数据挖掘之Slope One
计算偏差:
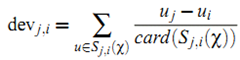
card() 表示集合包含的元素数量。
http://www.cnblogs.com/similarface/p/5385176.html
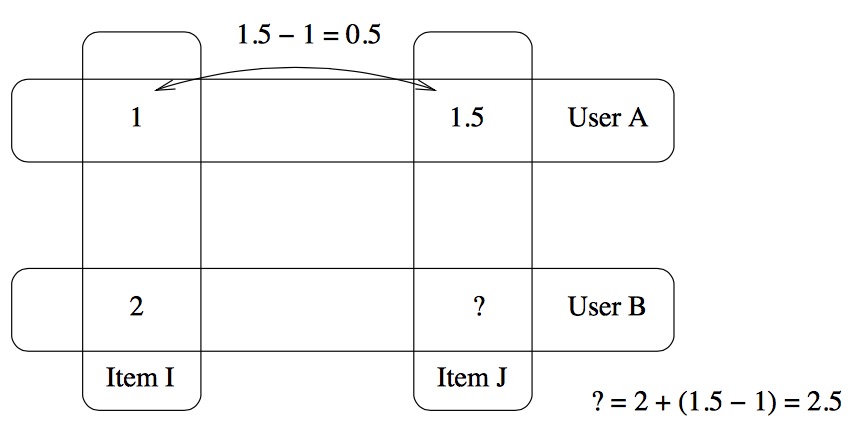
论文地址:http://lemire.me/fr/documents/publications/lemiremaclachlan_sdm05.pdf
dev[itemI,itemJ]=[1.5-1]/1=0.5 这就是偏差
加权Slope One算法
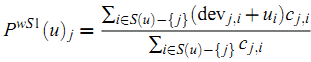
p(u)=(0.5+2)*1/1=2.5
演绎:
| 倩女幽魂 | 新白娘子传奇 | 白发魔女传 | |
| 邓紫棋 | 4 | 3 | 4 |
| 赵丽颖 | 5 | 2 | ? |
| Angelababy | ? | 3.5 | 4 |
| 5 | ? | 3 |
step1:计算偏差矩阵
| 倩女幽魂 | 新白娘子传奇 | 白发魔女传 | |
| 倩女幽魂 | 0 | ||
| 新白娘子传奇 | 0 | ||
| 白发魔女传 | 0 |
#[新白娘子传奇]到[倩女幽魂]的评分偏
dev(新白娘子传奇,倩女幽魂)=[(3-4)+(2-5)]/2=-2 {注:分母2表示同时对新白娘子传奇,倩女幽魂评分的用户数}
#[倩女幽魂]到[新白娘子传奇]的评分偏差
dev(倩女幽魂,新白娘子传奇)=[(4-3)+(5-2)]/2=2
dev(白发魔女传,新白娘子传奇)=[(4-3)+(4-3.5)]/2=0.75
dev(白发魔女传,倩女幽魂)=[(4-4)+(3-5)]/2=-1
得到偏差矩阵:
| 倩女幽魂 | 新白娘子传奇 | 白发魔女传 | |
| 倩女幽魂 | 0 | 2 | 1 |
| 新白娘子传奇 | -2 | 0 | -0.75 |
| 白发魔女传 | -1 | 0.75 | 0 |
step2:利用加权Slope One进行预测
同时对i,j评分的集合
分母表示对所有除j之外用户u打过分的集合
目标: 预测[波多野结衣]对[新白娘子传奇]的评分?
倩女幽魂 新白娘子传奇 白发魔女传
波多野结衣 5 ? 3
1. 波多野结衣 看来很喜欢“倩女幽魂” 给了5分
u(i)=5
2. 波多野结衣 她还没有看过“白娘子”,“新白娘子传奇”到“倩女幽魂” 的偏差是2
dev(j,i)=-2
3. “新白娘子传奇”和“倩女幽魂”有两个人看,哦,她们是邓紫棋 赵丽颖
c(j,i)=2
4. (dev(j,i)+u(i))*c(j,i)=(-2+5)*2=6
5. "波多野结衣" 还看了"白发魔女传" 原来绝技是学的这人的
u(白发魔女传)=3
6. “新白娘子传奇”到“白发魔女传” 的偏差是
dev(白发魔女传,新白娘子传奇)=-0.75
7. (dev(白发魔女传,新白娘子传奇)+u(白发魔女传))*2=(-0.75+3)*2=3.75*2=4.5
8. 纳尼终于 fenzi=6+4.5
9. 分母 对于每一个波多野结衣评过分的电影["白发魔女传","倩女幽魂"],同时对上集合和预测电影都评分的用户数的总和
"波多野结衣" 评分过2个电影 ["白发魔女传","倩女幽魂"]
"白发魔女传"+"新白娘子传奇" = 2
"倩女幽魂"+"新白娘子传奇" = 2
于是分母=2+2=4
10 result(波多野结衣,新白娘子传奇)=10.5/4=2.625
# coding:utf-8
__author__ = 'similarface'
'''
该数据:
{"用户":{"电影":评分}}
'''
users3 = {u"邓紫棋": {u"倩女幽魂": 4, u"新白娘子传奇": 3, u"白发魔女传": 4},
u"赵丽颖": {u"倩女幽魂": 5, u"新白娘子传奇": 2},
u"Angelababy": {u"新白娘子传奇": 3.5, u"白发魔女传": 4},
u"波多野结衣": {u"倩女幽魂": 5, u"白发魔女传": 3}} users2 = {"dzq": {"qnyh": 4, "xbnzcq": 3, "bfmnz": 4},
"zly": {"qnyh": 5, "xbnzcq": 2},
"Angelababy": {"xbnzcq": 3.5, "bfmnz": 4},
"bdyjy": {"qnyh": 5, "bfmnz": 3}} class recommender:
def __init__(self, data, k=1, n=5):
self.k = k
self.n = n
self.productid2name = {}
if type(data).__name__ == 'dict':
self.data = data
#频率值 同时对A,B都进行评分的用户数目
self.frequencies={}
#样本A对样本B的偏差值
self.deviations={}
def computerDeviation(self):
'''
计算样本间的偏差
:return:
'''
#{"用户":{"电影":评分1,"电影":评分2,"电影n":评分n}} =》 ratings={"电影":评分}
for ratings in self.data.values():
#"电影n":评分n
for (item,rating) in ratings.items():
#频率值 2样本同时都进行评分的用户数目
#setdefault 如果键在字典中,返回这个键所对应的值。如果键不在字典中,向字典 中插入这个键,并且以{}为这个键的值,并返回{}
self.frequencies.setdefault(item, {})
#偏差值
self.deviations.setdefault(item, {})
for (item2,rating2) in ratings.items():
if item!=item2:
self.frequencies[item].setdefault(item2,0)
self.deviations[item].setdefault(item2,0.0)
self.frequencies[item][item2]+=1
self.deviations[item][item2]+=rating-rating2
for (item,ratings) in self.deviations.items():
for item2 in ratings:
#dev(i,j)
ratings[item2]/=self.frequencies[item][item2] def slopeOneRecommendations(self,userRatings):
'''
遍历用户u评论的所有样本:u[i]
遍历用户u的偏差矩阵: dev[j,i]
SUM((dev[j,i]+u[i])*c[j,i]) ==?c[j,i]=frequencies[j][i]
:param userRatings:
:return:
'''
recommendations={}
frequencies={}
#遍历用户u k 和 评分
for (useritem,userRating) in userRatings.items():
#遍历偏差矩阵
for (diffItem,diffRatting) in self.deviations.items():
#如果偏差矩阵的key不在用户的key中 用户的key在偏差[key]中 [新白娘子传奇 不在用户的评分中 and ["倩女幽魂","白发魔女传"] 在diffItem
if diffItem not in userRatings and useritem in self.deviations[diffItem]:
#“新白娘子传奇”和“倩女幽魂”有两个人看,哦,她们是邓紫棋 赵丽颖
freq=self.frequencies[diffItem][useritem]
#
recommendations.setdefault(diffItem,0.0)
frequencies.setdefault(diffItem,0)
#(dev(j,i)+u(i))*c(j,i)
recommendations[diffItem]+=(diffRatting[useritem]+userRating)*freq
#求分母的和
frequencies[diffItem]+=freq
recommendations=[(k,v /frequencies[k]) for k ,v in recommendations.items()]
recommendations.sort(key=lambda artistTuple:artistTuple[1],reverse=True)
return recommendations if __name__ == '__main__':
r=recommender(users2)
r.computerDeviation()
g=users2['bdyjy']
result=r.slopeOneRecommendations(g)
print(result[0][0]+' 预测评分'+str(result[0][1]))
预测[波多野结衣]对[新白娘子传奇]的评分是2.625
新白娘子传奇 预测评分2.625
Slope One 的算法复杂度
设有“n”个项目,“m”个用户,“N”个评分。计算每对评分之间的差值需要n(n-1)/2 单位的存储空间,最多需要 m n2步. 计算量也有可能挺悲观的:假设用户已经评价了最多 y 个项目, 那么计算不超过n2+my2个项目间计算差值是可能的。 . 如果一个用户已经评价过“x”个项目,预测单一的项目评分需要“x“步,而对其所有未评分项目做出评分预测需要最多 (n-x)x 步. 当一个用户已经评价过“x”个项目时,当该用户新增一个评价时,更新数据库需要 x步.
数据挖掘之Slope One的更多相关文章
- 机器学习&数据挖掘笔记_14(GMM-HMM语音识别简单理解)
为了对GMM-HMM在语音识别上的应用有个宏观认识,花了些时间读了下HTK(用htk完成简单的孤立词识别)的部分源码,对该算法总算有了点大概认识,达到了预期我想要的.不得不说,网络上关于语音识别的通俗 ...
- 常见的机器学习&数据挖掘知识点
原文:http://blog.csdn.net/heyongluoyao8/article/details/47840255 常见的机器学习&数据挖掘知识点 转载请说明出处 Basis(基础) ...
- 跟我一起数据挖掘(23)——C4.5
C4.5简介 C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法.它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类.C4.5的目 ...
- ITTC数据挖掘平台介绍(四) 框架改进和新功能
本数据挖掘框架在这几个月的时间内,有了进一步的功能增强 一. 超大网络的画布显示虚拟化 如前几节所述,框架采用了三级层次实现,分别是数据,抽象Node和绘图的DataPoint,结构如下: ...
- ITTC数据挖掘平台介绍(五) 数据导入导出向导和报告生成
一. 前言 经过了一个多月的努力,软件系统又添加了不少新功能.这些功能包括非常实用的数据导入导出,对触摸进行优化的画布和画笔工具,以及对一些智能分析的报告生成模块等.进一步加强了平台系统级的功能. 马 ...
- ITTC数据挖掘系统(六)批量任务,数据查看器和自由文档
这一次带来了一系列新特新,同时我们将会从商业智能的角度讨论软件的需求 一. 批量任务向导 一个常用的需求是完成处理多个任务,可能是同一个需求以不同的参数完成多次,这类似批量分析某一问题:或者是不同的需 ...
- ITTC数据挖掘平台介绍(七)强化的数据库, 虚拟化,脚本编辑器
一. 前言 好久没有更新博客了,最近一直在忙着找工作,目前差不多尘埃落定.特别期待而且准备的都很少能成功,反而是没怎么在意的最终反而能拿到,真是神一样的人生. 言归正传,一直以来,数据挖掘系统的数据类 ...
- NLP&数据挖掘基础知识
Basis(基础): SSE(Sum of Squared Error, 平方误差和) SAE(Sum of Absolute Error, 绝对误差和) SRE(Sum of Relative Er ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
随机推荐
- DOS的一些常用命令
原文发布时间为:2011-02-12 -- 来源于本人的百度文章 [由搬家工具导入] DOS远程桌面连接命令 mstsc /v: 192.168.1.250 /console cmd 运 ...
- python fromkeys的坑
有个不定长的列表,想把列表中的每个值当做字典的key, 初始值为空列表,于是想到了fromkeys这个方法 In [337]: l = ['a','b','c'] In [338]: res = di ...
- js链式调用 柯里化
var d = 1; d.add(2).add(3).add(4) //输出10 写出这个add函数 Number.prototype.add = function(x){ return this + ...
- Java爬虫系列之实战:爬取酷狗音乐网 TOP500 的歌曲(附源码)
在前面分享的两篇随笔中分别介绍了HttpClient和Jsoup以及简单的代码案例: Java爬虫系列二:使用HttpClient抓取页面HTML Java爬虫系列三:使用Jsoup解析HTML 今天 ...
- 使用 Jmeter 做 Web 接口测试-详解
接口测试概述 定义 WIKI定义:接口测试作为集成测 试的一部分,通过直接控制API来判断系统的功能性,可靠性,性能与安全性.API测试是没有界面的,执行在通讯 层.API 测试在自动化测试中有着重要 ...
- GLB串
题目描述 只要一个字符串中包含大写“GLB”,高老板就认为这是一个GLB串.现在给你一些字符串,请你帮高老板判断这些字符串是不是GLB串. 输入 首先是一个整数T,表示T行数据,每行一个字符串(只包括 ...
- 某考试 T3 C
找不着原题了. 原题大概就是给你一条直线上n个点需要被覆盖的最小次数和m条需要花费1的线段的左右端点和1条[1,n]的每次花费为t的大线段. 问最小花费使得所有点的覆盖数都达到最小覆盖数. 感觉这个函 ...
- Windows远程命令执行0day漏洞安全预警
网站安全云检测这不是腾讯公司的官方邮件. 为了保护邮箱安全,内容中的图片未被显示. 显示图片 信任此发件人的图片 一.概要 Shadow Brokers泄露多个Windows 远程漏洞利用工具 ...
- 基于Tiny4412的I2C驱动分析
本文以tiny4412平台上到三轴加速度器为例简单分析了Linux下到i2c驱动编程. http://pan.baidu.com/s/1c0H5vRq
- IOS7开发~API变化
1.弃用 MKOverlayView 及其子类,使用类 MKOverlayRenderer: 2.弃用 Audio Toolbox framework 中的 AudioSession API,使用AV ...