machine learning 之 Neural Network 2
整理自Andrew Ng的machine learning 课程 week5.
目录:
- Neural network and classification
- Cost function
- Backpropagation (to minimize cost function)
- Backpropagation in practice
- Gradient checking
- Random initialization
- Assure structure and Train a neural network
前提:
训练数据集:${(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),...,(x^{(m)},y^{(m)})}$
L:神经网络的总的层数,total layers,如下图,L=4
$s_l$:第l层的单元数目,如下图,$s_1=3, s_2=5,...$
K:输出层的单元数,如下图,K=4
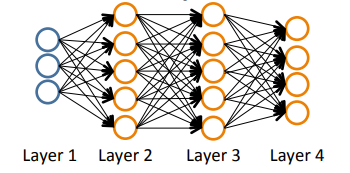
1、neural network and classification
对于二分类问题(binary classification):输出为0或1,K=1
对于多分类问题(Multi-class classification):输出为hot one编码形式,K为类别数目,类似如下:
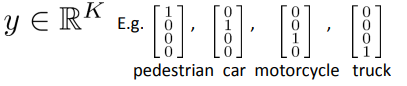
2、cost function
之前的文章中介绍过logistic regression的cost function为:
$J(\theta)=-\frac{1}{m}[\sum_{i=1}^m y^{(i)}logh_\theta(x^{(i)}) + (1-y^{(i)})log(1-h_\theta(x{(i)}))] + \frac{\lambda}{2m} \sum_{j=1}^n \theta_j^2$
more generally,在神经网络中,$h_\Theta(x) \in R^K,(h_\Theta(x))_i是第i个output$,神经网络的cost function为:
$J(\Theta)=-\frac{1}{m}[\sum_{i=1}^m \sum_{k=1}^K y_k^{(i)}log(h_\Theta(x^{(i)})_k) + (1-y_k^{(i)})log(1-(h_\Theta(x{(i)}))_k)] + \frac{\lambda}{2m} \sum_{l=1}^{L-1} \sum_{i=1}^{s_l} \sum_{j=1}^{s_{l+1}} (\Theta_{ji}^{(l)})^2$
相比于logistic regression:
- 需要把K个输出的损失相加,所以有了K个累加项;
- 在惩罚项里面,需要把除bias unit以外的所有的参数(除$\Theta_0以外的所有\Theta$)都进行惩罚;
3、Backpropagation
有了cost function之后,我们就需要minimize cost function,使用的就是backpropagation算法计算出进行参数更新的值(类似于梯度下降的偏导数),也就是神经网络的损失函数的偏导数:
梯度计算:
- 首先进行forward propagation,计算出每一层的单元值(包括输出层的值);(上一篇文章的内容)
- 进行backpropagation:(以前提中的神经网络为例)
设定$\delta_k^{(l)}$:为第l层上第j个结点的误差error,那么$\delta_j^{(4)}=a_j^{(4)}-y_j$,给出 $ \delta^{(l)}=(\theta^{(l)})^T\delta^{(l+1)}.*g^{'}(z^{(l)}) $,其中$g^{'}(z^{(l)})=a^{(l)}.*(1-a^{(l)})$
- 注意:没有$\delta^{(1)}$,因为$\delta^{(1)}$是观测数据,不存在误差一说,由于在此处计算误差是从后往前,所以这个算法被称为backpropagation
- 给出公式 $\frac{\partial J(\theta)}{\partial \theta_{ij}^{(l)}}=a_j^{(l)}\delta_i^{(l+1)}$
- 对于每一个训练数据,计算它们的偏导数,并且将其相加,$\Delta^{(l)}:=\Delta^{(l)}+\delta^{(l+1)}(a^{(l)})^T$
- 在所有的训练数据处理完之后,计算损失函数对每一个参数的偏导数,也就是参数的更新参数,$D_{ij}^{(l)}=\frac{1}{m}\Delta_{ij}^{(l)}+\lambda\Theta_{ij}^{(l)}$,当j为0时,$\lambda$为0($\theta_0$不惩罚)
4、Backpropagation in practice
unrolling parameters:把矩阵形式的参数展开成向量,为了使用已有的函数对损失函数进行最小化运算;(matrix to vector)
reshape:vector to matrix,在计算偏导数和损失函数时,矩阵运算
5、Gradient checking
做了backpropagation计算了损失函数对每个参数的偏导数之后,我们需要做一个checking来确定偏导数的计算是否正确,数值计算梯度如图所示:
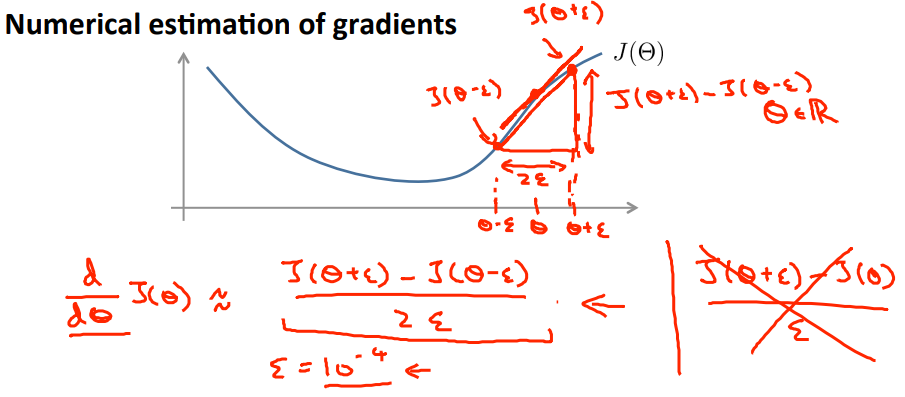
计算公式为:($\varepsilon$取一个很小的值,领域的概念)
$\frac{J(\theta+\varepsilon)-J(\theta-\varepsilon)}{2\varepsilon}$
对于所有的参数,数值计算偏导数的公式如下:

如果数值计算的梯度和backpropagation算法计算的梯度是近似相等的话,就说明我们的backpropagation做对了,可以继续用backpropagation去计算梯度,训练模型
注意:在确定了backpropagation做对了之后,应该停止gradient checking,因为这种数值计算梯度的方法是十分的computational expensive,如果不停止的话,模型训练的速度会相当的慢
6、Random initalization
如何设定$\Theta$的初始值?在logistic regression中,初始的参数$\theta$被设定为0,那么如果在neural network中也做这种设定呢?
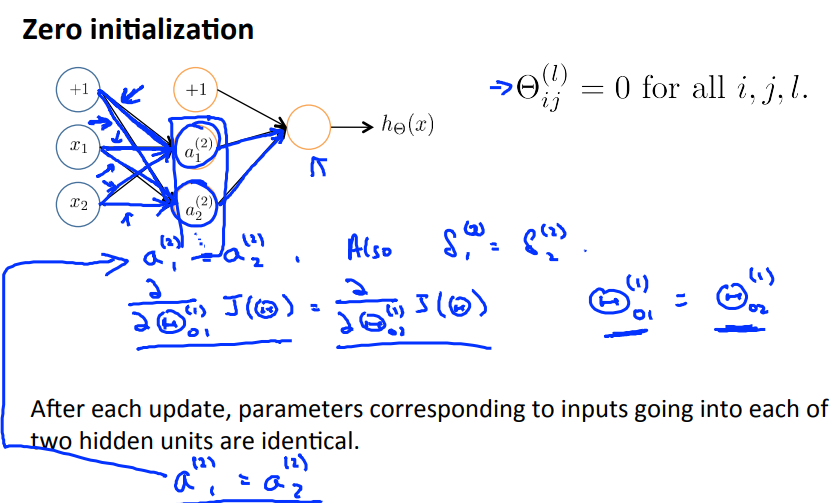
如上所示,如果设定初始的参数全部为0,那么隐藏层的所有的单元的值都会是一样的(在),同时,由后往前传的error $\delta$也会是一样的,由此一来,损失函数对同一个输入对应的参数的偏导数也是一样的,也就是说,虽说是同步更新参数,但其实在网络中同一输入出发的的参数永远都是一样的,也就是说计算出来的隐含单元的值也永远是一样的,$a_1^{(2)}$永远等于$a_2^{(2)}$,如果有更多的隐含单元的话,也是一样的值。无论隐含层有多少的单元数,它们的值都是相同的,这就是一个极度冗余的现象,而且也根本没有发挥出来多个单元该有的作用。
以上问题称之为symmetry breaking,解决的办法是random initialization,设定初始参数时不可以设置为0,而是一些较小的随机数
7、Assure structure and Train a neural network
对于一个neural network的工程,我们首先需要做的是确定这个神经网络的结构(层数,每一层的单元数):
- 输入单元数:$x^{(i)}$的维度($x^{(i)}$代表第i个训练数据)
- 输出单元数:类别数
- 每一个隐含层的单元数:通常多多益善
- 默认一个hidden layer,如超过了一个hidden layer,那就默认每一层的单元数相同
结构确定之后就可以开始训练模型了:
- 随机初始化权重参数$\Theta$
- 使用forward propagation计算每一层的单元的值(包括输出层的值)
- 根据以上公式计算cost function
- 使用backpropagation计算偏导数
- 使用gradient checking去验证backpropagation是否做的正确,若正确,则立即停止gradient checking
- 使用gradient descent或者其他的优化函数去最小化cost function,得到权重参数$\Theta$
注意这里的损失函数不是一个凸函数,所以我们很有可能得到的是一个局部最小值,这是ok的。
machine learning 之 Neural Network 2的更多相关文章
- Python -- machine learning, neural network -- PyBrain 机器学习 神经网络
I am using pybrain on my Linuxmint 13 x86_64 PC. As what it is described: PyBrain is a modular Machi ...
- machine learning 之 Neural Network 1
整理自Andrew Ng的machine learning课程week 4. 目录: 为什么要用神经网络 神经网络的模型表示 1 神经网络的模型表示 2 实例1 实例2 多分类问题 1.为什么要用神经 ...
- machine learning 之 Neural Network 3
整理自Andrew Ng的machine learning课程week6. 目录: Advice for applying machine learning (Decide what to do ne ...
- Machine Learning:Neural Network---Representation
Machine Learning:Neural Network---Representation 1.Non-Linear Classification 假设还採取简单的线性分类手段.那么会面临着过拟 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1
3.Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.1 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.2
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.2 http://blog.csdn.net/sunbow0 ...
- Spark MLlib Deep Learning Convolution Neural Network (深度学习-卷积神经网络)3.3
3.Spark MLlib Deep Learning Convolution Neural Network(深度学习-卷积神经网络)3.3 http://blog.csdn.net/sunbow0 ...
- 《MATLAB Deep Learning:With Machine Learning,Neural Networks and Artificial Intelligence》选记
一.Training of a Single-Layer Neural Network 1 Delta Rule Consider a single-layer neural network, as ...
- Deep learning与Neural Network
深度学习是机器学习研究中的一个新的领域,其动机在于建立.模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解释数据,例如图像,声音和文本.深度学习是无监督学习的一种. 深度学习的概念源于人工神经网络的 ...
随机推荐
- sql中InnoDB和MyISAM的区别
InnoDB和MyISAM是许多人在使用MySQL时最常用的两个表类型 1,MyISAM类型的表强调的是性能,其执行数度比InnoDB类型更快,但是不提供事务支持等高级处理,往往被认为只适合小项目:而 ...
- Android开发学习之路--Annotation注解简化view控件之初体验
一般我们在写android Activity的时候总是会在onCreate方法中加上setContentView方法来加载layout,通过findViewById来实现控件的绑定,每次写这么多代码总 ...
- 04 SimpleAdapter
<span style="font-size:18px;">package com.fmyboke; import java.util.ArrayList; impor ...
- Qualcomm平台camera调试移植入门
1 camera基本代码架构 高通平台对于camera的代码组织,大体上还是遵循Android的框架:即上层应用和HAL层交互,高通平台在HAL层里面实现自己的一套管理策略:在kernel中实现se ...
- 看人装X,我就来气,开启极限装X模式
本文书写,纯属扯淡,请勿观看 4进制比二进制更合理,在01的状态中添加了两种状态,从无到有和从有到无的两种过度状态. 如果非要用数值表示,用概率表示.01作为近代计算机的基础,但终究淘汰,构成下一代计 ...
- JSP标签JSTL(2)--流程控制
对于流程控制,单纯的用jsp脚本,显得很是繁琐,尤其是遇到if判断的时候,写代码的时候就需要特别的小心,因为极有可能会出现符号不匹配的状况.但是利用标签语言就会大大的改善这一状况. 流程控制 if标签 ...
- 设计比较好,有助于学习的Github上的iOS App源码 (中文)
Github版 中文 : TeamTalk 蘑菇街. 开源IM. 电商强烈推荐. MyOne-iOS 用OC写的<一个> iOS 客户端 zhihuDaily 高仿知乎日报 Coding ...
- protobuf代码生成
windows : 1,两个文件:proto.exe, protobuf-java-2.4.1.jar 2,建立一个工程TestPb,在下面建立一个proto文件件,用来存放[.proto]文件 3, ...
- VC++读取图像RGB值
代码: #include <iostream> #include <fstream> #include <string> #include <windows. ...
- 使用go reflect实现一套简易的rpc框架
go jsonrpc 在实际项目中,我们经常会碰到服务之间交互的情况,如何方便的与远端服务进行交互,就是一个需要我们考虑的问题. 通常,我们可以采用restful的编程方式,各个服务提供相应的web接 ...