优化算法:AdaGrad | RMSProp | AdaDelta | Adam
0 - 引入
简单的梯度下降等优化算法存在一个问题:目标函数自变量的每一个元素在相同时间步都使用同一个学习率来迭代,如果存在如下图的情况(不同自变量的梯度值有较大差别时候),存在如下问题:
- 选择较小的学习率会使得梯度较大的自变量迭代过慢
- 选择较大的学习率会使得梯度较小的自变量迭代发散
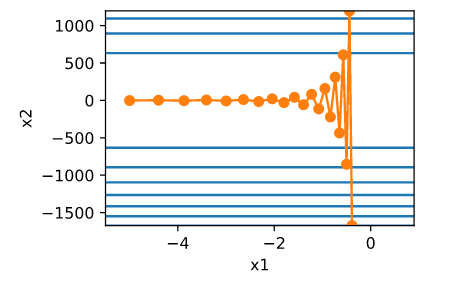 因此,自然而然想到,要解决这一问题,不同自变量应该根据梯度的不同有不同的学习率。本篇介绍的几种优化算法都是基于这个思想的。
因此,自然而然想到,要解决这一问题,不同自变量应该根据梯度的不同有不同的学习率。本篇介绍的几种优化算法都是基于这个思想的。
1 - AdaGrad算法
使用一个小批量随机梯度$g_t$按元素平方的累加变量$s_t$,在时间步0,AdaGrad将$s_0$中每个元素初始化为0,其更新公式为:
$$s_t\leftarrow s_{t-1}+g_t\odot g_t$$
$$x_t\leftarrow x_{t-1}-\frac{\eta}{\sqrt{s_t+\epsilon}}\odot g_t$$
其中$\odot$是按元素相乘,$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数(如$10^{-6}$)。
2 - RMSProp算法
由于AdaGrad算法的机制,导致每个元素的学习率在迭代过程中只能降低或者不变,因此很可能出现早期迭代到不好的极值点之后,由于学习率太小而无法冲出这个极值点导致最后收敛到的解不优,为了解决这一问题,RMSProp是基于AdaGrad算法做了一点小修改,其更新公式为:
$$s_t\leftarrow \gamma s_{t-1}+(1-\gamma)g_t\odot g_t$$
$$x_t\leftarrow x_{t-1}-\frac{\eta}{\sqrt{s_t+\epsilon}}\odot g_t$$
其中,$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数(如$10^{-6}$)。另外,比AdaGrad多了超参数$\gamma\in [0, 1)$,$s_t$可以看作是最近$\frac{1}{(1-\gamma)}$个时间步的小批量随机梯度平方项的加权平均,从而使得每个元素的学习率在迭代过程中不再一直降低或者不变。具体可以理解为:
- 如果最近的时间步梯度平方加权累积较小,说明梯度较小,那么学习率会增加
- 如果最近的时间步梯度平方加权累计较大,说明梯度较大,那么学习率会减小
有了如上机制,可以使得收敛稳定的同时,有一定几率冲出不优解,而使得最后收敛结果和开始的迭代表现相关性降低。
3 - AdaDelta算法
AdaDelta算法和RMSProp算法一样,使用小批量随机梯度$g_t$按元素平方的指数加权移动平均变量$s_t$,在时间步为0时,所有元素被初始化为0,其更新公式为:
$$s_t\leftarrow \rho s_{t-1}+(1-\rho)g_t\odot g_t$$
$$g_{t}^{'} \leftarrow \sqrt{\frac{\Delta x_{t-1}+\epsilon }{s_t+\epsilon}}\odot g_t$$
$$x_t\leftarrow t_{t-1}-g_{t}^{'}$$
$$\Delta x_t\leftarrow \rho \Delta x_{t-1} + (1-\rho)g_{t}^{'}\odot g_{t}^{'}$$
其中,$\epsilon$是为了维持数值稳定性而添加的常数(如$10^{-5}$)。另外,AdaDelta算法没有学习率这个超参,而是通过$\Delta x_t$来记录自变量变化量$g_t^'$按元素平方的指数加权移动平均,如果不考虑$\epsilon$的影响,AdaDelta算法跟RMSProp算法的不同之处在于使用$\sqrt{\Delta x_{t-1}}$来替代学习率$\eta$。
4 - Adam算法
Adam算法使用了动量变量$v_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$s_t$,并在时间步0将它们中的每个元素初始化为0。其更新公式为:
$$v_t\leftarrow \beta_1 v_{t-1} + (1-\beta_1)g_t$$
$$s_t\leftarrow \beta_2 s_{t-1} + (1-\beta_2)g_t \odot g_t$$
$$\hat{v_t}\leftarrow \frac{v_t}{1-\beta^t_1}$$
$$\hat{s_t}\leftarrow \frac{s_t}{1-\beta^t_2}$$
$$g_t^{'}\leftarrow \frac{\eta \hat{v_t}}{\sqrt{\hat{s_t}}+\epsilon}$$
$$x_t\leftarrow x_{t-1}-g_t^{'}$$
其中,$\eta$是学习率,$\epsilon$是为了维持数值稳定性而添加的常数(如$10^{-8}$),超参数$\beta_1\in [0, 1)$建议设为0.9,超参数$\beta_2\in [0, 1)$建议设为0.999。
5 - 总结
综上分析,可以得出如下几个结论:
- AdaGrad、RMSProp、AdaDelta和Adam几个优化算法,目标函数自变量中每个元素都分别拥有自己的学习率;
- AdaGrad目标函数自变量中各个元素的学习率只能保持下降或者不变,因此当学习率在迭代早期降得较快且当前解依然不佳时,由于后期学习率过小,可能较难找到一个有用的解;
- RMSProp和AdaDelta算法都是解决AdaGrad上述缺点的改进版本,本质思想都是利用最近的时间步的小批量随机梯度平方项的加权平均来降低学习率,从而使得学习率不是单调递减的(当最近梯度都较小的时候能够变大)。不同的是,RMSProp算法还是保留了传统的学习率超参数,可以显式指定。而AdaDelta算法没有显式的学习率超参数,而是通过$\Delta x$做运算来间接代替学习率;
- Adam算法可以看成是RMSProp算法和动量法的结合。
6 - 参考资料
http://zh.d2l.ai/chapter_optimization/adagrad.html
http://zh.d2l.ai/chapter_optimization/rmsprop.html
http://zh.d2l.ai/chapter_optimization/adadelta.html
http://zh.d2l.ai/chapter_optimization/adam.html
优化算法:AdaGrad | RMSProp | AdaDelta | Adam的更多相关文章
- torch.optim优化算法理解之optim.Adam()
torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用,未来更多精炼的优化算法也将整合进来. 为了使用torch.optim,需先构造一个优化器对象Opti ...
- 深度学习优化算法Momentum RMSprop Adam
一.Momentum 1. 计算dw.db. 2. 定义v_db.v_dw \[ v_{dw}=\beta v_{dw}+(1-\beta)dw \] \[ v_{db}=\beta v_{db}+( ...
- Caffe源码-几种优化算法
SGD简介 caffe中的SGDSolver类中实现了带动量的梯度下降法,其原理如下,\(lr\)为学习率,\(m\)为动量参数. 计算新的动量:history_data = local_rate * ...
- 深度学习——优化器算法Optimizer详解(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- 【深度学习】深入理解优化器Optimizer算法(BGD、SGD、MBGD、Momentum、NAG、Adagrad、Adadelta、RMSprop、Adam)
在机器学习.深度学习中使用的优化算法除了常见的梯度下降,还有 Adadelta,Adagrad,RMSProp 等几种优化器,都是什么呢,又该怎么选择呢? 在 Sebastian Ruder 的这篇论 ...
- Adam优化算法
Question? Adam 算法是什么,它为优化深度学习模型带来了哪些优势? Adam 算法的原理机制是怎么样的,它与相关的 AdaGrad 和 RMSProp 方法有什么区别. Adam 算法应该 ...
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- (CV学习笔记)梯度下降优化算法
梯度下降法 梯度下降法是训练神经网络最常用的优化算法 梯度下降法(Gradient descent)是一个 ==一阶最优化算法== ,通常也称为最速下降法.要使用梯度下降法找到一个函数的 ==局部最小 ...
- 优化深度神经网络(二)优化算法 SGD Momentum RMSprop Adam
Coursera吴恩达<优化深度神经网络>课程笔记(2)-- 优化算法 深度机器学习中的batch的大小 深度机器学习中的batch的大小对学习效果有何影响? 1. Mini-batch ...
随机推荐
- “百度杯”CTF比赛 十月场 Hash 复现
进入题后老套路得到两个关键: 1.$hash=md5($sign.$key);the length of $sign is 8 2.key=123&hash=f9109d5f83921a551 ...
- 《JavaScript设计模式与开发实践》笔记第八章 发布-订阅模式
第八章 发布-订阅模式 发布-订阅模式描述 发布-订阅模式又叫观察者模式,它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知. 发布-订阅模式可以广泛应用于 ...
- openstack第六章:dashboard
第六篇horizon— Web管理界面 一.horizon 介绍: 理解 horizon Horizon 为 Openstack 提供一个 WEB 前端的管理界面 (UI 服务 )通过 ...
- day11(函数参数,函数对象,打散机制,函数嵌套调用)
一,复习 # 什么是函数:具体特定功能的代码块 - 特定功能代码块作为一个整体,并给该整体命名,就是函数 # 函数的优点: # 1.减少代码的冗余 # 2.结构清晰,可读性强 # 3.具有复用性,开发 ...
- iOS 打包.framework(包括第三方、图片、xib、plist文件)详细步骤及需要注意的地方
https://www.cnblogs.com/yk123/p/9340268.html // 加载自定义名称为Resources.bundle中对应images文件夹中的图片// 思路:从mainb ...
- Django的ORM那些相关操作
一般操作 看专业的官网文档,做专业的程序员! 必知必会13条 <> all(): 查询所有结果 <> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象 & ...
- CSS中的opacity,不透明度的坑
opacity的用法示例如下 /* 值是0到1之间的数值 */ opacity:0.5 opacity设置在元素上的时候,会出现什么效果? 答曰:如果不设置opacity的话,会显示效果为A(可以理解 ...
- js中对象引用出现的问题
先看一个特别不符合直觉的代码 <script type="text/javascript"> var a = [1,2,3,4]; var b = [1,2,3,4]; ...
- NIO的初步入门
NIO java NIO简介 Java NIO 简介 是从java1.4版本开始引入的一个新的IO AP可以替代标准java IO API NIO与原来的IO有同样的作用和目的,但是使用方式完全不同 ...
- EntityFrameworkCore中的OnModelCreating
在我们使用EntityFrameworkCore作为数据库ORM框架的时候,不可避免的要重载DbContext中的一个虚方法OnModelCreating,那么这个方法到底是做什么的?到底有哪些作用呢 ...