3.4-3.6 依据业务需求分析HBase的表设计
一、依据[话单]查询需求分析HBase的表设计
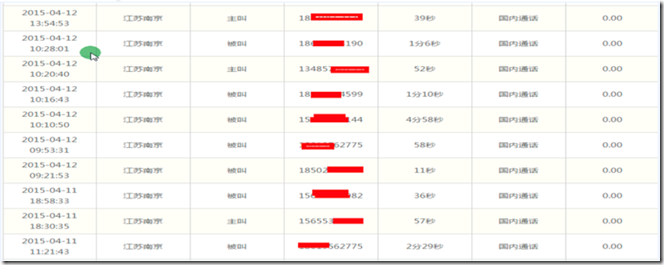
1、分析
用户需要进行实时的查询,那么这些数据是放在HBase当中的,每个客户每天接打电话至少20个左右,而通信公司拥有很多用户,每天产生的数据都是上亿条。
提取出需要的信息,主要包括以下几点:
自己的号码:telphone
拨打或接听时间:teltime
区域:area
主叫或被叫:active
对方的号码:phone
通话时长:talktime
通话模式(国内或国外):mode
费用:price
而大部分功能的查询条件分析如下:
telphone +(starttime - endtime),条件是:号码+开始时间——结束时间
2、设计Rowkey
条件在上一章提过:号码+开始时间——结束时间,那么设计Rowkey就是telphone(电话号码)+teltime(通话时间)
在表的Rowkey设计中:
核心思想:
依据Rowkey查询最快
在实际的应用当中,就是对Rowkey进行范围查询range,Rowkey通常都是多个字段组成的。
Rowkey是前缀匹配的
二、查询固定时间段,接到固定电话的次数
1、分析
新的需求(话单数据的查询) phone + time >>> 依据前面设计的表
使用filter
columnFilter ==========================================================
索引表/辅助表(主表) -- 功能 phone_time
比如:
182600937645_2015100100000 182600937645_2015102400000
列簇:info
列:
rowkey -> Get最快的数据查询 =========================================================
主表和索引表的数据 如何同步呢?????
>> 程序,事物
>> phoenix:Phoenix 基于Hbase给面向业务的开发人员提供了以标准SQL的方式对Hbase进行查询操作
>> JDBC方式,才能同步
创建索引表
>> solr
lily
cloudera search
3.4-3.6 依据业务需求分析HBase的表设计的更多相关文章
- HBase概念学习(八)开发一个类twitter系统之表设计
这边文章先将可能的需求分析一下,设计出HBase表,下一步再開始编写client代码. TwiBase系统 1.背景 为了加深HBase基本概念的学习,參考HBase实战这本书实际动手做了这个样例. ...
- HBase(八): 表结构设计优化
在 HBase(六): HBase体系结构剖析(上) 介绍过,Hbase创建表时,只需指定表名和至少一个列族,基于HBase表结构的设计优化主要是基于列族级别的属性配置,如下图: 目录: BLOOMF ...
- hbase snapshot 表备份/恢复
snapshot其实就是一组metadata信息的集合,它可以让管理员将表恢复到以前的一个状态.snapshot并不是一份拷贝,它只是一个文件名的列表,并不拷贝数据.一个全的snapshot恢复以为着 ...
- HBase之六:HBase的RowKey设计
数据模型 我们可以将一个表想象成一个大的映射关系,通过行健.行健+时间戳或行键+列(列族:列修饰符),就可以定位特定数据,Hbase是稀疏存储数据的,因此某些列可以是空白的, Row Key Time ...
- HBase原理、设计与优化实践
转自:http://www.open-open.com/lib/view/open1449891885004.html 1.HBase 简介 HBase —— Hadoop Database的简称,G ...
- 1 CRM需求分析,数据库表,录入数据
1.需求分析 CRM客户关系管理软件---> 学员管理 用户:企业内部用户 用户量: 业务场景: 2.数据库表设计 1 .表之间的对应关系 from django.db import model ...
- Hbase的rowkey设计
HBase的rowKey设计技巧 1.设计宗旨与目标 主要目的就是针对特定的业务模型,按照rowKey进行预分区设计,使之后面加入的数据能够尽可能的分散于不同的rowKey中.比如复合RowKey. ...
- 架构师必备:HBase行键设计与应用
首先要回答一个问题,为何要使用HBase? 随着业务不断发展.数据量不断增大,MySQL数据库存在这些问题: MySQL支持的数据量为TB级,不能一直保留历史数据.而HBase支持的数据量为PB级,适 ...
- MapReduce和Spark写入Hbase多表总结
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 大家都知道用mapreduce或者spark写入已知的hbase中的表时,直接在mapreduc ...
随机推荐
- 1.新手上路:Windows下,配置Qt环境
个人体会: 我最初只是想看看C++除了"黑窗口"之外,怎么才能做一些"更好看的东西".之后在网上看到有人推荐Qt,就看了一下官网(https://www.qt. ...
- YARN和MapReduce的内存设置參考
怎样确定Yarn中容器Container,Mapreduce相关參数的内存设置,对于初始集群,由于不知道集群的类型(如cpu密集.内存密集)我们须要依据经验提供给我们一个參考配置值,来作为基础的配置. ...
- sql中in/not in 和exists/not exists的使用方法差别
1:首先来说in/not in的使用方法 in/not in是确定单个属性的值是否和给定的值或子查询的值相匹配: select * from Student s where s.id in(1,2,3 ...
- 关于TCP通信程序中数据的传递格式
前言 在之前的回射程序中,实现了字符串的传递与回射.幸运的是,字符串的传递不用担心不同计算机类型的大小端匹配问题,然而,如果传递二进制数据,这就是一个要好好考虑的问题.在客户端和服务器使用不同的字节序 ...
- UNIX网络编程卷1 时间获取程序client TCP 使用非堵塞connect
本文为senlie原创,转载请保留此地址:http://blog.csdn.net/zhengsenlie 1.当在一个非堵塞的 TCP 套接字(可使用 fcntl 把套接字变成非堵塞的)上调用 co ...
- 自定义 spinner
http://blog.sina.com.cn/s/blog_3e333c4a010151cj.html
- Extjs-树 Ext.tree.TreePanel 动态加载数据
先上效果图 1.说明Ext.tree.Panel 控件是树形控件,大家知道树形结构在软件开发过程中的应用是很广泛的,树形控件的数据有本地数据.服务器端返回的数据两种.对于本地数据的加载,在extjs的 ...
- Object/Relational Mapping 数学关系 反面向对象
[hibernate ORM 是对象关系映射框架 事实上的持久化存储引擎] http://docs.jboss.org/hibernate/orm/5.2/userguide/html_single/ ...
- EL表达式 介绍
EL表达式 1.EL简介 1)语法结构 ${expression} 2)[]与.运算符 EL 提供.和[]两种运算符来存取数据. 当要存取的属性名称中包含一 ...
- 查看ubuntu磁盘空间占用及占用空间大的文件
最近老是收到 ecs上有台服务器的磁盘利用率高 终于有一天 ssh登不上去了 http://blog.csdn.net/aaashen/article/details/50685988 清除相关大文件 ...