MySQL索引初探
一、什么是索引?
帮助数据库系统实现高效获取数据的数据结构
索引可以帮助我们快速地定位到数据而不需要每次搜索的时候都遍历数据库中的每一行。
二、常见实现方式有哪些?
常见索引模型有三种:哈希表、有序数组、搜索树
1.哈希表
(1)使用哈希表实现的索引称为哈希索引。

如上图所示,我们将一系列的最终的键值通过哈希函数转化为存储实际数据桶的地址数值。值本身存储的地址就是基于哈希函数的计算结果,而搜索的过程就是利用哈希函数从元数据中推导出桶的地址。
(2)哈希冲突:不同的键值通过哈希函数换算得到了相同的值。
解决办法:
链地址法:将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。
再哈希法:这种方法是同时构造多个不同的哈希函数:Hi=RH1(key) i=1,2,…,k。当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生聚集,但增加了计算时间。
开放定址法:这种方法也称再散列法,其基本思想是:当关键字key的哈希地址p=H(key)出现冲突时,以p为基础,产生另一个哈希地址p1,如果p1仍然冲突,再以p为基础,产生另一个哈希地址p2,…,直到找出一个不冲突的哈希地址pi ,将相应元素存入其中。
建立公共溢出区:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
(3)优缺点:哈希索引会在进行相等性测试(等或者不等)时候具有非常高的性能,但是在进行比较查询、Order By 等更为复杂的场景下就无能为力。
2.有序数组
(1)按照给定的顺序排好序的数组
(2)优缺点:等值查询和比较查询性能非常优秀,但更新数据很繁琐,因为可能需要挪动大量的数据。所以这种索引结构适合静态存储引擎,存储不再改变的数据,如某学期的学生成绩信息。
3.搜索树
最简单的是二叉搜索树,然后有平衡二叉树、B树(B-Tree)和B+树(B+Tree),甚至B树。这些B树、B+树、B树都是一棵自平衡的搜索树,它类似普通的平衡二叉树,不同的一点是B-树允许每个节点有更多的子节点。B-树是专门为外部存储器设计的,如磁盘,它对于读取和写入大块数据有良好的性能,所以一般被用在文件系统及数据库中。
我们使用最多的两个存储引擎MyISAM和InnoDB都是 B+树 索引。而 B树 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B树 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
三、为何B树与B+树相比其他二叉搜索树更适合作为数据库索引的实现?
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘 I/O 消耗,相对于内存存取,I/O 存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘 I/O 操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘 I/O 的存取次数。
根据 B-Tree 的定义,可知检索一次最多需要访问 h 个节点。数据库系统的设计者巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次 I/O 就可以完全载入。(操作系统中一页大小通常是4KB)
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个节点只需一次 I/O。
而检索的时候,一次检索最多需要 h-1 次 I/O(根节点常驻内存),其渐进复杂度为
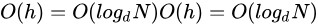
实际应用中,出度 d 是非常大的数字,通常超过 100,因此 h 非常小(通常不超过 3)。而其他搜索二叉树,h 明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的 I/O 渐进复杂度也为 O(h),效率明显比 B-Tree 差很多。
1.B树的特点:
(1)所有键值分布在整个树中
(2)任何关键字出现且只出现在一个节点中
(3)搜索有可能在非叶子节点结束
(4)在关键字全集内做一次查找,性能逼近二分查找算法
一棵高度为3的B树:(单独点开图片看全图)

2.B+Tree 是 的变种,有着比 B-Tree 更高的查询性能,其相较于 B-Tree 有了如下的变化:
- 有 m 个子树的节点包含有 m 个元素(B-Tree 中是 m-1)。
- 根节点和分支节点中不保存数据,只用于索引,所有数据都保存在叶子节点中。
- 所有分支节点和根节点都同时存在于子节点中,在子节点元素中是最大或者最小的元素。
- 叶子节点会包含所有的关键字,以及指向数据记录的指针,并且叶子节点本身是根据关键字的大小从小到大顺序链接。
一般在数据库系统或文件系统中使用的 B+Tree 结构都在经典 B+Tree 的基础上进行了优化,增加了顺序访问指针。
一棵高度为3的B+树:(单独点开图片看全图)

通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
四、InnoDB存储引擎中的索引
InnoDB中索引的每个节点默认大小是16KB。
InnoDB中的索引分为:主键索引(聚集索引)和非主键索引(二级索引)
主键索引中叶子节点存储的数据是整行的完整数据。二级索引中叶子节点存储的数据是主键值。表中没有主键则将唯一字段认作主键,若没有唯一字段则自己建一个主键列。
查询时根据若查询条件是根据主键查询,则直接通过主键索引查找得到值。如果是根据其他的查询条件查询则会先到二级索引中查询出对应的主键值,再根据主键值到主键索引中去查找。(这个也叫做回表)
1.索引维护:
(1)数据插入与删除
插入数据的时候可能是直接插入或需要将部分数据往后挪空出插入位置再插入。
特殊情况:如果插入慢歌已经满了的数据页,则需要新申请一个数据页,然后将满的数据页的部分数据挪过去,最后再进行插入。(这个过程被称为页分裂)
如果插入的数据是向某个满数据页的首或者尾插入,为了减少页分裂和数据移动,会先看与这个满数据页相邻的前后数据页是否也已经满了,如果未满则会将该待插入数据先放置到前或后的数据页,满才会进行页分裂。(这样做是为了增加空间利用率)
同样,由于相邻两页删除了部分数据,两页的空间利用率都变得很低,会将这两数据页进行合并。(这个歌过程被称为页合并)
(2)最左前缀
联合索引的最左N个字段,或者字符串索引的前N个字符。
(3)覆盖索引
如果查询条件是非主键索引字段(或联合索引的最左原则字段),查询结果是主键(或联合索引的字段),不用回表,直接返回结果,这样减少了磁盘读取次数。
(4)联合索引
对多个字段一起建立一个索引,根据字段顺序以最左前缀原则进行检索。
(5)索引下推
建立联合索引(name,age),查询语句如下:
SELECT * FROM 表名 WHERE name like "helle" AND age>18;
这条语句在MySQL5.6之前对name匹配的数据直接进行回表,而5.6之后的版本,会先把name匹配的数据中age<=18的数据再进行过滤掉最后才进行回表。
MySQL索引初探的更多相关文章
- MySQL 日志初探
目录 MySQL 日志初探 零.概述 一.Error Log(错误日志) 二.General Query Log(通用查询日志) 三.Slow Query Log (慢查询日志) 四.Binary L ...
- 深入MySQL索引
MySQL索引作为数据库优化的常用手段之一在项目优化中经常会被用到, 但是如何建立高效索引,有效的使用索引以及索引优化的背后到底是什么原理?这次我们深入数据库索引,从索引的数据结构开始说起. 索引原理 ...
- MySQL 索引
MySQL索引的建立对于MySQL的高效运行是很重要的,索引可以大大提高MySQL的检索速度. 打个比方,如果合理的设计且使用索引的MySQL是一辆兰博基尼的话,那么没有设计和使用索引的MySQL就是 ...
- MYSQL索引结构原理、性能分析与优化
[转]MYSQL索引结构原理.性能分析与优化 第一部分:基础知识 索引 官方介绍索引是帮助MySQL高效获取数据的数据结构.笔者理解索引相当于一本书的目录,通过目录就知道要的资料在哪里, 不用一页一页 ...
- MySQL索引原理及慢查询优化
原文:http://tech.meituan.com/mysql-index.html 一个慢查询引发的思考 select count(*) from task where status=2 and ...
- 【转】MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- [转]MySQL索引背后的数据结构及算法原理
摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持也各不相同,因此MySQL数据库支持多种索引类型,如BT ...
- MySQL索引类型总结和使用技巧以及注意事项
索引是快速搜索的关键.MySQL索引的建立对于MySQL的高效运行是很重要的.下面介绍几种常见的MySQL索引类型 在数据库表中,对字段建立索引可以大大提高查询速度.假如我们创建了一个 mytable ...
- MySQL索引背后的数据结构及算法原理【转】
本文来自:张洋的MySQL索引背后的数据结构及算法原理 摘要 本文以MySQL数据库为研究对象,讨论与数据库索引相关的一些话题.特别需要说明的是,MySQL支持诸多存储引擎,而各种存储引擎对索引的支持 ...
随机推荐
- API做翻页的两种思路
在开发API的时候,有时候数据太多了,就需要分页读取. 基于偏移量的分页(Offset-based) 这种方式就是会提供一个每页笔数(page size)来定义返回条目的最大数,提供一个页数(page ...
- Python爬虫入门教程 53-100 Python3爬虫获取三亚天气做旅游参照
爬取背景 这套课程虽然叫爬虫入门类课程,但是里面涉及到的点是非常多,十分检验你的基础掌握的牢固程度,代码中的很多地方都是可以细细品味的. 为什么要写这么一个小东东呢,因为我生活在大河北,那雾霾醇厚的很 ...
- Asp.Net Core&钉钉开发系列
阿里钉钉在商业领域的规模越来越大,基于钉钉办公的企业越来越多,将一个企业内现有用到的工具(如钉钉)能够更融入到他们的工作中,提高工作效率,那便需要开发者不断的学习.应用了,同时,个人也有一个预感,未来 ...
- 基于 HTTP 请求拦截,快速解决跨域和代理 Mock
近几年,随着 Web 开发逐渐成熟,前后端分离的架构设计越来越被众多开发者认可,使得前端和后端可以专注各自的职能,降低沟通成本,提高开发效率. 在前后端分离的开发模式下,前端和后端工程师得以并行工作. ...
- Wmyskxz文章目录导航附Java精品学习资料
前言:这段时间一直在准备校招的东西,所以一晃眼都好长时间没更新了,这段时间准备的稍微好那么一点点,还是觉得准备归准备,该有的学习节奏还是要有..趁着复习的空隙来整理整理自己写过的文章吧..好多加了微信 ...
- 实时语音趣味变声,大叔变声“妙音娘子”Get一下
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯游戏云 发表于云+社区专栏 游戏社交化是近年来游戏行业发展的重要趋势,如何提高游戏的社交属性已成为各大游戏厂商游戏策划的重要组成部 ...
- cocos creator主程入门教程(四)—— 网络通信
五邑隐侠,本名关健昌,10年游戏生涯,现隐居五邑.本系列文章以TypeScript为介绍语言. 前面已经介绍怎样加载资源.管理弹窗.开发一个网络游戏,难免要处理网络通信.有几点问题需要注意: 1.服务 ...
- Visual Studio 2019 发布活动 - 2019 年 4 月 2 日
Visual Studio 2019 发布活动 2019 年 4 月 2 日,星期二 | 上午 9:00 (PT) 围观: https://visualstudio.microsoft.com/zh- ...
- JavaScript 新语法详解:Class 的私有属性与私有方法
译者按: 为什么偏要用 # 符号? 原文:JavaScript's new #private class fields 译者:Fundebug 本文采用意译,版权归原作者所有 proposal-cla ...
- 2018-08-20 中文代码之Spring Boot集成H2内存数据库
续前文: 中文代码之Spring Boot添加基本日志, 源码库地址相同. 鉴于此项目中的数据总量不大(即使万条词条也在1MB之内), 当前选择轻量级而且配置简单易于部署的H2内存数据库比较合理. 此 ...