JUC线程池深入刨析
JDK默认提供了四种线程池:SingleThreadExecutor、FiexdThreadPool、CachedThreadPool、ScheduledThreadPoolExecutor。
本文会先从前三个线程池的使用开始讲解,然后过度到线程池参数、拒绝策略等方面进行全面讲解,最后自己根据参数构造一个
线程池。
SingleThreadExecutor
public static void singleThreadExecutorTest() {
ExecutorService executorService = Executors.newSingleThreadExecutor();
executorService.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
executorService.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
Thread.sleep(4);
} catch (InterruptedException e) {
e.printStackTrace();
}
executorService.shutdown();
}
该代码是使用Exectors工具类创建的一个大小为1的线程池,并且创建三个任务提交到该线程执行,每个任务执行需要一秒。因此从运行结果中我们可以很清楚的看到三个任务一次只能执行一个线程。
FiexdThreadPool
public static void fixedThreadPoolTest() {
ExecutorService service = Executors.newFixedThreadPool(2);
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
service.shutdown();
}
该代码是使用Exectors工具类创建的一个大小为2的线程池,并且创建三个任务提交到该线程执行,每个任务执行需要一秒。从结果可以看到第一秒两个线程一起执行了,第二秒第三个线程才执行。
CachedThreadPool
public static void cachedThreadPoolTest() {
ExecutorService service = Executors.newCachedThreadPool();
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
service.execute(()->{
System.out.println(Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
try {
Thread.sleep(4000);
} catch (InterruptedException e) {
e.printStackTrace();
}
service.shutdown();
}
该代码是使用Exectors工具类创建的一个大小为Integer.MAX_VALUE的线程池,并且创建三个任务提交到该线程执行,每个任务执行需要一秒。从结果可以看到三个线程一起执行了。
原理分析
构造SingThreadExecutor需要的参数
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
构造FiexdThreadPool需要的参数
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
构造CachedThreadPool需要的参数
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
通过上面三个线程池构造的源码我们可以看到,创建线程池的时候都是通过创建ThreadPoolExecutor对象,创建ThreadPoolExecutor需要5个参数,那么这5个参数是什么呢,我们继续跟踪源码
构造ThreadPoolExecutor对象需要的参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue) {
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
}
这里可以看到生成ThreadPoolExecutor对象需要为其构造参数传递5个参数,但是下面的this里却是7个参数。原来有两个参数是已经固定好的。我们跟踪进去看看这七个参数
ThreadPoolExecutor构造器源码
到这里重头戏来了,下面这个代码才是真真正在创建ThreadPoolExecutor对象的构造器源码。我们可以看到一共有7个参数,我们来谈谈这七个参数
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
创建线程池需要的七个参数
int corePoolSize : 常驻核心线程数
int maximumPoolSize:最大线程数
long keepAliveTime:除了常驻线程的额外线程的存活时间
TimeUnit unit:存活时间的单位
BlockingQueue<Runnable> workQueue:任务队列
ThreadFactory threadFactory:创建线程的工厂
RejectedExecutionHandler handler:拒绝策略
我们先眼熟一下这七个参数,接下来我们从线程池的工作流程来讲解这七个参数
线程池工作流程
线程池刚创建的时候里面是空的,这时候还没有线程。当main线程往线程池里面加任务的时候才会开始创线程
1 主线程往线程池里添加任务,发现核心线程为空,创建核心线程执行任务
2 随着主线程往线程池里加任务,核心线程都被占用了,这时任务会被放入任务队列
3 随着主线程继续往线程池里加任务,任务队列也满了,线程池会创建额外线程执行任务。
4 主线程继续添加任务,任务队列满了,核心线程满了。额外线程+核心线程=总线程数,即额外线程也满了,这时候就会执行拒绝策略。
5 如果没有到4那么极端,随着任务的执行,任务队列越来越少,直至没有,那么额外线程在等待keepaliveTime时间后被销毁,线程池里只剩下核心线程存在。
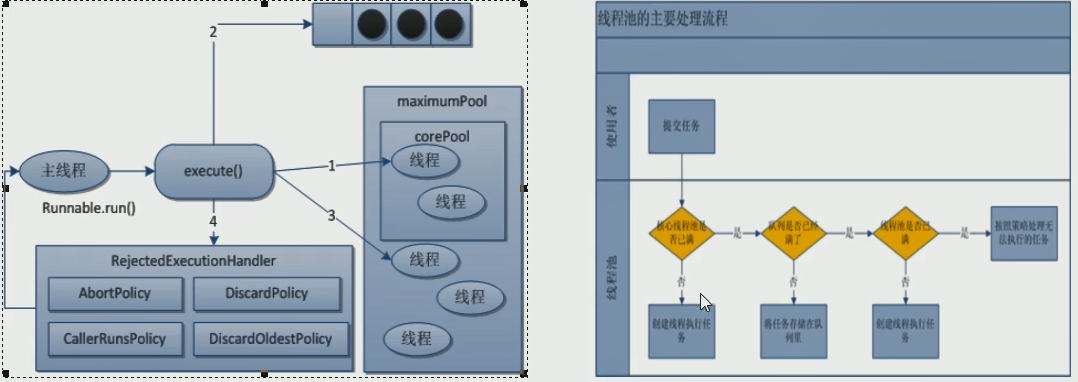
相信知道了流程以后,上面的7个参数我们也就知道都是什么了,这里需要注意的一点是核心线程数是包含在总线程数里面。
谈谈JDK自带的线程池弊端
从上面我们可以看到,JDK自带的SingleThreadExecutor、FixedThreadPool都是采用LinkedBlockingQueue阻塞队列作为任务队列,由于LinkedBlockingQueue是一个
大小为Integer.MAX_VALUE的阻塞队列,因此main线程在添加任务的时候阻塞队列不会满,也就是不会触发拒绝策略,可能会导致任务持续添加引发OOM。而CachedThreadPool
的最大线程数为Integer.MAX_VALUE,会无线创建线程,来一个任务创一个线程,可能会导致线程创太多导致OOM所有我们一般都是自己构造参数创线程池。
四大拒绝策略
AbortPolicy:当任务队列和线程达到最大线程数后还添加任务的话会直接抛异常,阻止程序运行
CallerRunsPolicy:当任务队列和线程达到最大线程数后还添加任务不会抛异常和抛弃任务,而是会将任务回退给调用者。
DiscardOldestPolicy:当任务队列和线程达到最大线程数后还添加任务的话会将任务队列中等待最久的一个任务抛弃掉然后添加新任务
DiscardPolicy:直接抛弃任务。不做任何处理也不抛异常
自己构造线程池
该线程池核心线程数为2,最大线程数为5,额外线程存活时间为60秒,阻塞队列大小为3,采用默认的线程工厂,采用默认的拒绝策略,即抛异常
因此该线程池最多可以连续提供8个任务,超过8个很可能促发拒绝策略,抛异常
public static void myThreadPool() {
ExecutorService threadPool = new ThreadPoolExecutor(2,
5,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy());
for(int i=0;i<8;i++) {
threadPool.execute(()->{
System.out.println(Thread.currentThread().getName());
});
}
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
threadPool.shutdown();
}
线程池参数如何选择
CPU密集型:CPU密集型CPU使用率高,一直在工作,空闲时间少,因此最大线程数最好设为CPU核数+1
IO密集型:IO密集型大部分时间都在做IO操作,CPU空闲时间多,因此最大线程数最好设为CPU核数*2.
JUC线程池深入刨析的更多相关文章
- 死磕 java线程系列之线程池深入解析——普通任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 前面我们一起学习了Java中 ...
- Java并发编程与技术内幕:线程池深入理解
摘要: 本文主要讲了Java当中的线程池的使用方法.注意事项及其实现源码实现原理,并辅以实例加以说明,对加深Java线程池的理解有很大的帮助. 首先,讲讲什么是线程池?照笔者的简单理解,其实就是一组线 ...
- Java线程池深入理解
之前面试baba系时遇到一个相对简单的多线程编程题,即"3个线程循环输出ADC",自己答的并不是很好,深感内疚,决定更加仔细的学习<并发编程的艺术>一书,到达掌握的强度 ...
- 转:Java并发编程与技术内幕:线程池深入理解
版权声明:本文为博主林炳文Evankaka原创文章,转载请注明出处http://blog.csdn.net/evankaka 目录(?)[+] ); } catch (InterruptedExcep ...
- 原创:ThreadPoolExecutor线程池深入解读(一)----原理+应用
本文档,适合于对多线程有一定基础的开发人员.对多线程的一些基础性的解读,请参考<java并发编程>的前5章. 对于源代码的解读,本人认为可读可不读.如果你想成为一位顶级的程序员,那就培养自 ...
- 死磕 java线程系列之线程池深入解析——体系结构
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 简介 Java的线程池是块硬骨头,对线程池的源码做深入研究不仅能提高对Java整个并发编程的理解,也能提高自己 ...
- 死磕 java线程系列之线程池深入解析——生命周期
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 上一章我们一起重温了下线程的 ...
- 死磕 java线程系列之线程池深入解析——未来任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:线程池源码部分如无特殊说明均指ThreadPoolExecutor类. 简介 前面我们一起学习了线程池中普 ...
- 死磕 java线程系列之线程池深入解析——定时任务执行流程
(手机横屏看源码更方便) 注:java源码分析部分如无特殊说明均基于 java8 版本. 注:本文基于ScheduledThreadPoolExecutor定时线程池类. 简介 前面我们一起学习了普通 ...
随机推荐
- 「微信小程序免费辅导教程」25,基本内容组件text的使用及个人帐号允许的服务类目
- easyui-numberbox限定仅输入数字
许多必填项都涉及到数字,比如电话号码,身份证号这些要求用户在输入时只能输入数字.Easyui提供了数字框控件,允许用户只输入数字, <td> <input id="ssd& ...
- R语言中文社区历史文章整理(类型篇)
R语言中文社区历史文章整理(类型篇) R包: R语言交互式绘制杭州市地图:leafletCN包简介 clickpaste包介绍 igraph包快速上手 jiebaR,从入门到喜欢 Catterpl ...
- Oracle 学习笔记(十)
合并查询 在实际项目开发中经常遇到要合并结果集的情况,可以使用集合操作符:union,union all,intersect,minus.这次笔记学习这几个操作符. [union] 该操作符用于取得两 ...
- ADO之密码验证--3次错误就锁定
这个程序是那vs2010下写的,C#语言.数据库是sql server 2008 首先在数据库中新建一个数据库Test1,在数据库中新建一个表用来保存用户名和密码USERINFO, CREATE TA ...
- 5个最佳的Android测试框架(带示例)
谷歌的Android生态系统正在不断地迅速扩张.有证据表明,新的移动OEM正在攻陷世界的每一个角落,不同的屏幕尺寸.ROM /固件.芯片组以及等等等等,层出不穷.于是乎,对于Android开发人员而言 ...
- c4d 帮助 prime r16 usage
c4d 帮助 prime cinema 4d prime c4d 基础 前言 usage 开始 双击程序图标 双击一个场景文件 用开始菜单 windows 二选一 从 ...
- [oldboy-django][2深入django]班级管理(Form)--添加
1.需求: 添加班级,当有某个输入框数据格式不对时,会保留所有输入框的上次输入数据, 同时给出错误信息 2.视图 def add_class(request): # 提交数据都要用form来实现,因为 ...
- PHP共享内存的应用shmop系列
简单的说明 可能很少情况会使用PHP来操控共享内存,一方面在内存的控制上,MC已经提供了一套很好的方式,另一方面,自己来操控内存的难度较大,内存的读写与转存,包括后面可能会用到的存储策略,要是没有一定 ...
- Linux 程序编译过程的来龙去脉
大家肯定都知道计算机程序设计语言通常分为机器语言.汇编语言和高级语言三类.高级语言需要通过翻译成机器语言才能执行,而翻译的方式分为两种,一种是编译型,另一种是解释型,因此我们基本上将高级语言分为两大类 ...