比Redis更快:Berkeley DB面面观
比Redis更快:Berkeley DB面面观
Redis很火,最近大家用的多。从两年前开始,Memcached转向Redis逐渐成为潮流;
而Berkeley DB可能很多朋友还很陌生,首先,我们简单的介绍一下。
Berkeley DB介绍
- 历史悠久。Berkeley DB1991年发行第一版, 2006年被Oracle收购;
- Berkeley DB是一个嵌入式数据库系统,将其归类到内存数据库范畴没有问题;
使用Key-Value结构存储,本身不支持SQL,5.5版以后整合了SQLite,可使用sql进行查询;官方资料给出的评估是如果原生的bdb能让性能提升10倍,使用SqlLite之后,大概就只有2-3倍;sql的解析及底层的衔接耗时较多;
开源产品,使用的开源协议为: AFFERO GPL (AGPL)。这个协议对商用产品主要的约束是对与使用Berkeley DB的软件,发布软件包时需要付费;举个例子:如果微软的office要使用则必须付费;而腾讯的QQ后台服务器使用则无需付费;
Berkeley DB设计思想
简单、小巧、可靠、高性能。
DB库和应用运行在同一进程空间,接口为API形式,应用通过API存取DB;
应用范例
MySQL 5.1版之前的数据事务存储引擎使用的是Berkeley DB;(5.1版之后不再使用更多的可能是出于商业的原因,因为Berkeley DB被Oracle收购了)
Google Accounts选用的Berkeley DB作为存储引擎;
Berkeley DB VS Redis
除了速度,Berkeley DB的最大的优势是支持多索引(次级索引);支持多索引,使得从关系型DB中移植到内存DB更容易,可有效避免数据膨胀及自行处理索引之间的映射关系;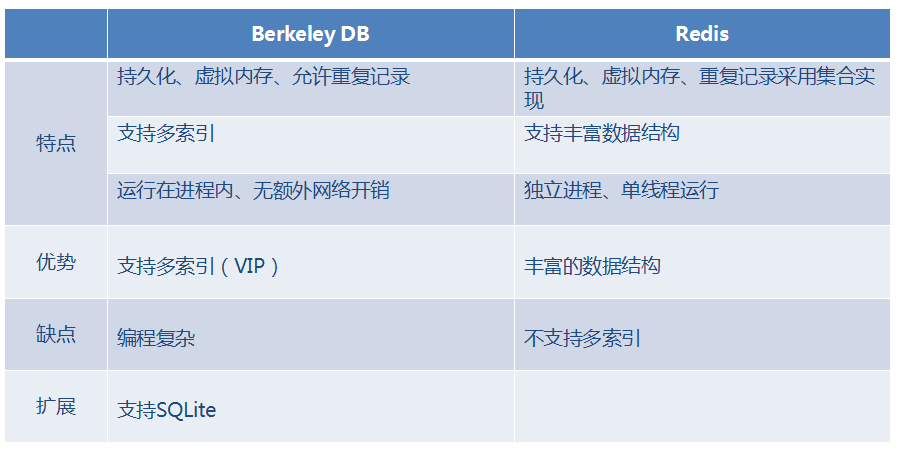
eg:一张学生信息表,以学号为主键(唯一性索引)建立了索引可以查询到指定的学生记录;如果再希望以姓名来查询,可以以姓名为键建立次级索引来查询;
在查询条件比较复杂的情况下,可组合建立多个次级索引来找到同一份数据;
想进一步了解次级索引如何使用,可参考这篇文章:《Berkeley DB多索引查询》
性能测试对比:Berkeley DB VS Redis
使用环境:
CPU:Intel Core 2 Duo P9xxx 2.0G
MEM:16G
OS:Red Hat Enterprise Linux Server release 6.3 (Santiago) x86_64同样是内存数据库,我们对比Berkeley DB和Redis的运行时间(单位:ms)
A表记录:506622条记录:每条记录:96个字节
B表记录:2478条记录;每条记录:10个字节;
C表记录:107221条记录;每条记录:82个字节;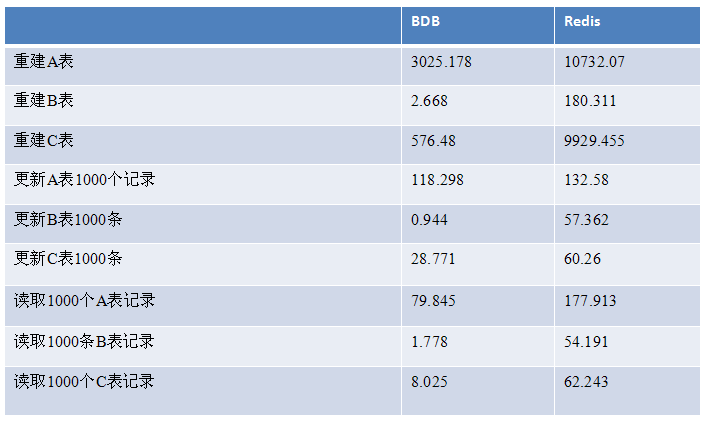
重建内存数据库 BDB用4s,Redis 20s;
更新内存数据库,BDB和Redis的实验结果都比较理想
查询记录时,BDB比Redis基本快一个数量级;
缓存、重建整个表操作,BDB性能明显优于Redis;这是因为BDB提供批量读取所有数据的接口,而Redis没有提供类似的接口;
性能对比测试:Berkeley DB VS Oracle
为了将数据从Oracle中移植出来,我们需要对比关系型数据库和Berkeley DB的查询效率:
首先,我们使用唯一性索引作为Berkeley DB的主键,并因此查询来和oracle对比;
数据规模:
实验数据;1112516条记录:
大小2.8G;以查询出最终结果为准:
SQL查询:
SELECT * FROM table_a
WHERE (DATE=to_date(:v, 'YYYYMMDD') AND A =:a AND B =:b AND c>=:c AND D>=:d) AND ( E=:e) AND (F=:F) AND (G=:g) AND H!='C' AND N='N'";
其中>= 、 !=操作无法编入索引,在索引查处数据后需应用再进行筛选过滤;
最终的查询结果为一条记录;
如果这篇文章让你对Berkeley DB产生了兴趣,如果你也想着效率那点事,想着将关系数据库转到nosql,试着上手吧。传送门:《Berkeley DB入门篇》。
Posted by: 大CC | 31OCT,2013
博客:blog.me115.com
微博:新浪微博
比Redis更快:Berkeley DB面面观的更多相关文章
- mysql DB server端,如何让读写更快
其实,我不是专业的DB管理同学,甚至算不上会了解.只是在最近的工作中,遇到了DB server端优化的契机,所以把这些手段记录下来: 通过调整这个参数的值,可以让DB更给力: 这两个参数的含义: 1. ...
- Berkeley DB的数据存储结构——哈希表(Hash Table)、B树(BTree)、队列(Queue)、记录号(Recno)
Berkeley DB的数据存储结构 BDB支持四种数据存储结构及相应算法,官方称为访问方法(Access Method),分别是哈希表(Hash Table).B树(BTree).队列(Queue) ...
- Oracle Berkeley DB Java 版
Oracle Berkeley DB Java 版是一个开源的.可嵌入的事务存储引擎,是完全用 Java 编写的.它充分利用 Java 环境来简化开发和部署.Oracle Berkeley DB Ja ...
- 免费数据库(SQLite、Berkeley DB、PostgreSQL、MySQL、Firebird、mSQL、MSDE、DB2 Express-C、Oracle XE)
SQLite数据库是中小站点CMS的最佳选择 SQLite 是一个类似Access的轻量级数据库系统,但是更小.更快.容量更大,并发更高.为什么说 SQLite 最适合做 CMS (内容管理系统)呢? ...
- 了解 Oracle Berkeley DB 可以为您的应用程序带来 NoSQL 优势的原因及方式。
将 Oracle Berkeley DB 用作 NoSQL 数据存储 作者:Shashank Tiwari 2011 年 2 月发布 “NoSQL”是在开发人员.架构师甚至技术经理中新流行的一个词汇. ...
- 新型序列化类库MessagePack,比JSON更快、更小的格式
MessagePack is an efficient binary serialization format. It lets you exchange data among multiple la ...
- Berkeley DB分布式探索
明天回家就没有网络,今晚就将整个编写过程记录下来.顺带整理思路以解决未能解决的问题. 标题有点托大,想将Berkeley DB做成分布式存储,感觉很高端的样子,实际上就是通过ssh将Berkeley ...
- Berkeley DB
最近用BDB写点东西,写了挺多个测试工程.列下表,也理清楚最近的思路 1.测试BDB程序,包括打开增加记录,查询记录,获取所有记录.将数据转存mysql 程序的不足,增加记录仅仅只有key和value ...
- 让你的 Node.js 应用跑得更快的 10 个技巧(转)
Node.js 受益于它的事件驱动和异步的特征,已经很快了.但是,在现代网络中只是快是不行的.如果你打算用 Node.js 开发你的下一个Web 应用的话,那么你就应该无所不用其极,让你的应用更快,异 ...
随机推荐
- SoupUI的使用
- umask:遮罩码
查看umask:umask 创建文件:-umask 文件默认不能具有执行权限 创建目录:-umask 设置umask:umask 0022 生效访范围:当前shell
- Mysql备份与还原实例
一.备份数据库 ----清空一下日志 mysql> reset master; Query OK, rows affected (0.02 sec) ----查看一下echo表的存储引擎 mys ...
- 输入框焦点时自动清除value
<!DOCTYPE html><html> <head> <meta charset="utf-8"> <script typ ...
- html+css复习之第2篇 | javascript
1. java 中定义数组和对象: 数组(Array)字面量 定义一个数组: [40, 100, 1, 5, 25, 10] 对象(Object)字面量 定义一个对象: {firstName:&quo ...
- 层叠样式表(CSS)
层叠样式表(CSS) CSS(Cascading Style Sheet)中文译为层叠样式表.是用于控制网页样式并允许将样式信息与网页内容分离的一种标记性语言.CSS的引入就是为了使得HTML语言能够 ...
- android基础小结
(注:此小结文档在全屏模式下观看效果最佳) 2016年3月1日,正式开始了我的android学习之路. 最最开始的,当然是学习怎样搭载环境了,然而苦逼的我在win10各种坑爹的指引下还是安装了一个星期 ...
- 使用VisualSVN建立SVN Server
首先去官网下载安装包.http://subversion.apache.org/packages.html找到windows的,选择VisualSVN->VISUALSVN SERVER 双击开 ...
- C#中容易被忽视的细节整理
(有空更新系列) 1.params可变长度参数,默认值是长度为0的数组,而不是空 2.事件和委托默认值都是null 3.bool返回值的事件调用之后,其内部的合并方式是取最后一个合并对象的返回值
- 《python核心编程》读书笔记--第16章 网络编程
在进行网络编程之前,先对网络以及互联网协议做一个了解. 推荐阮一峰的博客:(感谢) http://www.ruanyifeng.com/blog/2012/05/internet_protocol_s ...