很小,Net2的初始权重会使用上一次epoch得到的Net1的权重(同样,再下一次迭代Net1也要使用上次epoch得到的Net2的权重作为初始权重),这些权重包括SPP之前的那些卷积层的kernel权重值,以及SPP之后的全连接层的权重值!那么Net1和Net2有什么区别呢? 还是有点小小的区别的,假设金字塔级数设置为3级,就有3种bin,分别是1x1,2x2,4x4,那么有:
(1) 当224x224大小的图像进来后,conv5之后的map大小为13x13,这时程序会根据这个map大小以及设置的三种bin来计算每种bin下对应的卷积核大小和步长,假设写成(sizeX,stride),那么对于这种图像尺寸,计算出来的池化卷积核大小和步长对就是(13,13),(7,6),(5,4),用这三个对conv5层的卷积maps进行三种池化,得到输出向量长度为256*(1*1+2*2+4*4)=5376(其中256为conv5后得到的map数目);
(2) 当180x180大小的图像进来后,conv5之后的map大小为10x10,这时程序会根据这个map大小以及设置的三种bin来计算每种bin下对应的卷积核大小和步长,假设写成(sizeX,stride),那么对于这种图像尺寸,计算出来的池化卷积核大小和步长对就是(10,10),(5,5),(4,3),用这三个对conv5层的卷积maps进行三种池化,得到输出向量长度为256*(1*1+2*2+4*4)=5376(其中256为conv5后得到的map数目);
每次迭代的时候用一种不同大小的输入图像,Net1和Net2唯一的不同就是SPP层的三个池化核的尺寸和步长的不同,其他的都是继承了上次迭代的权重参数作为初始参数,由于池化核本身是不带学习参数的,因此这种方式对训练没有影响(还是按照一般的方式进行训练).实际训练时,其实也只是训练一个网络,只是在SPP层的时候,要根据当前迭代时的输入图像大小实时调整三种池化核尺寸和步长罢了.
2.3 SPP-net用于目标检测
SPP-net还可以用于目标检测,具体见原文中的第四章.
2.3.1 SPP-net训练集构造
输入样本: 20个目标的训练图像(对于VOC数据集而言)
正样本: 采用的是图像上待检测目标的GT boxes.
负样本: 用Selective Search的方法在每张图像上生成2000个候选区域,考量每个候选区域与GT box之间的IoU,IoU最多为30%的区域标定为负样本.同时,如果两个负样本之间的IoU超过了70%,则要把其中的一个去掉(很像Selective Search论文里面的做法)
对网络进行微调:
对CNN网络进行微调的时候,仅仅对SPP-net后面的全连接层进行微调,微调时候的正样本为: IoU≥0.5的候选区域; 负样本为: IoU介于[0.1,0.5]之间的候选区域;每个mini-batch里面的正负样本比例为1:3,共训练了250K个mini-batches.
我这里为什么把训练集分割三部分,这个下面会讲到!
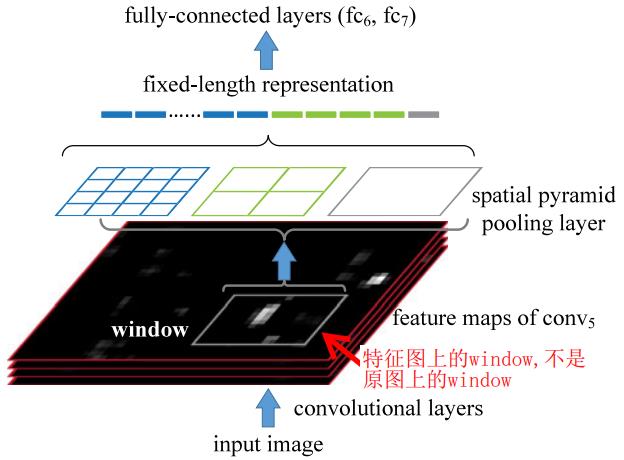
2.3.2 模型训练和测试过程
训练SPP-net
输入20个类别的训练图像(以VOC为例,为输入样本) --> 每张图像都resize到min(w,h)=s (resize之后图像的最短边等于s) --> 前向传播,得到conv5后的卷积maps为256*13*13(假设) --> 将正样本和负样本的候选区域都映射到conv5的特征maps上 --> 提取每个映射后区域的多级池化特征 --> 送入全连接层, 再接Softmax --> 反向传播,迭代多次进行训练,得到一个SPP-net.
训练多个二分类SVM
在conv5的特征maps上,所有正样本和负样本都映射过来了 --> 的每一类的特征 --> 训练20个二分类SVM
参考文献:
[1] RCNN学习笔记(3): From RCNN to SPP-net: http://blog.csdn.net/smf0504/article/details/52744971
目标检测--Spatial pyramid pooling in deep convolutional networks for visual recognition(PAMI, 2015)的更多相关文章
- Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition Kaiming He, Xiangyu Zh ...
- 深度学习论文翻译解析(九):Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
论文标题:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition 标题翻译:用于视觉识别的深度卷积神 ...
- SPPNet论文翻译-空间金字塔池化Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
http://www.dengfanxin.cn/?p=403 原文地址 我对物体检测的一篇重要著作SPPNet的论文的主要部分进行了翻译工作.SPPNet的初衷非常明晰,就是希望网络对输入的尺寸更加 ...
- 论文阅读笔记二十五:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition(SPPNet CVPR2014)
论文源址:https://arxiv.org/abs/1406.4729 tensorflow相关代码:https://github.com/peace195/sppnet 摘要 深度卷积网络需要输入 ...
- SPP Net(Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)论文理解
论文地址:https://arxiv.org/pdf/1406.4729.pdf 论文翻译请移步:http://www.dengfanxin.cn/?p=403 一.背景: 传统的CNN要求输入图像尺 ...
- 论文解读2——Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
背景 用ConvNet方法解决图像分类.检测问题成为热潮,但这些方法都需要先把图片resize到固定的w*h,再丢进网络里,图片经过resize可能会丢失一些信息.论文作者发明了SPP pooling ...
- SPP NET (Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition)
1. https://www.cnblogs.com/gongxijun/p/7172134.html (SPP 原理) 2.https://www.cnblogs.com/chaofn/p/9305 ...
- 目标检测(二)SSPnet--Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognotion
作者:Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun 以前的CNNs都要求输入图像尺寸固定,这种硬性要求也许会降低识别任意尺寸图像的准确度. ...
- 目标检测--Scalable Object Detection using Deep Neural Networks(CVPR 2014)
Scalable Object Detection using Deep Neural Networks 作者: Dumitru Erhan, Christian Szegedy, Alexander ...
随机推荐
- http和https的作用与区别
PS: https就是http和TCP之间有一层SSL层,这一层的实际作用是防止钓鱼和加密.防止钓鱼通过网站的证书,网站必须有CA证书,证书类似于一个解密的签名.另外是加密,加密需要一个密钥交换算法, ...
- javascript面向对象精要第五章继承整理精要
javascript中使用原型链支持继承,当一个对象的[prototype]设置为另一个对象时, 就在这两个对象之间创建了一条原型对象链.如果要创建一个继承自其它对象的对象, 使用Object.cre ...
- The 2016 ACM-ICPC Asia Beijing Regional Contest E - What a Ridiculous Election
https://vjudge.net/contest/259447#problem/E bfs,k个限制条件以数组的额外k维呈现. #include <bits/stdc++.h> usi ...
- (stack)Train Problem I hdu1022
Train Problem I Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- [python网络编程]使用scapy修改源IP发送请求
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- python---RabbitMQ(3)exchange中关键字发送direct(组播)
设置关键字,交换机根据消费者传递的关键字判断是否与生产者的一致,一致则将数据传递给消费者 可以实现对消息分组 生产者: # coding:utf8 # __author: Administrator ...
- iframe伪造ajax
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- plt.scatter(X[0, :], X[1, :], c=Y, s=40, cmap=plt.cm.Spectral)出错
ValueError: c of shape (1, 400) not acceptable as a color sequence for x with size 400, y with size ...
- Centos下新建用户及修改用户目录
Centos下新建用户及修改用户目录 Hillgo 关注 2015.09.22 01:32* 字数 154 阅读 3492评论 0喜欢 3 添加及删除用户 添加用户 test: adduser tes ...
- quartz定时任务-job
1,首先添加对quartz组建的引用 quartz-2.2.3.jar,slf4j-api-1.7.7.jar https://files.cnblogs.com/files/renjing/quar ...