Unity 用ml-agents机器学习造个游戏AI吧(2)(入门DEMO)
前言:上一篇博文已经介绍了Unity ml-agents的环境配置(https://www.cnblogs.com/KillerAery/p/10629963.html)了。
个人建议先敲demo再摸清概念比较容易上手,因此本文先提供一个demo示例简单阐述下。
由于过了差不多2年,Unity ml-agents项目API已经更新了很多,以前的demo教程已经不适合了,因此决定翻新Unity ml-agents机器学习系列博客。
本次示例:训练一个追踪红球的白球AI

1. 新建Unity项目,导入package
进入Unity项目,在上方 Window => Package Manager,,然后安装Barracuda这个package(如果没看见,一般就是没有显示All packages或没显示preview package):
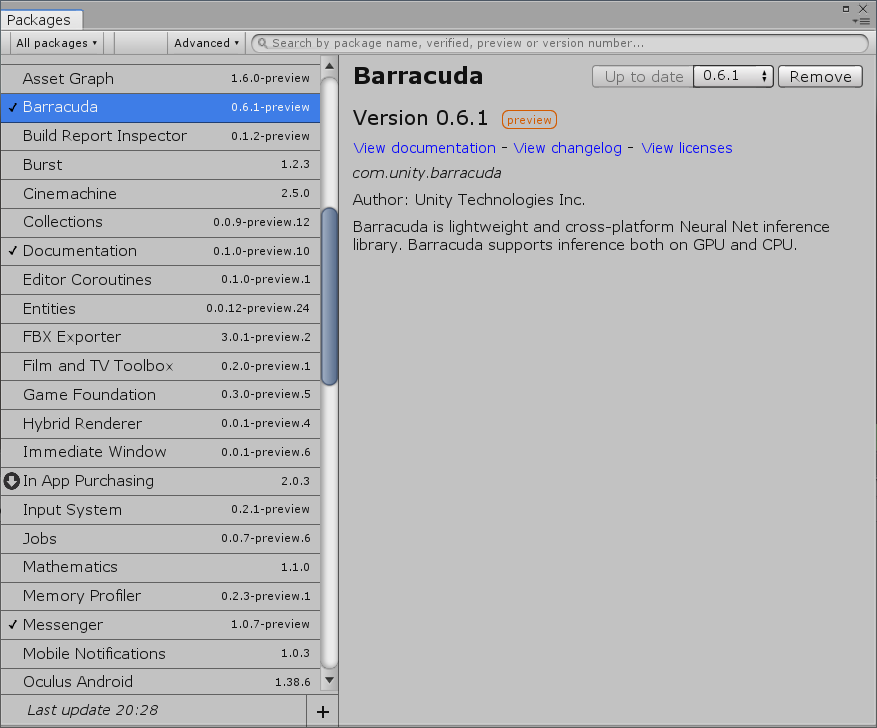
并将之前下载的ml-agents项目com.unity.ml-agents目录下Editor、Plugin、Runtime复制进新建Unity项目里(建议放在Assets文件夹内)
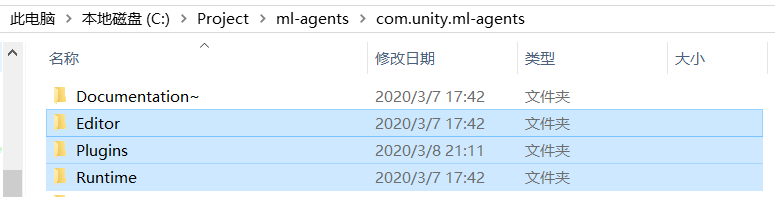
旧版本ml-agents项目UnitySDK文件夹已被分割为com.unity.ml-agents文件夹(Unity ml-agents包)和Project文件夹(示例项目,含若干个机器学习示例demo)。
2. 编写Agent脚本
RollerAgent 是将用于智能体对象的组件脚本:
//RollerAgent.cs
using UnityEngine;
using MLAgents;
using MLAgents.Sensors;
public class RollerAgent : Agent
{
public Transform Target;
public float speed = 10;
private Rigidbody rBody;
void Start()
{
rBody = GetComponent<Rigidbody>();
}
//收集观察结果
public override void CollectObservations(VectorSensor sensor)
{
//观察目标球和智能体的位置
sensor.AddObservation(Target.position);
sensor.AddObservation(this.transform.position);
//观察智能体的速度
sensor.AddObservation(rBody.velocity.x);
sensor.AddObservation(rBody.velocity.z);
//在这里因为目标球是不会动的,智能体也不会在y轴上又运动,所以没有必要观察这些值的变化。
//sensor.AddObservation(rBody.velocity.y);
}
//处理动作,并根据当前动作评估奖励值
public override void AgentAction(float[] vectorAction)
{
//------ 动作处理
// 接受两个动作数值
Vector3 controlSignal = Vector3.zero;
controlSignal.x = vectorAction[0];
controlSignal.z = vectorAction[1];
rBody.AddForce(controlSignal * speed);
//------ 奖励信号
float distanceToTarget = Vector3.Distance(this.transform.position, Target.position);
// 到达目标球
if (distanceToTarget < 1.42f)
{
//奖励值+1.0f
SetReward(1.0f);
Done();
}
// 掉落场景外
if (this.transform.position.y < 0)
{
Done();
}
}
//启发函数,玩家可手动操控智能体,用于手动调试智能体或启发模仿学习。
public override float[] Heuristic()
{
var action = new float[2];
action[0] = -Input.GetAxis("Horizontal");
action[1] = Input.GetAxis("Vertical");
return action;
}
//Reset时调用
public override void AgentReset()
{
if (this.transform.position.y < 0)
{
//如果智能体掉下去,则重置位置+重置速度
this.rBody.angularVelocity = Vector3.zero;
this.rBody.velocity = Vector3.zero;
this.transform.position = new Vector3(0, 0.5f, 0);
}
//将目标球重生至一个新的随机位置
Target.position = new Vector3(UnityEngine.Random.value * 8 - 4, 0.5f, UnityEngine.Random.value * 8 - 4);
}
}
Agent,即智能体,含有感知和行为——它通过观察环境然后做出相应的行为。在最常使用的强化学习里,智能体的训练模型类似一个黑盒。
每一次模拟步长中,智能体的感知会作为黑盒的输入,然后黑盒会输出行为选择,然后根据行为选择来让智能体做出行为。
当我们需要创建一个智能体类型时,让其继承Agent类,以用于重写智能体CollectObservations,AgentAction,AgentReset等方法。
CollectObservations()
- 每一个模拟步长都会被调用。
- 负责收集智能体的对环境的观察信息。
这部分类似于黑箱子的输入。值得注意的是,所需观察的信息越少越好。因此,我们需要尽可能减少不必要的观察信息,这会让训练变得更加快速、准确。
AgentAction()
- 每一个模拟步长都会被调用。
- 负责接受决策的行为选择从而让智能体做出行为。示例里,通过行为选择的2个float输入值来驱使球体移动,一旦掉出场景外,便调用Done()。
- 负责评估此步长的reward(奖励值)。示例里,只要触碰到目标球即可获得一定的reward。
如何根据实际问题设计reward往往是一个难点,设计的不好(例如部分奖励值过大)容易造成网络不收敛。
Heuristic()
- 通过玩家亲自操控智能体来输出行为选择。
亲自操控智能体可用于模仿学习或调试智能体的行为。
AgentReset()
- Done()被调用时,它才被调用。
- 负责重新设置场景,来准备下一次session。
当Done()被调用时,这意味着一次session的结束。然后深度强化学习模型评估整个session的reward并且重新设置场景,以准备下一次session。在示例里,为了让训练更加有效更加广泛化,因此给目标球设置的是随机位置(实际上智能体球也应该设置随机位置)。
3. 搭建好游戏场景
创建一个地板:
创建一个小球:
创建一个智能体(RollerAgent):
先创建一个带刚体的球体对象,然后我们需要给它挂载RollerAgent脚本(挂载后自动额外挂载BehaviorParameters脚本用于配置)和DecisionRequester脚本。
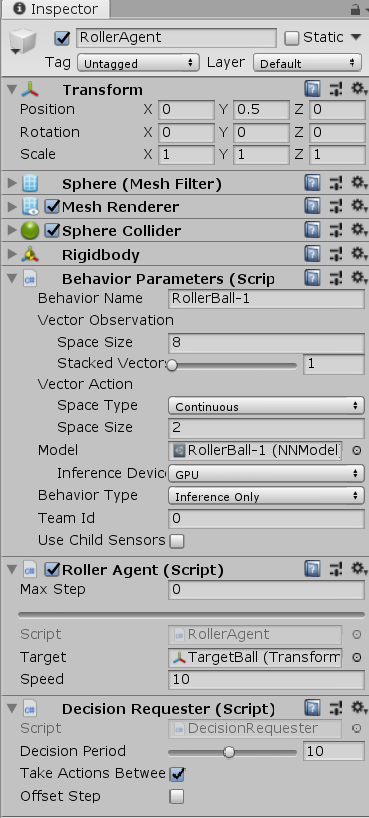
4. 调整脚本参数
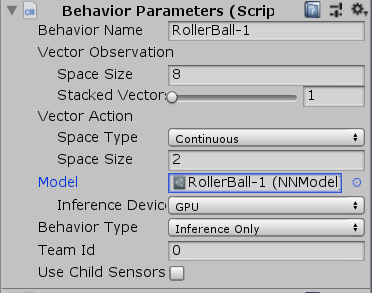
Behavior Parameters
每个Agent还必须得附带一个行为参数脚本,行为参数脚本用于定义智能体如何做出决策。
Vector Observation Space Size:观察信息的大小。在本示例中应调整为8,因为示例智能体脚本总共需要观察的特征元素为2个3D位置+2个1D速度,因此总共需要空间为8个float大小。
Vector Action Space Size:动作矢量的大小。在本示例中应调整为2,因为智能体脚本里接受2个浮点型动作输入。动作矢量的元素可以选择两种类型:一种是离散型的整型数值,适用于离散动作,例如下棋的位置选择;另一种则是连续性的浮点数值,适用于连续动作,例如3个float值可以代表一个施加到智能体刚体的力或力矩。
Inference Device:调整为GPU,从而使用GPU来训练。
Behavior Type:行为类型,主要有Default、Heuristic、Inference三种模式。
- Default:默认训练模式,用于一般的强化学习。
- Heuristic Only:启发模式,玩家亲自操控智能体,可用于模仿学习或调试游戏场景。
- Inference Only:推理模式,运行训练好的模型。
Roller Agent
Max Step:决定智能体最多可以有多少步决策,超过限制后则强制Done。特殊地,设置为0意思是不限制步数。在本示例中应调整为0。
Decision Requester
Decision Period:决策间隔。在本示例中应调整为10。
目前场景预览:


在这里,最好先Behavior Type切换成Heuristic Only模式用于调试游戏场景,运行Unity场景后可尝试自己用WASD键盘操控小球,测试游戏场景是否OK。然后确认无问题后再切换回Default。
5. 开始训练
然后现在可以打开开始菜单,直接使用cmd命令窗口,
cd到之前下载ml-agents项目的目录里
cd C:\Downloads\ml-agents
再输入激活ml-agents环境:
activate ml-agents
开启训练:
mlagents-learn config/config.yaml --run-id=RollerBall-1 --train
- config/config.yaml是训练配置文件,RollerBall-1是你给训练出来的模型取的名字
- 此外注意config/config.yaml是不存在的,可以自己仿照官方的示例yaml文件修改配置而新建的。
下面是config.yaml示例:
default:
trainer: ppo
batch_size: 10
beta: 5.0e-3
buffer_size: 100
epsilon: 0.2
gamma: 0.99
hidden_units: 128
lambd: 0.95
learning_rate: 3.0e-4
max_steps: 3.0e5
memory_size: 256
normalize: false
num_epoch: 3
num_layers: 2
time_horizon: 64
sequence_length: 64
summary_freq: 1000
use_recurrent: false
use_curiosity: false
curiosity_strength: 0.01
curiosity_enc_size: 128
reward_signals:
extrinsic:
strength: 1.0
gamma: 0.99
有关config参数具体配置将放在文末附录。

当出现如下画面:
返还到Unity,点下运行键,那么你就会看到Unity执行训练。
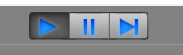

你的命令窗口也会时刻告诉你训练阶段的信息:
- Step:模拟的步长次数
- Time Elapsed:所用时间
- Mean Reward:奖励平均值
- Std of Reward:奖励标准方差值
一般来说,随着训练的进行,奖励平均值越来越高,奖励标准方差值越来越低。这意味着智能体的行为越来越稳定趋向于获奖收益最高的行为。
现在可以去挂机等待结果了,亦或者在某个时间停止Unity场景运行。那么ml-agents会将目前为止训练出来的数据模型(.nn文件)保存到ml-agents\models目录下。
6. 将训练过的模型整合到Unity中
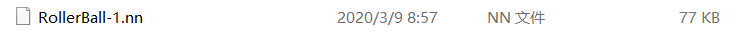
将训练出来的nn文件导入到Unity项目文件夹中,并在智能体Behavior Parameters脚本上的Model选择刚刚导入的nn文件;然后将Behavior Type调整为Inference Only。
运行Unity场景,看看你跑出来的模型的蠢样了(笑)。

附录
config文件配置
参数配置(翻修中):
| 参数名 | 描述 | 适用算法 |
|---|---|---|
| trainer | The type of training to perform: "ppo", "sac", "offline_bc" or "online_bc". | PPO, SAC |
| batch_size | The number of experiences in each iteration of gradient descent. | PPO, SAC |
| batches_per_epoch | In imitation learning, the number of batches of training examples to collect before training the model. | |
| beta | The strength of entropy regularization. | PPO |
| buffer_size | The number of experiences to collect before updating the policy model. In SAC, the max size of the experience buffer. | PPO, SAC |
| buffer_init_steps | The number of experiences to collect into the buffer before updating the policy model. | SAC |
| epsilon | Influences how rapidly the policy can evolve during training. | PPO |
| hidden_units | The number of units in the hidden layers of the neural network. | PPO, SAC |
| init_entcoef | How much the agent should explore in the beginning of training. | SAC |
| lambd | The regularization parameter. | PPO |
| learning_rate | The initial learning rate for gradient descent. | PPO, SAC |
| learning_rate_schedule | Determines how learning rate changes over time. | PPO, SAC |
| max_steps | The maximum number of simulation steps to run during a training session. | PPO, SAC |
| memory_size | The size of the memory an agent must keep. Used for training with a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
| normalize | Whether to automatically normalize observations. | PPO, SAC |
| num_epoch | The number of passes to make through the experience buffer when performing gradient descent optimization. | PPO |
| num_layers | The number of hidden layers in the neural network. | PPO, SAC |
| behavioral_cloning | Use demonstrations to bootstrap the policy neural network. See Pretraining Using Demonstrations. | PPO, SAC |
| reward_signals | The reward signals used to train the policy. Enable Curiosity and GAIL here. See Reward Signals for configuration options. | PPO, SAC |
| save_replay_buffer | Saves the replay buffer when exiting training, and loads it on resume. | SAC |
| sequence_length | Defines how long the sequences of experiences must be while training. Only used for training with a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
| summary_freq | How often, in steps, to save training statistics. This determines the number of data points shown by TensorBoard. | PPO, SAC |
| tau | How aggressively to update the target network used for bootstrapping value estimation in SAC. | SAC |
| time_horizon | How many steps of experience to collect per-agent before adding it to the experience buffer. | PPO, SAC |
| train_interval | How often to update the agent. | SAC |
| num_update | Number of mini-batches to update the agent with during each update. | SAC |
| use_recurrent | Train using a recurrent neural network. See Using Recurrent Neural Networks. | PPO, SAC |
- PPO = Proximal Policy Optimization
- SAC = Soft Actor-Critic
- BC = Behavioral Cloning (Imitation)
- GAIL = Generative Adversarial Imitaiton Learning
参考
另外一提,最新的介绍文档资料示例等都在Unity官方机器学习的github项目,感兴趣可以持续保持关注它的更新:
[1] Unity官方机器学习的github项目 https://github.com/Unity-Technologies/ml-agents
[2] Unity官方博客机器学习概念详解(1) https://blogs.unity3d.com/2017/12/11/using-machine-learning-agents-in-a-real-game-a-beginners-guide/
[3] Unity官方博客机器学习概念详解(2) https://blogs.unity3d.com/2017/06/26/unity-ai-themed-blog-entries/
[4] Unity ml-agents概念详解国内翻译博客 https://blog.csdn.net/u010019717/article/details/80382933
Unity 用ml-agents机器学习造个游戏AI吧(2)(入门DEMO)的更多相关文章
- Unity 用ml-agents机器学习造个游戏AI吧(1)(Windows环境配置)
前言:以前觉得机器学习要应用于游戏AI,还远得很. 最近看到一些资料后,突发兴致试着玩了玩Unity机器学习,才发觉机器学习占领游戏AI的可能性和趋势. Unity训练可爱柯基犬Puppo 机器学习训 ...
- 游戏AI之初步介绍(0)
目录 游戏AI是什么? 游戏AI和理论AI 智能的假象 (更新)游戏AI和机器学习 介绍一些游戏AI 4X游戏AI <求生之路>系列 角色扮演/沙盒游戏中的NPC 游戏AI 需要学些什么? ...
- 【使用Unity开发Windows Phone上的2D游戏】(1)千里之行始于足下
写在前面的 其实这个名字起得不太欠当,Unity本身是很强大的工具,可以部署到很多个平台,而不仅仅是可以开发Windows Phone上的游戏. 只不过本人是Windows Phone 应用开发出身, ...
- Unity教程之-基于行为树与状态机的游戏AI
AI.我们的第一印象可能是机器人,现在主要说在游戏中的应用.关于AI的相关文章我们在前面也提到过,详细请戳这现代的计算机游戏中已经大量融入了AI元素,平时我们进行游戏时产生的交互都是由AI来完成的.比 ...
- AI Boot Camp 分享之 ML.NET 机器学习指南
今天在中国七城联动,全球134场的AI BootCamp胜利落幕,广州由卢建晖老师组织,我参与分享了一个主题<ML.NET 机器学习指南和Azure Kinect .NET SDK概要>, ...
- 游戏AI之路径规划(3)
目录 使用路径点(Way Point)作为节点 洪水填充算法创建路径点 使用导航网(Navigation Mesh)作为节点 区域分割 预计算 路径查询表 路径成本查询表 寻路的改进 平均帧运算 路径 ...
- 游戏AI之决策结构—有限状态机/行为树(2)
目录 有限状态机 行为树 控制节点 条件节点 行为节点 装饰节点 总结 额外/细节/优化 游戏AI的决策部分是比较重要的部分,游戏程序的老前辈们留下了两种经过考验的用于AI决策的结构: 有限状态机 行 ...
- 做游戏长知识------基于行为树与状态机的游戏AI(一)
孙广东 2014.6.30 AI. 我们的第一印象可能是机器人,如今主要说在游戏中的应用. 现代的计算机游戏中已经大量融入了AI元素,平时我们进行游戏时产生的交互都是由AI来完毕的.比方在RPG游戏中 ...
- 游戏AI的综合设计
原地址:http://www.cnblogs.com/cocoaleaves/archive/2009/03/23/1419346.html 学校的MSTC要出杂志,第一期做游戏专题,我写了一下AI, ...
随机推荐
- 转载 Elasticsearch开发环境搭建(Eclipse\MyEclipse + Maven)
概要: 1.使用Eclipse搭建Elasticsearch详情参考下面链接 2.Java Elasticsearch 配置 3.ElasticSearch Java Api(一) -添加数据创建索引 ...
- oracle中通过sql查询sde中图形面积
select st_area(shape) from XAG2011430200000M_DLTB t where objectid=330
- linux监控系统的状态
1.命令w的第一行和uptime或者用upload2.system load averages 表示单位时间短内活动的进程数3.查看cpu的个数和核数processor.physical id 4.v ...
- SSH项目的pom.xml文件
<!-- 属性 --> <properties> <spring.version>4.2.4.RELEASE</spring.version> < ...
- Python_heapq
import heapq #导入heapq堆模块 import random data = random.sample(range(1000),10) print(data) heapq.heapif ...
- JAVA中写时复制(Copy-On-Write)Map实现
1,什么是写时复制(Copy-On-Write)容器? 写时复制是指:在并发访问的情景下,当需要修改JAVA中Containers的元素时,不直接修改该容器,而是先复制一份副本,在副本上进行修改.修改 ...
- 队列Queue和栈
1.队列Queue是常用的数据结构,可以将队列看成特殊的线性表,队列限制了对线性表的访问方式,只能从线性表的一段添加(offer)元素, 从另一段取出(poll)元素,队列遵循先进先出的原则. 2.J ...
- codeforces 982D Shark
题意: 给出一个数组,删除大于等于k的数字,使得其满足以下条件: 1.剩余的连续的段,每一段的长度相等: 2.在满足第一个条件的情况下,段数尽可能多: 3.在满足前两个条件的情况下,k取最小的. 求k ...
- 聊聊 Spring Boot 2.x 那些事儿
本文目录: 即将的 Spring 2.0 - Spring 2.0 是什么 - 开发环境和 IDE - 使用 Spring Initializr 快速入门 Starter 组件 - Web:REST ...
- 从JVM内存管理的角度谈谈JAVA类的静态方法和静态属性
在JVM中,内存分为两个部分,Stack(栈)和Heap(堆),这里,我们从JVM的内存管理原理的角度来认识Stack和Heap,并通过这些原理认清Java中静态方法和静态属性的问题. 一般,JVM的 ...