Paris Traceroute
Paris Traceroute is a new version of the well-known network diagnosis and measurement tool.
Why should you use Paris traceroute?
Because traceroute fails in the presence of routers that employ
load balancing on packet header fields. The failures lead to the
discovery of inaccurate and incomplete paths, that may mislead operators during problem diagnosis and result in erroneous internet maps.
Paris traceroute, by controling packet header contents, obtains
a more precise picture of the actual routes that packets follow.
For a quick demonstration, look at the figure on the right. Suppose you are trying to measure the route between Src and Dst.
The true router topology is shown on the left. L is a
router that balances load across two paths, via routers A
or C. The middle of the figure shows what you might see
with classic traceroute. On the right is what you would get with Paris
traceroute...
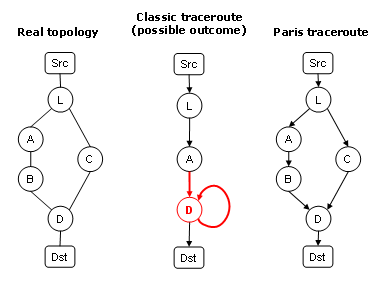
A brief demonstration of Paris traceroute's skills
Paris traceroute is a new version of the well-known network diagnosis and measurement tool. It addresses problems caused by load balancers with the initial implementation of traceroute.
Traceroute's deficiencies
Routers can spread their traffic across multiple paths using a per-packet, per-flow, or per-destination policy. In per-flow load balancing, packet header information ascribes each packet to a flow, and the router forwards all packets belonging to a same flow to the same interface. A natural flow identifier is the classic five-tuple of fields from the IP header and either the TCP or UDP headers: Source IP address, Destination IP address, Protocol, Source port, and Destination port. We found through our experiments that load balancers actually use combinations of these fields, as well as three other fields: the IP Type of Service (or TOS), and the ICMP Code and ICMP header checksum fields.
Per-flow load balancing ensures that packets from the same flow are delivered in order. Per-packet load balancing
makes no attempt to keep packets from the same flow together,
and focuses purely on maintaining an even load. Per-destination load balancing
could be seen as a coarse form of per-flow load balancing, as
it directs packets based upon the destination IP address. But,
as it disregards source information, there is no notion of a
flow per se. As seen from the measurement point of view,
per-destination load balancing is equivalent to classic routing which
is also per destination, and so we will not explore it here.
Whether a router balances load per-flow or per-packet depends
on the router manufacturer, the OS version, and how the network
operator configures it.
Where there is load balancing, there is no longer a single
route from a source to a destination. In the case of per-packet
load balancing, a given packet might take any one of a number
of possible routes. With per-flow load balancing, the notion of
a single route persists for packets belonging to a given flow,
but different flows for the same source-destination pair can
follow different routes. In this regard, designing a new traceroute
able to uncover all routes from a source to a given destination
would be a significant improvement.
Indeed, the current
traceroute is not adequate to that task, as it cannot
definitively identify one single route from among many. It suffers from
two systematic problems: it fails to discover true nodes and
links, and it may report false links. These problems are due to
the random manner in which its probe packets are directed by a
load-balancing router, or load balancer. Our
explanation of these two problems draws on the example in
Figure 1. In this example, L is a load balancer at hop 1 from
the traceroute source. The true router topology from hops 1 through 4
is shown on the left. Routers are represented as circles and each
of their interfaces is numbered. We also show the probe
packets sent with TTL 1 to 4. The packets are depicted as
yellow arrows, either above the topology, if L directs them to
A, or below, if L directs them to B. At the right side, we
present the topology that would be inferred given these probe
packets.
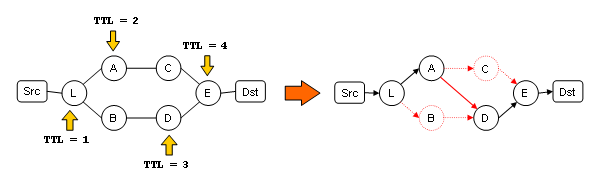
Figure 1 Traceroute's deficiencies under load balancing
Missing nodes and links
By default, traceroute sends three probes per hop. We can imagine a
scenario where all three probes to distance 2 are directed to
A. Device B is not discovered, and the links (L,B) and (B,D)
can thus not be inferred. With purely random load balancing,
there is a significant probability, of 0.53 x 2 = 0.25, that
one of the two devices, A or B, would be left undiscovered by a
traceroute through this topology. In the general case, there may
be more than two next-hop interfaces following a load balancer. For
instance, the newer Juniper routers permit up to sixteen
equal-cost paths. It is certain that classic traceroute misses
many nodes, and the possibility to infer many links.
False links
In our example, L directs the probe dedicated to hop 2 to A and the one
to hop 3 to B, which leads to the mistaken inference of a link
between A and D. Many topology inference tools send one probe
packet per hop to reduce the probing overhead. Consequently,
these tools cannot easily detect that a single hop responds
with multiple interfaces. In the default usage of traceroute
(i.e., three probes per hop), it is easier to identify instances
of hops that respond with multiple interfaces. In our example, let us
assume that by sending three probes we find both A and B at hop
2, and C and D at hop 3. A liberal approach may infer the
existence of links (A,C), (A,D), (B,C), and (B,D), which would
lead to two false links. On the other hand, a more conservative
approach would require ignoring much data, which would lead to
more missing nodes and links. There is no satisfactory
solution with the existing traceroute.
False links may be caused by
either per-packet or per-flow load balancing. In the latter
case, false links arise because traceroute relies upon the ICMP
replies to its probe packets in order to identify devices along a
route. A router that sends a Time Exceeded message encapsulates the
IP header of the packet that it discarded, plus the first 8
octets of data which, in the case of UDP, TCP, or ICMP probes,
means the first 8 octets of the relevant transport-layer
header.
Traceroute considers these 28 octets in order to match
replies to probes. In the UDP probes that it sends out,
traceroute sets a high destination port number, and systematically
varies this number with each probe so that there will be a
unique identifier in the returning ICMP packet. For ICMP
probes, traceroute uses the sequence number field as the probe
identifier, which in turn impacts the checksum of the ICMP header.
Unfortunately, as we have found, varying any field in the first
four octets of the transport-layer header amounts to
systematically varying the flow identifier with each probe.
How we correct it
We
introduce Paris traceroute, a new traceroute to respond to
load balancing routers. Its key innovation is to control the
probe packet header fields in a manner that allows all probes
towards a destination to follow the same path in the presence
of per-flow load balancing. It also allows a user to distinguish
between the presence of per-flow load balancing and per-packet load
balancing. Unfortunately, due to the random nature of
per-packet load balancing, Paris traceroute cannot perfectly
enumerate all paths in all situations. But it can do
considerably better than the classic traceroute, and it can
flag those instances where there are doubts. The problem, if one wishes
to maintain certain header fields constant, is that traceroute
still needs to be able to match response packets to their
corresponding probe packets.
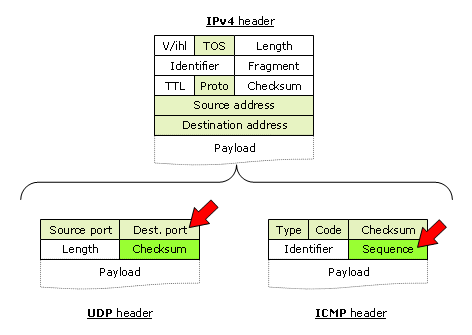
Figure 2 The IP, UDP and ICMP headers. Per-flow load balancers
use the grey fields to identify a flow. Red arrows
show the fields incremented by classic traceroute.
Paris traceroute uses the green fields to identify probes
Paris traceroute does this by varying header fields that are
within the first 28 octets, but are not used for load
balancing. In the case of TCP probes, Paris traceroute varies
the sequence number. In UDP probes, it is the checksum field.
This requires manipulating the payload to yield the desired checksum,
as packets with an incorrect checksum are liable to be discarded.
In ICMP probes, it is a combination of the ICMP identifier and
the sequence number. We carefully set the value of the ICMP
identifier and sequence number to keep constant the header
checksum of all probes to a destination. Figure 2 summarizes
the IP, UDP, and ICMP header fields that are used by load
balancers, classic traceroute, and Paris traceroute. We include the ICMP
type field as used for load balancing, even if we cannot
verify it experimentally (routers only repond to one type of
probes, which is the ICMP echo request). Our experiments with
UDP, TCP, and IPSec probes do give strong evidence that routers
blindly use the first four octets after the IP header combined
with the IP fields to do load balancing.
Paris Traceroute的更多相关文章
- [转]Traceroute网络排障实用指南(2)
五.优先级与限速 5.1 Traceroute延时判断影响因素 Traceroute延时包括三点: 探测包到达一个特定路由器的时间 路由器生成IPMI TTL Exceed的时间 ICMP TTL E ...
- 常用网络工具 ipconfig arp traceroute
如今的计算机是离不开网络的计算机了,因而我们对网络要有一基础的认识.连不上网,程序运行不正常之类的,多少都与网络有关.本文将介绍常用的工具. 网络出问题 ipconfig ping 网络连不上,首先要 ...
- ICMP的应用--Traceroute
Traceroute是用来侦测主机到目的主机之间所经路由情况的重要工具,也是最便利的工具.前面说到,尽管ping工具也可以进行侦测,但是,因为ip头的限制,ping不能完全的记录下所经过的路由器.所以 ...
- 查看外网出口IP && Traceroute
一.CentOS 查看外网出口IP 1---------------- # curl ifconfig.me 2----------------# curl icanhazip.com 二.Trace ...
- Traceroute命令原理(转)
Traceroute命令基本功能 该命令用于测试两个TCP/IP系统之间的网络层连通性和显示传输路径中每一跳地址,又称为路径跟踪,如果Traceroute命令测试成功,我们能够观察到从源主机到目的主机 ...
- 每天一个linux命令(55):traceroute命令
通过traceroute我们可以知道信息从你的计算机到互联网另一端的主机是走的什么路径.当然每次数据包由某一同样的出发点(source)到达某一同样的目的地(destination)走的路径可能会不 ...
- traceroute
把跳数设置为10次: ]# traceroute -m www.baidu.com traceroute to www.baidu.com ( hops max, byte packets 10.10 ...
- aix DNS 配置以及网络命令traceroute和nslookup 和 dig 命令
DNS 域名系统 (DNS) 服务器将 IP 地址解释为其他计算机或网站的域名和地址.如果没有 DNS,您需要在 Web 浏览器中输入 IP 地址.例如,如果您未访问 DNS 并希望查看 IBM 的网 ...
- icmp,tcp,traceroute,ping,iptables
有东莞的监控主机到北京BGP出问题了: 报警短信疯狂发送: 找东莞IDC和北京BGP服务商协查: 有个奇怪的问题:北京到东莞trcaceroute都有路由信息 东莞143段到北京全无路由信息:但,东莞 ...
随机推荐
- 关于CocoaPods update/CocoaPods install 慢、没反应、卡住的解决方案(Pods升级步骤)
pod管理第三方库带来的便利大家有目共睹,但是--,估计有很多人会遇到这样一种尴尬情况: Pod install 或 Pod update 执行之后,就不动了,一直一个界面简直要崩溃... 网上有很 ...
- VS2010最常用快捷键
1.选择类 F8 当前位置变成选定区域的头/尾(再移动光标或者点鼠标就会选定) Ctrl + F8 当前行变成选定区域的头/尾(再移动上下光标或者点鼠标就会选定多行) CTRL + W 选择当前单词 ...
- Effective Java 读书笔记
创建和销毁对象 >考虑用静态工厂方法替代构造器. 优点: ●优势在于有名称. ●不必再每次调用他们的时候都创建一个新的对象. ●可以返回原返回类型的任何子类型的对象. ●在创建参数化类型实例的时 ...
- Jquery:小知识;
Jquery:小知识: jQuery学习笔记(二):this相关问题及选择器 上一节的遗留问题,关于this的相关问题,先来解决一下. this的相关问题 this指代的是什么 这个应该是比较好理 ...
- Netty系列之Netty 服务端创建
1. 背景 1.1. 原生NIO类库的复杂性 在开始本文之前,我先讲一件自己亲身经历的事:大约在2011年的时候,周边的两个业务团队同时进行新版本开发,他们都需要基于NIO非阻塞特性构建高性能.异步和 ...
- u3d_Shader_effects笔记3 half diffuse 和 ramp texture
1.前面的心情 每次写博客,先写心情也好,就当是小日记了吧.现在已经懒到不想动笔和纸来写日记了.近两天公司的活较少,晚上直接回来了,没有留公司.在公司看代码,不做工,就困... 哎,小辉哥家的老房子后 ...
- 在Ubuntu14.04下安装vsftp服务器
猜想在Ubuntu下搭建ftp服务器来实现windows和ubuntu下文件互传是一件很简单的事儿,但是在网上找了好几篇文章都不行,故自己在这里总结一下方法. 首先安装vsftp服务器 sudo ap ...
- Visual Studio各版本工程文件之间的转换
转载于:http://www.cnblogs.com/jmliao/p/5594179.html 由于VS版本比较多,低版本无法直接打开高版本的工程文件,通过对工程文件进行一些修改可以解决这些问题. ...
- Oracle取TOP N条记录(转载)
在SQL Server里面有top关键字可以很方便的取出前N条记录,但是Oracle里面却没有top的使用,类似实现取出前N条记录的简单方法如下: 方法1:利用ROW_NUMBER函数 取出前5条记录 ...
- JavaScript Number 对象
JavaScript Number 对象 Number 对象 Number 对象是原始数值的包装对象. Number 创建方式 new Number(). 语法 var num = new Numbe ...