kafka术语
kafka 架构Terminology(术语)
- broker(代理)
- Kafka集群包含一个或多个服务器,这种服务器被称为broker
- Topic
- 每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic(可以理解为队列queue或者目录)。物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处。
- Partition
- Parition是物理上的概念(可以理解为文件夹),每个Topic包含一个或多个Partition。
- Producer
- 生产者,负责发布消息到Kafka broker。
- Consumer
- 消息消费者,向Kafka broker读取消息的客户端。
- Consumer Group
- 每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
Kafka拓扑结构
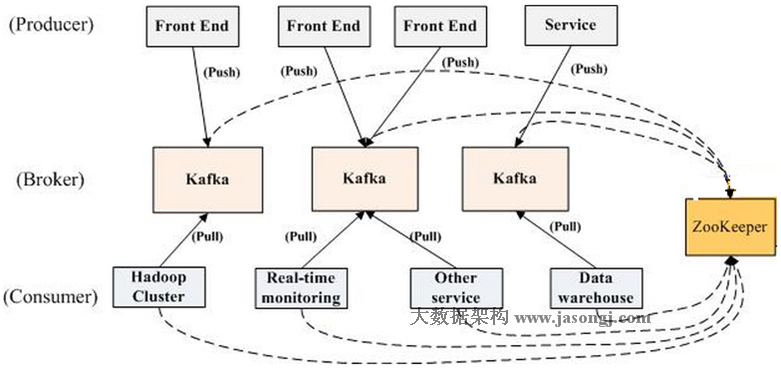
Topic & Partition
topic可以看成不同消息的类别或者信息流,不同的消息根据就是通过不同的topic进行分类或者汇总,然后producer将不同分类的消息发往不同的topic。对于每一个topic,kafka集群维护一个分区的日志:如图所示:
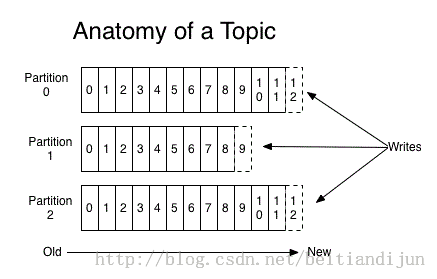
上图中可以看出,每个partition中的消息序列都是有序的,并且不可更改,这些分区可以在尾部不停的追加消息。同一分区中的不同消息都会分配一个唯一的数字进行标识,这个数字被称为offset,用来进行消息的区分,每一条消息都是由若干个字节构成。
kafka集群可以保存所有发布的消息---无论消息是否consumed,保存时间是可配置的。例如,如果日志保存时间设置为两天,则从日志保存之时开始,两天之内都是可供消费的,然而两天之后消息会被抛弃以释放空间。因此,Kafka可以高效持久的保存大量的数据。
事实上,每个消费者所需要保存的元数据只有一个,即”offset“,即主要用来记录日志中当前consume的位置。offset是由consumer所控制的: 通常情况下,offset会随着consumer阅读消息而线性的递增,好似offset只能被动跟随consumer阅读变化,但实际上,offset完全是由consumer控制的,consumer可以从任何它喜欢的位置consum消息。例如,consumer可以将offset重新设置为先前的值并重新consum数据。
这些特征共同说明: Kafka consumer可以很廉价的进行操作----在不必影响集群和其他consumers的情况下,consumers可以很自由的来去。例如,你可以使用kafka提供的命令行工具,去追踪任何topic的内容,而不必改变当前consumers 所consum的topic内容。
日志服务器中存在partitions有以下若干目的:
- 多个分区的共存可以使日志规模超过单个server的尺寸;需要注意的是,每一个单独的分区必须符合所在servers的尺寸,即同一个topic的同一个partition的数据只能在同一台server上存储,也就是说同一个topic下的同一个partition的数据不能同时存放于两台server上,但是同一个topic可以包含很多partitions,这样就使同一个topic可以包含任意数量的数据,理论上你可以通过增加server的数目来增加partitions的数目。
- 多个partitions的存在,可以作为数据并行处理的单位,而不是以bit为单位(既可以有多个consumers对不同的partition进行consume,也可以有不同的consumers对同一个partition进行consume,因为offset是由consumer控制的)。
参考:
http://www.aboutyun.com/thread-18894-1-1.html
http://www.aboutyun.com/thread-14732-1-1.html
kafka术语的更多相关文章
- 顶级Apache Kafka术语和概念
1.卡夫卡术语 基本上,Kafka架构 包含很少的关键术语,如主题,制作人,消费者, 经纪人等等.要详细了解Apache Kafka,我们必须首先理解这些关键术语.因此,在本文“Kafka术语”中, ...
- Kafka 术语
什么是Kafka? Apache Kafka是一个分布式流媒体平台,允许你发布和订阅记录流,允许你以容错方式存储记录流,允许你处理数据流.或是说Kafka是一个分布式.支持分区.多副本的,基于zook ...
- Kafka术语解释
前一篇文章介绍了如何使用kafka收发消息,但是对于kafka的核心概念并没有详细介绍,这里将会对包括kafka基本架构以及消费者.生产者API涉及的术语进行说明.了解这些术语有助于更深入理解kafk ...
- 使用Kafka的一些简单介绍: 1集群 2原理 3 术语
目录 第一节 Kafka 集群 Kafka 集群搭建 Kafka 集群快速搭建 第二节 集群管理工具 集群管理工具 集群 Issues 第三节 使用命令操纵集群 第四节 Kafka 术语说明 第五节 ...
- Apache Kafka(一)- Kakfa 简介与术语
Apache Kafka 1. Kafka简介.优势.以及使用场景 Kafka的优势: 开源 分布式,弹性架构,fault tolerant 水平扩展: 可以扩展到100个brokers 可以扩展到每 ...
- Kafka简介
Kafka简介 转载请注明出处:http://www.cnblogs.com/BYRans/ Apache Kafka发源于LinkedIn,于2011年成为Apache的孵化项目,随后于2012年成 ...
- 发布-订阅消息系统Kafka简介
转载请注明出处:http://www.cnblogs.com/BYRans/ Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写.Kafka是一种高吞吐量的分布式 ...
- 了解Kafka
Kafka简介 Kafka是一种分布式的,基于发布/订阅的消息系统.主要设计目标如下: 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间复杂度的访问性能 高吞吐率. ...
- 整合Kafka到Spark Streaming——代码示例和挑战
作者Michael G. Noll是瑞士的一位工程师和研究员,效力于Verisign,是Verisign实验室的大规模数据分析基础设施(基础Hadoop)的技术主管.本文,Michael详细的演示了如 ...
随机推荐
- JZOJ 5777. 【NOIP2008模拟】小x玩游戏
5777. [NOIP2008模拟]小x玩游戏 (File IO): input:game.in output:game.out Time Limits: 1000 ms Memory Limits ...
- hibernate的get() load() 和find()区别
如果找不到符合条件的纪录,get()方法将返回null.如果找不到符合条件的纪录,find()方法将返回null.如果找不到符合 条件的纪录,load()将会报出ObjectNotFoundEccep ...
- 学习python第二天 流程判断
while循环age_of_Jim = 56 count = 0 #开始计数while True: #循环代码 if count ==3:#如果次数=3 break#退出 guess_age = in ...
- POJ:2185-Milking Grid(KMP找矩阵循环节)
Milking Grid Time Limit: 3000MS Memory Limit: 65536K Description Every morning when they are milked, ...
- Eclipse主题更换方法
1.打开Eclipse的Help->Eclipse Marketplace 2.在Find里搜索Eclipse Color Theme,点击Install按钮 3.打开Window->Pr ...
- cf984c Finite or not?
一个十进制分数 \(p/q\) 在 \(b\) 进制下是有限小数的充要条件是 \(q\) 的所有质因子都是 \(b\) 的质因子. First, if \(p\) and \(q\) are not ...
- Android EditText禁止换行键(回车键enter)
在EditText所在的xml文件中,设置android:singleLine="true", 则可以禁止掉虚拟键盘: maxlength为该EditText的最大输入长度: &l ...
- SpringBoot中Async异步方法和定时任务介绍
1.功能说明 Spring提供了Async注解来实现方法的异步调用. 即当调用Async标识的方法时,调用线程不会等待被调用方法执行完成即返回继续执行以下操作,而被调用的方法则会启动一个独立线程来执行 ...
- Leetcode 529.扫雷游戏
扫雷游戏 让我们一起来玩扫雷游戏! 给定一个代表游戏板的二维字符矩阵. 'M' 代表一个未挖出的地雷,'E' 代表一个未挖出的空方块,'B' 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖 ...
- Unity3D - 设计模式 - 工厂模式
工厂模式:以食物生产为例 1. 一个生产食物的工厂(此项 需要建立两个类:食物基类<Food>,工厂类<Factory>) 2. 可以生产不同的食物(此项 建立食物的具体子类, ...