Spark2.4.0伪分布式环境搭建
一、搭建环境的前提条件
环境:ubuntu-16.04
hadoop-2.6.0
jdk1.8.0_161。
spark-2.4.0-bin-hadoop2.6。这里的环境不一定需要和我一样,基本版本差不多都ok的,但注意这里spark要和hadoop版本相对应。所需安装包和压缩包自行下载即可。
因为这里是配置spark的教程,首先必须要配置Hadoop,配置Hadoop的教程在Hadoop2.0伪分布式平台环境搭建。配置Java以及安装VMware Tools就自行百度解决哈,这里就不写了(因为教程有点长,可能有些地方有些错误,欢迎留言评论,我会在第一时间修改的)。
二、搭建的详细步骤
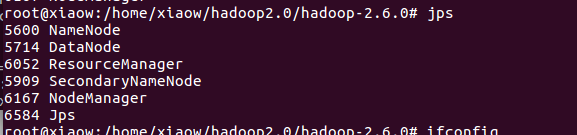
1、首先确保Hadoop伪分布式环境正在运行
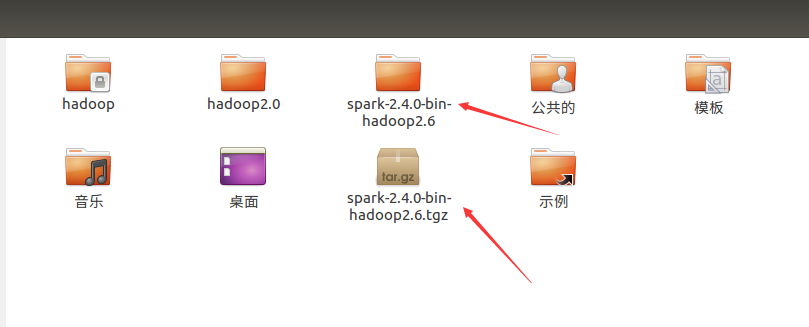
2、首先对spark安装包解压缩
tar -zxvf spark-2.4.0-bin-hadoop2.6
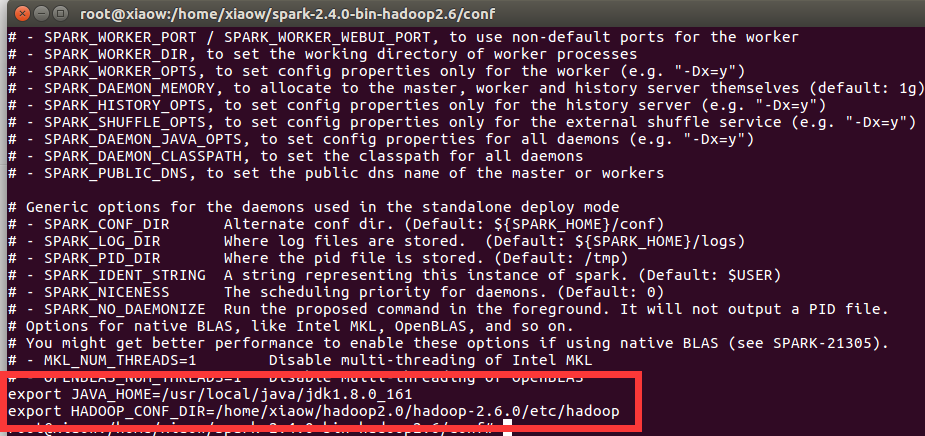
3、进入spark/conf修改配置文件
cd spark-2.4.0-bin-hadoop2.6/
cd conf/
cp spark-env.sh.template spark-env.sh
然后在spark-env.sh文件最后添加内容
vim spark-env.sh
4、配置环境变量
vim ~/.bashrc
在文件最后加入spark的路径

保存使其立即生效。
source ~/.bashrc
5、启动spark
cd ..
sbin/start-all.sh

jps查看进程
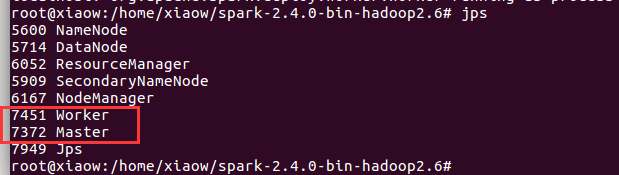
出现上面这些节点说明搭建成功。
6、webUI查看
http://localhost:8080/

7、若搭建成功的命令行界面,注意路径

退出命令为 :quit 。
Spark2.4.0伪分布式环境搭建的更多相关文章
- Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程
一.修改hosts文件 在主节点,就是第一台主机的命令行下; vim /etc/hosts 我的是三台云主机: 在原文件的基础上加上; ip1 master worker0 namenode ip2 ...
- Hadoop2.5.0伪分布式环境搭建
本章主要介绍下在Linux系统下的Hadoop2.5.0伪分布式环境搭建步骤.首先要搭建Hadoop伪分布式环境,需要完成一些前置依赖工作,包括创建用户.安装JDK.关闭防火墙等. 一.创建hadoo ...
- hive-2.2.0 伪分布式环境搭建
一,实验环境: 1, ubuntu server 16.04 2, jdk,1.8 3, hadoop 2.7.4 伪分布式环境或者集群模式 4, apache-hive-2.2.0-bin.tar. ...
- 在Win7虚拟机下搭建Hadoop2.6.0伪分布式环境
近几年大数据越来越火热.由于工作需要以及个人兴趣,最近开始学习大数据相关技术.学习过程中的一些经验教训希望能通过博文沉淀下来,与网友分享讨论,作为个人备忘. 第一篇,在win7虚拟机下搭建hadoop ...
- 【Hadoop】伪分布式环境搭建、验证
Hadoop伪分布式环境搭建: 自动部署脚本: #!/bin/bash set -eux export APP_PATH=/opt/applications export APP_NAME=Ares ...
- 大数据:Hadoop(JDK安装、HDFS伪分布式环境搭建、HDFS 的shell操作)
所有的内容都来源与 Hadoop 官方文档 一.Hadoop 伪分布式安装步骤 1)JDK安装 解压:tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/app 添加到系 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- HDFS 伪分布式环境搭建
HDFS 伪分布式环境搭建 作者:Grey 原文地址: 博客园:HDFS 伪分布式环境搭建 CSDN:HDFS 伪分布式环境搭建 相关软件版本 Hadoop 2.6.5 CentOS 7 Oracle ...
随机推荐
- JDK8安装时错误1335的解决
Win7安装JDK8 update65版本时,碰到错误1335,错误信息大概是一个cab文件损坏了,搜索了一下,有网站提供这个错误的修补工具,不过最终我没有下载这个工具,说是系统问题,但工具不是MS官 ...
- ubuntu 13.10 install wireshark
ubuntu 13.10 install wireshark 今天在使用java jsoup操作remote server的是否,在本地执行可以成功返回内容,然后打成jar包,使用shell在 ser ...
- Effective Java 第三版——40. 始终使用Override注解
Tips <Effective Java, Third Edition>一书英文版已经出版,这本书的第二版想必很多人都读过,号称Java四大名著之一,不过第二版2009年出版,到现在已经将 ...
- js中window对象的opener属性的一个坑
2018-05-08 17:48:33 今天我编写代码碰到了一个让我纠结了很久的坑,特别想在此说一下,让其他人避免我踏过的这个坑. 这个坑就是:在我自己写的子窗口中用opener属性却获取不到父窗口的 ...
- 利用百度地图api实现定位
使用百度地图api前需要先获取一个百度地图开放平台的访问应用AK, 获取百度地图开放平台访问应用AK方式:注册百度账号-->申请百度开发者-->获取密匙-->使用相关功能. 注册账号 ...
- (五)SpringBoot2.0基础篇- Mybatis与插件生成代码
SpringBoot与Mybatis合并 一.创建SpringBoot项目,引入相关依赖包: <?xml version="1.0" encoding="UTF-8 ...
- flush()清空文件缓存区
# 缓冲区:cpu 一级缓存 二级缓存 三级缓存 import time f =open('2.txt','a+' ,encoding='utf-8') f.write('helloworld\n') ...
- hi-nginx-javascript vs node.js
hi-nginx-1.4.9已经支持javascript,这意味着把javascript应用于后端开发,将不再只有nodejs这唯一的途径和方法.由于java本身对javascript的极好支持,使得 ...
- msql索引
从网上找了两种解决方案: 最近要给一个表加一个联合唯一索引,但是表中的两个联合健有重复值,导致无法创建: 解决方案一:ignore(会删除重复的记录(重复记录只保留一条,其他的删除),然后建立唯一索引 ...
- Mysql 查询缓存总结
Mysql 查询缓存总结 MySQL查询缓存解释 缓存完整的SELECT查询结果,也就是查询缓存.保存查询返回的完整结果.当查询命中该缓存,mysql会立刻返回结果,跳过了解析.优化和执行阶段, 查询 ...