HDFS主要节点解说(一)节点功能
1 HDFS体系结构简单介绍及优缺点
1.1体系结构简单介绍
HDFS是一个主/从(Mater/Slave)体系结构。从终于用户的角度来看,它就像传统的文件系统一样,能够通过文件夹路径对文件运行CRUD(Create、Read、Update和Delete)操作。但因为分布式存储的性质,HDFS集群拥有一个NameNode和一些DataNode。NameNode管理文件系统的元数据,DataNode存储实际的数据。
client通过同NameNode和DataNodes的交互訪问文件系统。
client联系NameNode以获取文件的元数据,而真正的文件I/O操作是直接和DataNode进行交互的。
下图为HDFS整体结构示意图
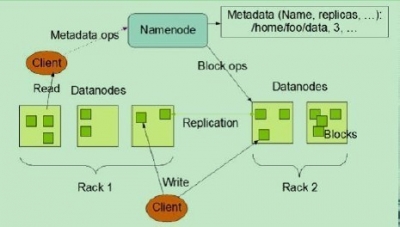
1.1.1 NameNode
NameNode能够看作是分布式文件系统中的管理者。主要负责管理文件系统的命名空间、集群配置信息和存储块的复制等。NameNode会将文件系统的Meta-data存储在内存中,这些信息主要包含了文件信息、每个文件相应的文件块的信息和每个文件块在DataNode的信息等。
l
Masterl 管理HDFS的名称空间l 管理数据块映射信息l 配置副本策略l 处理client读写请求
1.1.2 Secondary namenode
并不是NameNode的热备; 辅助NameNode,分担其工作量; 定期合并fsimage和fsedits,推送给NameNode; 在紧急情况下。可辅助恢复NameNode。
1.1.3 DataNode
DataNode是文件存储的基本单元,它将Block存储在本地文件系统中,保存了Block的Meta-data,同一时候周期性地将全部存在的Block信息发送给NameNode。
Slavel 存储实际的数据块 运行数据块读/写
1.1.4 Client
文件切分 与NameNode交互,获取文件位置信息; 与DataNode交互。读取或者写入数据; 管理HDFS。 訪问HDFS。
1.1.5 文件写入
1) Client向NameNode发起文件写入的请求。 2) NameNode依据文件大小和文件块配置情况。返回给Client它所管理部分DataNode的信息。 3) Client将文件划分为多个Block,依据DataNode的地址信息,按顺序写入到每个DataNode块中。
1.1.6 文件读取
1) Client向NameNode发起文件读取的请求。 2) NameNode返回文件存储的DataNode的信息。
3) Client读取文件信息。
HDFS典型的部署是在一个专门的机器上执行NameNode,集群中的其它机器各执行一个DataNode;也能够在执行NameNode的机器上同一时候执行DataNode,或者一台机器上执行多个DataNode。一个集群仅仅有一个NameNode的设计大大简化了系统架构。
1.2长处
1.2.1 处理超大文件
这里的超大文件一般是指百MB、设置数百TB大小的文件。眼下在实际应用中,HDFS已经能用来存储管理PB级的数据了。
1.2.2 流式的訪问数据
HDFS的设计建立在很多其它地响应"一次写入、多次读写"任务的基础上。
这意味着一个数据集一旦由数据源生成。就会被复制分发到不同的存储节点中,然后响应各种各样的数据分析任务请求。
在多数情况下,分析任务都会涉及数据集中的大部分数据,也就是说,对HDFS来说。请求读取整个数据集要比读取一条记录更加高效。
1.2.3 执行于便宜的商用机器集群上
hadoop设计对硬件需求比較低。仅仅须执行在低廉的商用硬件集群上,而无需昂贵的高可用性机器上。便宜的商用机也就意味着大型集群中出现节点故障情况的概率很高。这就要求设计HDFS时要充分考虑数据的可靠性,安全性及高可用性。
1.3 缺点
1.3.1 不适合低延迟数据訪问
假设要处理一些用户要求时间比較短的低延迟应用请求。则HDFS不适合。HDFS是为了处理大型数据集分析任务的,主要是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
改进策略:
对于那些有低延时要求的应用程序,HBase是一个更好的选择。
通过上层数据管理项目来尽可能地弥补这个不足。在性能上有了非常大的提升,它的口号就是goes real time。
使用缓存或多master设计能够降低client的数据请求压力,以降低延时。还有就是对HDFS系统内部的改动,这就得权衡大吞吐量与低延时了,HDFS不是万能的银弹。
1.3.2 无法高效存储大量小文件
由于Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每个文件、目录和Block须要占领150字节左右的空间。所以。假设你有100万个文件,每个占领一个Block,你就至少须要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时。对于当前的硬件水平来说就没法实现了。另一个问题就是,由于Map
task的数量是由splits来决定的。所以用MR处理大量的小文件时。就会产生过多的Maptask。线程管理开销将会添加作业时间。
举个样例。处理10000M的文件,若每一个split为1M。那就会有10000个Maptasks,会有非常大的线程开销;若每一个split为100M。则仅仅有100个Maptasks。每一个Maptask将会有很多其它的事情做,而线程的管理开销也将减小非常多。
改进策略:
要想让HDFS能处理好小文件。有不少方法。
利用SequenceFile、MapFile、Har等方式归档小文件,这种方法的原理就是把小文件归档起来管理,HBase就是基于此的。
对于这样的方法,假设想找回原来的小文件内容,那就必须得知道与归档文件的映射关系。横向扩展,一个Hadoop集群能管理的小文件有限,那就把几个Hadoop集群拖在一个虚拟server后面。形成一个大的Hadoop集群。google也是这么干过的。多Master设计,这个作用显而易见了。正在研发中的GFS
II也要改为分布式多Master设计,还支持Master的Failover。并且Block大小改为1M。有意要调优处理小文件啊。
附带个Alibaba DFS的设计,也是多Master设计。它把Metadata的映射存储和管理分开了,由多个Metadata存储节点和一个查询Master节点组成。
1.3.3 不支持多用户写入及随意改动文件
在HDFS的一个文件里仅仅有一个写入者,并且写操作仅仅能在文件末尾完毕。即仅仅能运行追加操作。
眼下HDFS还不支持多个用户对同一文件的写操作,以及在文件任何位置进行改动。
HDFS主要节点解说(一)节点功能的更多相关文章
- hdfs 名称节点和数据节点
名字节点(NameNode )是HDFS主从结构中主节点上运行的主要进程,它指导主从结构中的从节点,数据节点(DataNode)执行底层的I/O任务. 名字节点是HDFS的书记员,维护着整个文件系统的 ...
- 初探JavaScript(一)——也谈元素节点、属性节点、文本节点
Javascript大行其道的时候,怎么能少了我来凑凑热闹^_^ 基本上自己对于js的知识储备很少,先前有用过JQuery实现一些简单功能,要论起JS的前世今生,来龙去脉,我就一小白.抱起一本< ...
- hadoop-2.6.0.tar.gz + spark-1.5.2-bin-hadoop2.6.tgz 的集群搭建(3节点和5节点皆适用)
本人呕心沥血所写,经过好一段时间反复锤炼和整理修改.感谢所参考的博友们!同时,欢迎前来查阅赏脸的博友们收藏和转载,附上本人的链接.http://www.cnblogs.com/zlslch/p/584 ...
- Postgres中的物化节点之sort节点
顾名思义,物化节点是一类可缓存元组的节点.在执行过程中,很多扩展的物理操作符需要首先获取所有的元组后才能进行操作(例如聚集函数操作.没有索引辅助的排序等),这时要用物化节点将元组缓存起来.下面列出了P ...
- treeview插件使用:根据子节点选中父节点
鄙人公司没有专门的前端,所以项目开发中都是前后端一起抡.最近用bootstrap用的比较频繁,发现bootstrap除了框架本身的样式组件外,还提供了多种插件供开发者选择.本篇博文讲的就是bootst ...
- Web网页树形列表中实现选中父节点则子节点全选和不选中父则子全不选
需要实现的功能:选中父节点对应子节点全选:不选中父节点,对应子节点也不选中 如下图所示,选中车队,对应车队中车辆也全部选中,以实现车队中所有车辆在地图上的显示. 选中cqupt ...
- Hadoop记录-Hadoop集群添加节点和删除节点
1.添加节点 A:新节点中添加账户,设置无密码登陆 B:Name节点中设置到新节点的无密码登陆 C:在Name节点slaves文件中添加新节点 D:在所有节点/etc/hosts文件中增加新节点(所有 ...
- ztree 获取当前选中节点的子节点集合
功能:获取当前选中节点的子节点id集合. 步骤:1.获取当前节点 2.用ztree的方法transformToArray()获取当前选中节点(含选中节点)的子节点对象集合. 3.遍历集合,取出需要的值 ...
- C# 读写opc ua服务器,浏览所有节点,读写节点,读历史数据,调用方法,订阅,批量订阅操作
OPC UA简介 OPC是应用于工业通信的,在windows环境的下一种通讯技术,原有的通信技术难以满足日益复杂的环境,在可扩展性,安全性,跨平台性方面的不足日益明显,所以OPC基金会在几年前提出了面 ...
随机推荐
- selenium 操作cookie (cookie测试)
前言 在实际的web应用中,可能会涉及到cookie测试,验证浏览器中的cookie是否正确..Cookies 验证:如果系统使用了cookie,测试人员需要对它们进行检测.如果在 cookies 中 ...
- 使用Pygame制作微信打飞机游戏PC版
前一阵子看了一篇文章:青少年如何使用Python开始游戏开发 .看完照葫芦画瓢写了一个,觉得挺好玩儿,相当于简单学了下Pygame库.这篇文章是个12岁小孩儿写的,国外小孩儿真心NB,想我12岁的时候 ...
- [BZOJ1853][Scoi2010]幸运数字 容斥+搜索剪枝
1853: [Scoi2010]幸运数字 Time Limit: 2 Sec Memory Limit: 64 MBSubmit: 3202 Solved: 1198[Submit][Status ...
- mongodb复制集搭建
注:mongodb当前版本是3.4.3 1.准备三个虚拟机做服务器 192.168.168.129:27017 192.168.168.130:27017 192.168.168.131:27017 ...
- SPOJ BGSHOOT - Shoot and kill (线段树 区间修改 区间查询)
BGSHOOT - Shoot and kill no tags The problem is about Mr.BG who is a great hunter. Today he has gon ...
- IDEA的Maven项目找不到class
- 【并查集】bzoj1015 [JSOI2008]星球大战starwar
倒着处理删点,就变成了加点,于是并查集. #include<cstdio> using namespace std; #define N 400001 int fa[N],kill[N], ...
- 【最大流】【费用流】bzoj1834 [ZJOI2010]network 网络扩容
引用题解: 最大流+费用流. 第一问最大流即可. 第二问为“最小费用最大流”. 由题意,这一问的可转化为在上一问的“残量网络”上,扩大一些边的容量,使能从新的图中的最大流为k. 那么易得:对于还有剩余 ...
- Problem K: 数字菱形
#include<stdio.h> int main() { int n,i,j,k,t,x,q,p; while(scanf("%d",&n)!=EOF) ; ...
- MetaWeblog是什么
MetaWebBlog API(MWA)是一个Blog程序接口标准,允许外部程序来获取或者设置Blog的文字和熟悉.他建立在XMLRPC接口之上,并且已经有了很多的实现. 所以现在很多博客系统都支持这 ...