Azkaban 使用问题及解决(一)
什么是Azkaban
Azkaban是一款基于Java编写的任务调度系统
任务调度:有四个任务脚A、B、C、D,其中任务A与任务B可以并行运行,然后任务C依赖任务A和任务B的运行结果,任务D依赖任务C的运行结果,此时整个过程可以等效为一个有向无环图,而给所有的任务运行定一个运行规则就可以理解为任务调度。
在任务简单时可以人为控制,但是当任务非常多,依赖复杂时,如果没有清晰的任务规划图,很容易在任务之间形成闭环从而出错,或者多个可并行的任务没有并行执行而浪费资源,这种时候就需要一个工作流调度器,Azkaban就是完成这种任务的。
Azkaban分为三个部分:
- mysql服务器:用于存储项目、日志或者执行计划之类的信息
- web服务器:使用Jetty对外提供web服务,使用户可以通过web页面方便管理
- executor服务器:负责具体的工作流的提交、执行
{kind=link}
基础搭建
首先可从Azkaban官网上下载azkaban,初学时可以只下载
azkaban-web-server-2.5.0.tar.gz,azkaban-executor-server-2.5.0.tar.gz和azkaban-sql-script-2.5.0.tar.gz
三个组件压缩包即可,下载后进行解压
azkaban-sql-script-2.5.0.tar.gz包中包含的都是Azkaban所需用到的所有数据库表的创建语句,在Azkaban 2.5.0版本的这个包中会有一个create-all.sql文件,可以一次性创建好所有的数据库表。
azkaban-web-server-2.5.0.tar.gz解压后在其conf/azkaban.properties文件中可以进行web服务器数据库连接,web访问方式与端口,web访问账号密码,邮件等设置,各位根据自己的实际情况进行配置。
azkaban-executor-server-2.5.0.tar.gz解压后在其conf/azkaban.properties文件中可以进行执行服务器数据库连接,执行服务器线程数等设置。
在这些都设置好以后,浏览器访问对应IP与端口,即可进入Azkaban的web界面了。此时Azkaban的基础搭建基本完成。
了解各个元素及其关系
Azkaban界面中的主要元素有三个,分别是project、job与flow
project可以理解为某个项目,其项目中包含了许多需要执行的任务,即为job,各个job之间形成依赖关系,便组成了工作流flow
创建工作 job 与创建工作流 flow
在Azkaban系统的web界面中有创建project的交互,可以通过界面创建一个project,但是Azkaban没有创建job与flow的界面,这一点很讨厌。于是需要编写以.job为扩展名的文件然后上传,才能在系统中形成job任务。
创建job
首先,需要创建以.job为扩展名的文件,一个文件即代表一个任务。
所有的job都需要一个知道他们如何去执行的type。一般的,有这样四种job类型:Java、command、javaprocess和pig。
本文以type=command为例
其次在这个文件中添加这个任务所需的参数与参数值,
必须的参数有type与command
例如
type=command
command=echo 'jobs start'
retries --> 任务失败时自动重启的次数retry.backoff --> 每一次任务尝试重启时之间等待的毫秒数working.dir --> 可以重新指定任务执行的工作目录,默认为目前正在运行的任务的工作目录failure.emails --> 任务失败时的邮件提醒设置,以逗号分隔多个邮箱success.emails --> 任务成功时的邮件提醒设置,以逗号分隔多个邮箱notify.emails --> 任务无论失败还是成功都邮件提醒设置,以逗号分隔多个邮箱dependencies--> 定义该文件依赖的文件,值为被依赖文件的文件名,多个目标以逗号分隔,不加扩展名保存为
start.job文件即创建好了一个jobAzkaban每个project中只能上传一个.zip文件
创建工作流flow
定义好所有的参数后即为定义好了一个job,如果添加了dependencies参数即形成了工作流flow
以开头的任务流为例:
#start.job
type=command
command=echo "jobs start"
#A.job
type=command
command=echo "This A job"
dependencies=start
#B.job
type=command
command=echo "This B job"
dependencies=start
#C.job
type=command
command=echo "This C job"
dependencies=A,B
#D.job
type=command
command=echo "This D job"
dependencies=C
保存好5个文件后,将5文件打包成zip,然后在界面中进行上传,就会将这几个job上传到了系统中,最终呈现
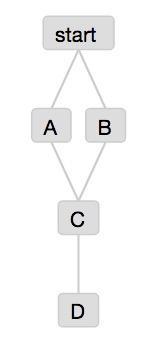
从而一个工作流flow建好。
注意,想多个工作流flow并到一张图中,必须多个工作流flow有一个公共的结束job文件
创建子工作流subflow及其作用
Azkaban可以给每一个flow设定定时调度,这样就可以等到特定时间运行,然而,这样依旧不能满足一些需求
例如:
一个整个平台的任务调度中,大部分的job任务是根据依赖依次进行,但是有某些个job则依然需要自己的运行设定时间,即上一个job完成后需要等待,不能立即执行下一个job,但是Azkaban给job任务单独设定时后,会覆盖整个任务流flow的设置,所以此时需要引进子任务流subflow
子任务流的创建需要一个job文件,其参数形式为
type= xxx
flow.name= xxx
dependencies= xxx
注意
子流文件的参数设置需要遵循:
- flow.name为设定的子流subflow的结束job文件的文件名
- 子流内部的起始文件不存在依赖 ,其依赖关系在type=flow这个文件中设定
- 子流后面的文件的依赖则为type=flow这个job文件的文件名
所以上面这个例子中
添加一个文件:
#subflow.job
type=flow
flow.name=C
dependencies=start
相应修改文件:
#A.job
type=command
command=echo "This A job"
#B.job
type=command
command=echo "This B job"
#D.job
type=command
command=echo "This D job"
dependencies=subflow
此时工作流会变为
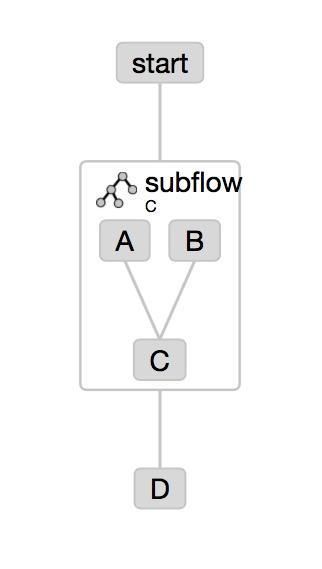
这样在这个project中,就可以分别对两个流进行调度的设定,并且主流中的依赖会等待子流的运行,总体任务调度图也会非常的清晰
邮件提醒设置
Azkaban自带有邮件提醒功能,在web服务器的conf/azkaban.properties文件中,有以下字段
# mail settings
mail.host=
mail.sender=
mail.user=
mail.password=
job.failure.email=
job.success.email=
job.notify.email=
failure.emails,success.emails ,notify.emails三个参数,但是这三个属性不是直接加在.job文件中,而是需要在所有.job文件的根目录下创建一个以.properties为扩展名的文件例如:
# system.properties
success.emails=xxx@xx.com
failure.emails=xxx@xx.com
一些其他需要全局作用的参数也可以添加在这个文件中,此属性文件会作用于全局job文件,一起打包上传即可。这样就可以实现任务成功或失败时的邮件提醒。
最后
Azkaban还可以自行开发插件,不过这个系统依然有一些bug,如果后续有需求则需要慢慢修补了。
Azkaban 使用问题及解决(一)的更多相关文章
- Azkaban 使用问题及解决
什么是Azkaban Azkaban是一款基于Java编写的任务调度系统 任务调度:有四个任务脚A.B.C.D,其中任务A与任务B可以并行运行,然后任务C依赖任务A和任务B的运行结果,任务D依赖任务C ...
- 大数据入门第十二天——azkaban入门
一.概述 1.azkaban是什么 通过官方文档:https://azkaban.github.io/ Azkaban is a batch workflow job scheduler create ...
- 初识Azkaban
先说下hadoop 内置工作流的不足 (1)支持job单一 (2)硬编码 (3)无可视化 (4)无调度机制 (5)无容错机制 在这种情况下Azkaban就出现了 1)Azkaban是什么 Azkaba ...
- Hadoop - Azkaban 作业调度
1.概述 在调度 Hadoop 的相关作业时,有以下几种方式: 基于 Linux 系统级别的 Crontab. Java 应用级别的 Quartz. 第三方的调度系统. 自行开发 Hadoop 应用调 ...
- hadoop工作流引擎之azkaban [转]
介绍 Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个 ...
- Oozie和Azkaban的技术选型和对比
1 两种调度工具功能对比图 下面的表格对上述2种hadoop工作流调度器的关键特性进行了比较,尽管这些工作流调度器能够解决的需求场景基本一致,但在设计理念,目标用户,应用场景等方面还是存在区别 特性 ...
- hadoop工作流引擎之azkaban
Azkaban是twitter出的一个任务调度系统,操作比Oozie要简单很多而且非常直观,提供的功能比较简单.Azkaban以Flow为执行单元进行定时调度,Flow就是预定义好的由一个或多个可存在 ...
- 工作流调度器azkaban(以及各种工作流调度器比对)
1:工作流调度系统的作用: (1):一个完整的数据分析系统通常都是由大量任务单元组成:比如,shell脚本程序,java程序,mapreduce程序.hive脚本等:(2):各任务单元之间存在时间先后 ...
- azkaban报错记录
问题信息:Failed to build job executor for job o2o_get_file_ftp1Job type 'command ' is unrecognized. Coul ...
随机推荐
- python爬虫,使用urllib2库报错
urllib2发生报错URLError: <urlopen error [Errno 10061]:首先检查网址是否正确其次如果报这种错误,是因为ie里设置了代理,取消即可, 步骤: 打开IE浏 ...
- 小程序之--canvasToTempFilePath
最近做的小程序需要图片上传头像的功能,不对上传的图片做处理肯定出来的效果不好:所以就隐藏了一个canvas对上传的图片进行压缩或者进行大小的编辑: 通过chooseImage方法,可以拿到图片的临时路 ...
- ELK简单安装测试
1 介绍组件 Filebeat是一个日志文件托运工具,在你的服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读). Kafka是一种高吞 ...
- rsa公钥和私钥的生成
在liunx环境中 openssl 然后生成私钥: genrsa -out app_private_key.pem 2048 # 私钥的生成 在利用私钥生成公钥: rsa -in app_privat ...
- apply,call以及bind的区别
每个函数都包含两个非继承而来的方法:apply()和 call(). 这两个方法的用途都是在特定的作用域中调用函数,实际上等于设置函数体内 this 对象的值. 一.apply() apply()方法 ...
- ArcMap图层属性表中添加图片
一看标题是不是有点懵?懵就对了!刚接触到的时候我也有点懵,属性表不是都是文本啊数字啊之类的格式,怎么还可以存图片,下面就带大家来看看吧! 一.关于图层入库问题 图层进入数据库和图层以shp格式存储时, ...
- 锚点的animate使用过程中定位不准确的问题小记
源码: $('html, body, .S').animate({ scrollTop: $('.a1').offset().top - 133}, { duration: 1500, easing: ...
- 关于python的装饰器(初解)
在python中,装饰器(decorator)是一个主要的函数,在工作中,有了装饰器简直如虎添翼,许多公司面试题也会考装饰器,而装饰器的意思又很难让人理解. python中,装饰器是一个帮函数动态增加 ...
- [C]排序并插入
/* 编写程序,在主函数中定义一个有10个元素的整型一维数组,用户输入9个数据,调用函数,对数组元素进行从小到大排序后,在函数中输入一个数,插入到数组中正确的位置,并输出. */ #include&l ...
- Python-100道练习题答案
题目链接:http://www.runoob.com/python/python-100-examples.html #5. # def find_max(): # a=int(input(" ...