Hive中的Order by与关系型数据库中的order by语句的异同点
在Hive中,ORDER BY语句是对查询结果集进行整体的排序,最终将会产生一个reducer进行全局的排序,达到的最终结果是和传统的关系型数据库是一样的。
在数据量非常大的时候,全局排序的单个reducer将会成为性能瓶颈,有可能由于数据量过大而跑不出来结果。
Hive中可以设置hive.mapred.mode为strict严格模式,这时候,Hive要求用户必须对order by语句加上limit 条数限制,防止排序数据集过大导致性能瓶颈。
在这里我不提sort by ,distribute by的用法,下一节好好分析下这几个语句的用法。我主要讲下Hive的order by 与oracle 的order by的不同点。
同样是一个emp雇员表。我希望执行如下查询:
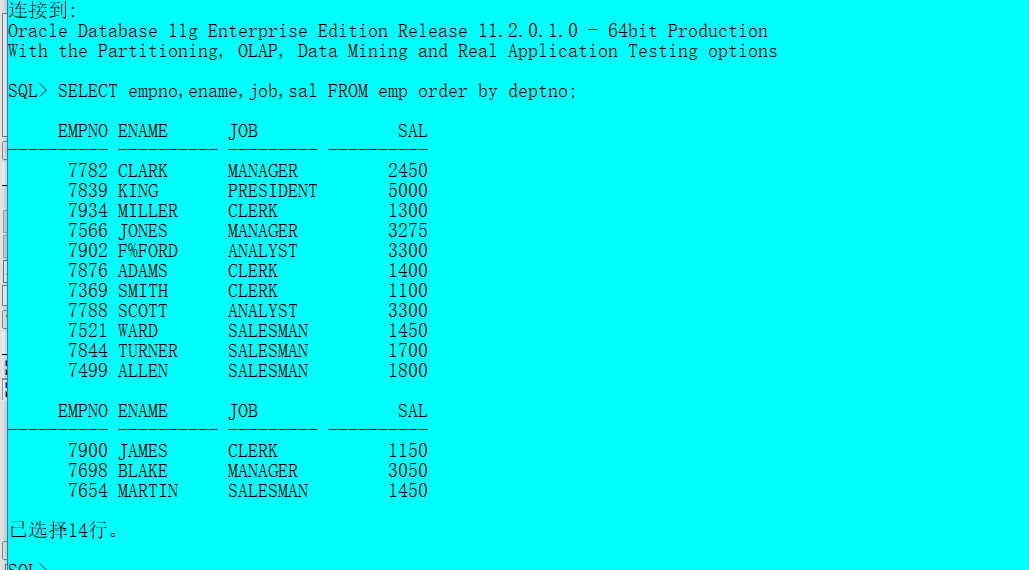
SELECT empno,ename,job,sal FROM emp order by deptno;
这个语句中,order by排序引用的列在不是select查询的列,在大多数的关系型数据库中执行是没有问题的,但是在Hive中执行就会出问题,效果如下:
在Oracle sqlplus中执行效果如下:
在Hive中执行却报错:

在HIVE中,order by语句只能引用select查询的列,这一点我觉得是有待改进的地方。
我在查询列表中加上deptno后,才能正常执行,这一点大家在写Hive SQL的时候需要注意,或许后续版本会对这个bug进行改进,我当前用的是Hive 2.3.3版本。
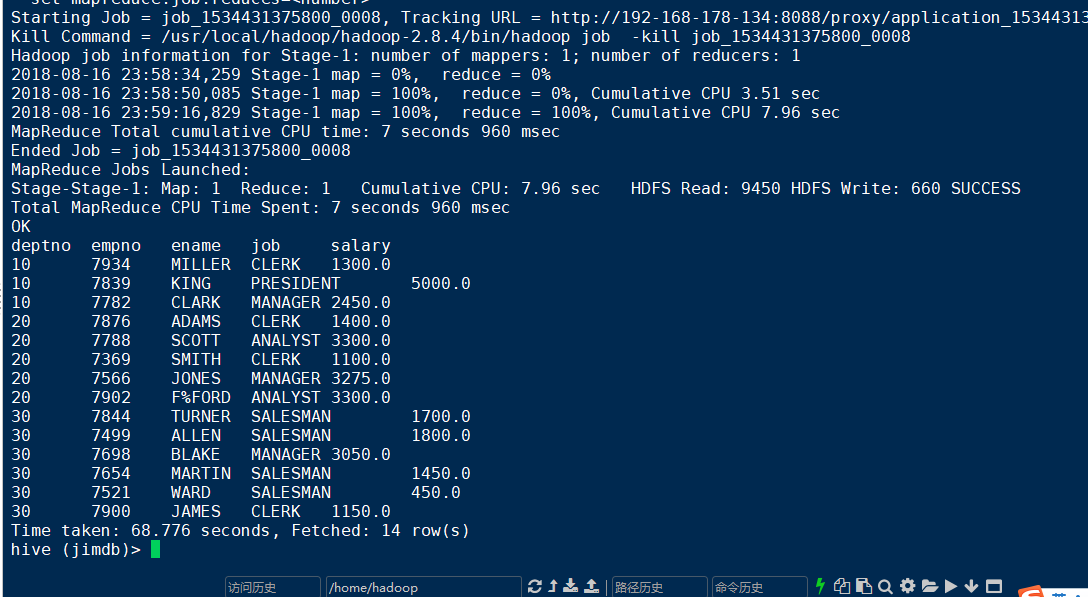
排序列如果来自于select 后的选择列的时候就不会报错,如下:
select deptno,empno,ename,job,salary from emp order by deptno;
Hive中的Order by与关系型数据库中的order by语句的异同点的更多相关文章
- 转: SQL中的where条件,在数据库中提取与应用浅析
SQL中的where条件,在数据库中提取与应用浅析 http://hedengcheng.com/?p=577 1问题描述 一条SQL,在数据库中是如何执行的呢?相信很多人都会对这个问题比较感兴趣.当 ...
- Sqoop(三)将关系型数据库中的数据导入到HDFS(包括hive,hbase中)
一.说明: 将关系型数据库中的数据导入到 HDFS(包括 Hive, HBase) 中,如果导入的是 Hive,那么当 Hive 中没有对应表时,则自动创建. 二.操作 1.创建一张跟mysql中的i ...
- 从集合的无序性看待关系型数据库中的"序"
本文目录:1.集合的特征2.集合的无序性3.表中记录的无序性4.集合的"序"和物理存储顺序之间的关系5.查询结果(虚拟表)的无序性.随机性6.为什么总是强调"无序&quo ...
- 转载-SQL中的where条件,在数据库中提取与应用浅析
1 问题描述 一条SQL,在数据库中是如何执行的呢?相信很多人都会对这个问题比较感兴趣.当然,要完整描述一条SQL在数据库中的生命周期,这是一个非常巨大的问题,涵盖了SQL的词法解析.语 ...
- SQL中的where条件,在数据库中提取与应用浅析
1. 问题描述 一条SQL,在数据库中是如何执行的呢?相信很多人都会对这个问题比较感兴趣.当然,要完整描述一条SQL在数据库中的生命周期,这是一个非常巨大的问题,涵盖了SQL的词法解析.语法解析.权限 ...
- 0320SQL中的where条件,在数据库中提取与应用浅析
转自 何登成的技术博客 追求技术的道路上,10年如一日 首页 关于我 RSS 订阅 © 2012-2017 何登成的技术博客 SQL中的where条件,在数据库中提取与应用浅析 3月 3r ...
- 将 flask 中的 session 存储到 SQLite 数据库中
将 flask 中的 session 存储到 SQLite 数据库中 使用 flask 构建服务器后端时,常需要在浏览器端存储 cookie 用于识别不同用户,根据不同的 cookie 判断出当前请求 ...
- 把Execl表格中的数据获取出来保存到数据库中
比如我们遇到一些需要把execl表格中的数据保存到数据库中,一条一条保存效率底下而且容易出错,数据量少还好,一旦遇到数据量大的时候就会累死个人啊,下面我们就来把execl表格中数据保存到对应的数据库中 ...
- 关系型数据库中主键(primary key)和外键(foreign key)的概念。
刚接触关系型数据库的同学,会听过主键和外键的概念.这是关系型数据库的基本概念,需要清楚理解.今天我就以简洁的语言总结一下这个概念. 主键.一句话概括:一张表中,可以用于唯一标识一条记录的字段组(或者说 ...
随机推荐
- python爬虫实例项目大全
WechatSogou [1]- 微信公众号爬虫.基于搜狗微信搜索的微信公众号爬虫接口,可以扩展成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典. DouBanSpider [2]- ...
- node-RED
node-RED提供了一个基于浏览器的编辑器,可以轻松地使用调色板中的广泛节点将流连接在一起,这些节点可以通过单击部署到其运行时.使用Node-RED,开发人员将输入/输出和处理节点连接起来,创建流程 ...
- day 18 - 2 正则与 re 模块练习
1.爬虫的例子 #爬虫的例子(方法一) import re import urllib,request import urlopen def getPage(url): response = urlo ...
- python知识点
if __name__ == 'main' 一个python的文件有两种使用的方法,第一是直接作为脚本执行,第二是import到其他的python脚本中被调用(模块重用)执行. 因此if __name ...
- 第十二节,OpenCV学习(一)图像的读取、显示、保存
一.读取图像 所谓的图像就是一个数组,对图像的处理就是对数字的处理 import cv2 import numpy as np img = cv2.imread('dog.jpg') print(im ...
- Theano.tensor.round函数学习,同时解决输出Elemwise{xxx,no_inplace}.0的问题
1. 出现Elemwise{xxx,no_inplace}.0 这是因为没有定义theano.function所致,参考下面错误示范: y = np.random.normal(size=(2,2 ...
- Python简单试题
1,相乘次数 题目要求描述: 一个整数每一位上的数字相乘,判断是否为个位数,若是则程序结束 ,不是则继续相乘,要求返回相乘次数. 例:39 > 3*9=27 > 2*7=14 > 1 ...
- YOLO v3
yolo为you only look once. 是一个全卷积神经网络(FCN),它有75层卷积层,包含跳跃式传递和降采样,没有池化层,当stide=2时用做降采样. yolo的输出是一个特征映射(f ...
- Quartz.NET 入门(转)
概述 Quartz.NET是一个开源的作业调度框架,非常适合在平时的工作中,定时轮询数据库同步,定时邮件通知,定时处理数据等. Quartz.NET允许开发人员根据时间间隔(或天)来调度作业.它实现了 ...
- SpringBoot动态配置加载
1.SpringBoot对配置文件集中化进行管理,方便进行管理,也可以使用HttpClient进行对远程的配置文件进行获取. 创建一个类实现EnvironmentPostProcessor 接口,然后 ...