C# 关于utf-8的研究
前提
如果一不小心把字符转成utf8的格式,但是却产生了乱码。这个时候要么就是寻找其他的转码方式,要么就不想要了,直接过滤吧。
这里说的是直接过滤的办法。
参考链接
https://netvignettes.wordpress.com/2011/07/03/how-to-detect-encoding/
大概的代码解释
其实主要的思路就是对照这个表(不过貌似它也不是严格对照的),比如下面的代码就是对于bytes的数量
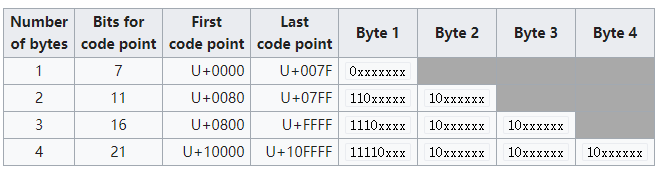
private static bool IsLead4(byte b)
{
return b >= 0xF0 && b < 0xF8;
}
private static bool IsLead3(byte b)
{
return b >= 0xE0 && b < 0xF0;
}
private static bool IsLead2(byte b)
{
return b >= 0xC0 && b < 0xE0;
}
private static bool IsExtendedByte(byte b)
{
return b > 0x80 && b < 0xC0;
}
接下来就是主要一下特殊字符的边界情况
if (length >= )
{
var one = bytes[offset];
var two = bytes[offset + ];
var three = bytes[offset + ];
var four = bytes[offset + ];
if (one == 0x2B &&
two == 0x2F &&
three == 0x76 &&
(four == 0x38 || four == 0x39 || four == 0x2B || four == 0x2F))
{
return UTF7;
}
else if (one == 0xFE && two == 0xFF && three == 0x00 && four == 0x00)
{
return UTF32;
}
else if (four == 0xFE && three == 0xFF && two == 0x00 && one == 0x00)
{
throw new NotSupportedException("The byte order mark specifies UTF-32 in big endian order, which is not supported by .NET.");
}
}
else if (length >= )
{
var one = bytes[offset];
var two = bytes[offset + ];
var three = bytes[offset + ];
if (one == 0xFF && two == 0xFE)
{
return Unicode;
}
else if (one == 0xFE && two == 0xFF)
{
return BigEndianUnicode;
}
else if (one == 0xEF && two == 0xBB && three == 0xBF)
{
return UTF8;
}
}
if (length > )
{
// Look for a leading < sign:
if (bytes[offset] == 0x3C)
{
if (bytes[offset + ] == 0x00)
{
return Unicode;
}
else
{
return UTF8;
} }
else if (bytes[offset] == 0x00 && bytes[offset + ] == 0x3C)
{
return BigEndianUnicode;
}
}
if (IsUtf8(bytes))
{
return UTF8;
}
接下来就是测试
static void Main(string[] args)
{
string ch = "金";
string Ja = "らなくちゃ"; string Re = "фыввфывфывфв"; //byte[] Rom = {209,132,209,34,90,121,5,34,208};
//byte[] Rom = { 100,200,3,4,5,6,7,8,9,0,0 };
byte[] Rom = { , , ,,,,,,,,,,,,,};
//byte[] Rom = {}
byte[] byteArrayUTF8 = UTF8.GetBytes(Ja);
//byte[] byteArrayDefault = Encoding.Default.GetBytes(Re); string Name = Encoding.UTF8.GetString(Rom,,(int)Rom.Length); var y = GetTextEncoding(Rom);
}
全部代码
using System;
using System.Text;
using static System.Text.Encoding; namespace ConsoleApp1
{
class Program
{
/// <summary>
/// Determines whether the bytes in this buffer at the specified offset represent a UTF-8 multi-byte character.
/// </summary>
/// <remarks>
/// It is not guaranteed that these bytes represent a sensical character - only that the binary pattern matches UTF-8 encoding.
/// </remarks>
/// <param name="bytes">This buffer.</param>
/// <param name="offset">The position in the buffer to check.</param>
/// <param name="length">The number of bytes to check, of 4 if not specified.</param>
/// <returns>The rank of the UTF</returns>
public static MultibyteRank GetUtf8MultibyteRank(byte[] bytes, int offset = , int length = )
{
if (bytes == null)
{
throw new ArgumentNullException("bytes");
}
if (offset < || offset > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "Offset is out of range.");
}
else if (length < || length > )
{
throw new ArgumentOutOfRangeException("length", "Only values 1-4 are valid.");
}
else if ((offset + length) > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer.");
}
// Possible 4 byte sequence
if (length > && IsLead4(bytes[offset]))
{
if (IsExtendedByte(bytes[offset + ]) && IsExtendedByte(bytes[offset + ]) && IsExtendedByte(bytes[offset + ]))
{
return MultibyteRank.Four;
}
}
// Possible 3 byte sequence
else if (length > && IsLead3(bytes[offset]))
{
if (IsExtendedByte(bytes[offset + ]) && IsExtendedByte(bytes[offset + ]))
{
return MultibyteRank.Three;
}
}
// Possible 2 byte sequence
else if (length > && IsLead2(bytes[offset]) && IsExtendedByte(bytes[offset + ]))
{
return MultibyteRank.Two;
}
if (bytes[offset] < 0x80)
{
return MultibyteRank.One;
}
else
{
return MultibyteRank.None;
}
}
private static bool IsLead4(byte b)
{
return b >= 0xF0 && b < 0xF8;
}
private static bool IsLead3(byte b)
{
return b >= 0xE0 && b < 0xF0;
}
private static bool IsLead2(byte b)
{
return b >= 0xC0 && b < 0xE0;
}
private static bool IsExtendedByte(byte b)
{
return b > 0x80 && b < 0xC0;
}
public enum MultibyteRank
{
None = ,
One = ,
Two = ,
Three = ,
Four =
} public static bool IsUtf8(byte[] bytes, int offset = , int? length = null)
{
if (bytes == null)
{
throw new ArgumentNullException("bytes");
}
length = length ?? (bytes.Length - offset);
if (offset < || offset > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "Offset is out of range.");
}
else if (length < )
{
throw new ArgumentOutOfRangeException("length");
}
else if ((offset + length) > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer.");
}
var bytesRemaining = length.Value;
while (bytesRemaining > )
{
var rank = GetUtf8MultibyteRank(bytes, offset, Math.Min(, bytesRemaining));
if (rank == MultibyteRank.None)
{
return false;
}
else
{
var charsRead = (int)rank;
offset += charsRead;
bytesRemaining -= charsRead;
}
}
return true;
} /// <summary>
/// Uses various discovery techniques to guess the encoding used for a byte buffer presumably containing text characters.
/// </summary>
/// <remarks>
/// Note that this is only a guess and could be incorrect. Be prepared to catch exceptions while using the <see cref="Encoding.Decoder"/> returned by
/// the encoding returned by this method.
/// </remarks>
/// <param name="bytes">The buffer containing the bytes to examine.</param>
/// <param name="offset">The offset into the buffer to begin examination, or 0 if not specified.</param>
/// <param name="length">The number of bytes to examine.</param>
/// <returns>An encoding, or <see langword="null"> if one cannot be determined.</returns>
public static Encoding GetTextEncoding(byte[] bytes, int offset = , int? length = null)
{
if (bytes == null)
{
throw new ArgumentNullException("bytes");
}
length = length ?? bytes.Length;
if (offset < || offset > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "Offset is out of range.");
}
if (length < || length > bytes.Length)
{
throw new ArgumentOutOfRangeException("length", "Length is out of range.");
}
else if ((offset + length) > bytes.Length)
{
throw new ArgumentOutOfRangeException("offset", "The specified range is outside of the specified buffer.");
}
// Look for a byte order mark:
if (length >= )
{
var one = bytes[offset];
var two = bytes[offset + ];
var three = bytes[offset + ];
var four = bytes[offset + ];
if (one == 0x2B &&
two == 0x2F &&
three == 0x76 &&
(four == 0x38 || four == 0x39 || four == 0x2B || four == 0x2F))
{
return UTF7;
}
else if (one == 0xFE && two == 0xFF && three == 0x00 && four == 0x00)
{
return UTF32;
}
else if (four == 0xFE && three == 0xFF && two == 0x00 && one == 0x00)
{
throw new NotSupportedException("The byte order mark specifies UTF-32 in big endian order, which is not supported by .NET.");
}
}
else if (length >= )
{
var one = bytes[offset];
var two = bytes[offset + ];
var three = bytes[offset + ];
if (one == 0xFF && two == 0xFE)
{
return Unicode;
}
else if (one == 0xFE && two == 0xFF)
{
return BigEndianUnicode;
}
else if (one == 0xEF && two == 0xBB && three == 0xBF)
{
return UTF8;
}
}
if (length > )
{
// Look for a leading < sign:
if (bytes[offset] == 0x3C)
{
if (bytes[offset + ] == 0x00)
{
return Unicode;
}
else
{
return UTF8;
} }
else if (bytes[offset] == 0x00 && bytes[offset + ] == 0x3C)
{
return BigEndianUnicode;
}
}
if (IsUtf8(bytes))
{
return UTF8;
}
else
{
// Impossible to tell.
return null;
}
}
static void Main(string[] args)
{
string ch = "金";
string Ja = "らなくちゃ"; string Re = "фыввфывфывфв"; //byte[] Rom = {209,132,209,34,90,121,5,34,208};
//byte[] Rom = { 100,200,3,4,5,6,7,8,9,0,0 };
byte[] Rom = { , , ,,,,,,,,,,,,,};
//byte[] Rom = {}
byte[] byteArrayUTF8 = UTF8.GetBytes(Ja);
//byte[] byteArrayDefault = Encoding.Default.GetBytes(Re); string Name = Encoding.UTF8.GetString(Rom,,(int)Rom.Length); var y = GetTextEncoding(Rom);
}
}
}
C# 关于utf-8的研究的更多相关文章
- java io 源码研究记录(一)
Java IO 源码研究: 一.输入流 1 基类 InputStream 简介: 这是Java中所有输入流的基类,它是一个抽象类,下面我们简单来了解一下它的基本方法和抽象方法. 基本方法: publ ...
- 闲来无聊,研究一下Web服务器 的源程序
web服务器是如何工作的 1989年的夏天,蒂姆.博纳斯-李开发了世界上第一个web服务器和web客户机.这个浏览器程序是一个简单的电话号码查询软件.最初的web服务器程序就是一个利用浏览器和web服 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- 深入研究Visual studio 2017 RC新特性
在[Xamarin+Prism开发详解三:Visual studio 2017 RC初体验]中分享了Visual studio 2017RC的大致情况,同时也发现大家对新的Visual Studio很 ...
- 【初码干货】使用阿里云对Web开发中的资源文件进行CDN加速的深入研究和实践
提示:阅读本文需提前了解的相关知识 1.阿里云(https://www.aliyun.com) 2.阿里云CDN(https://www.aliyun.com/product/cdn) 3.阿里云OS ...
- 对一致性Hash算法,Java代码实现的深入研究
一致性Hash算法 关于一致性Hash算法,在我之前的博文中已经有多次提到了,MemCache超详细解读一文中"一致性Hash算法"部分,对于为什么要使用一致性Hash算法.一致性 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- 开源Word读写组件DocX 的深入研究和问题总结
一. 前言 前两天看到了asxinyu大神的[原创]开源Word读写组件DocX介绍与入门,正好我也有类似的自动生成word文档得需求,于是便仔细的研究了这个DocX. 我也把它融入到我的项目当中并进 ...
- 【移动端兼容问题研究】javascript事件机制详解(涉及移动兼容)
前言 这篇博客有点长,如果你是高手请您读一读,能对其中的一些误点提出来,以免我误人子弟,并且帮助我提高 如果你是javascript菜鸟,建议您好好读一读,真的理解下来会有不一样的收获 在下才疏学浅, ...
- 从Java String实例来理解ANSI、Unicode、BMP、UTF等编码概念
转(http://www.codeceo.com/article/java-string-ansi-unicode-bmp-utf.html#0-tsina-1-10971-397232819ff9a ...
随机推荐
- SpringBoot23 分模块开发
1 开发环境说明 JDK:1.8 MAVEN:3.5 IDEA:2017.2.5 SpringBoot:2.0.3.RELEASE 2 创建SpringBoot项目 2.1 项目信息 2.2 添加项目 ...
- 498B Name That Tune
传送门 题目大意 n首音乐,第i首被听出来的概率为pi,刚开始听第一首,1s后如果听出来了则放第下一首,否则接着听这一首,第i首在连续听了ti s之后一定会被听出来,问Ts后听出来的歌的期望数量. 分 ...
- hdu 4768 Flyer (异或操作的应用)
2013年长春网络赛1010题 继巴斯博弈(30分钟)签到后,有一道必过题(一眼即有思路). 思路老早就有(40分钟):倒是直到3小时后才被A掉.期间各种换代码姿态! 共享思路: unlucky st ...
- sql server行列转化
行列转换: 姓名 课程 分数 张三 语文 74 张三 数学 83 张三 物理 93 李四 语文 74 李四 数学 84 李四 物理 94 想变成(得到如下结果): 姓名 语文 数学 物理 ---- - ...
- 在IE中检查控件是否安装成功
步骤: 1.打开图片上传页面 2.打开IE加载项 3.在加载项中可以看到加载的控件 4.点击详细信息,查看文件名称和文件位置
- 【Head First Java 读书笔记】(一)基本概念
Java的工作方式 你要做的事情就是会编写源代码 Java的程序结构 类存于源文件里面 方法存在类中 语句存于方法中 剖析类 当Java虚拟机启动执行时,它会寻找你在命令列中所指定的类,然后它会锁定像 ...
- 再次迷宫救人——BFS
原创 上次用DFS解了迷宫救人:https://www.cnblogs.com/chiweiming/p/9313164.html 这次用BFS(广度优先搜索),实现广度优先搜索比深度优先搜索复杂,思 ...
- HackTwelve 为背景添加圆角边框
1.概要: ShapeDrawable是一个为UI控件添加特效的好工具.这个技巧适用于那些可以添加背景的控件 2.添加圆角边框其实就是添加的背景那里不是直接添加图片,而是添加一个XML文件即可 ...
- Android getDimension,getDimensionPixelOffset,getDimensionPixelSize
1.例如在onMeasure(int , int)方法中可能要获取自定义属性的值.如: TypedArray a = context.obtainStyledAttributes(attrs, R.s ...
- SQLServer 附加数据库后只读或报错解决方法
百度文库地址 http://wenku.baidu.com/link?url=3EnK52mOtll3svjce0OGUUu7h9EOWkUgty8VChkxRdX7LQlm9Ll6N_78ENngN ...