机器学习(二十七)— EM算法
1、EM算法要解决的问题
如果使用基于最大似然估计的模型,模型中存在隐变量,就要用EM算法做参数估计。
EM算法解决这个的思路是使用启发式的迭代方法,既然我们无法直接求出模型分布参数,那么我们可以先猜想隐含数据(EM算法的E步),接着基于观察数据和猜测的隐含数据一起来极大化对数似然,求解我们的模型参数(EM算法的M步)。由于我们之前的隐藏数据是猜测的,所以此时得到的模型参数一般还不是我们想要的结果。不过没关系,我们基于当前得到的模型参数,继续猜测隐含数据(EM算法的E步),然后继续极大化对数似然,求解我们的模型参数(EM算法的M步)。以此类推,不断的迭代下去,直到模型分布参数基本无变化,算法收敛,找到合适的模型参数。
从上面的描述可以看出,EM算法是迭代求解最大值的算法,同时算法在每一次迭代时分为两步,E步和M步。一轮轮迭代更新隐含数据和模型分布参数,直到收敛,即得到我们需要的模型参数。
一个最直观了解EM算法思路的是K-Means算法,见之前写的K-Means聚类算法原理。在K-Means聚类时,每个聚类簇的质心是隐含数据。我们会假设KK个初始化质心,即EM算法的E步;然后计算得到每个样本最近的质心,并把样本聚类到最近的这个质心,即EM算法的M步。重复这个E步和M步,直到质心不再变化为止,这样就完成了K-Means聚类。
当然,K-Means算法是比较简单的,实际中的问题往往没有这么简单。上面对EM算法的描述还很粗糙,我们需要用数学的语言精准描述。
2、算法基本思想
理解算法:https://www.jianshu.com/p/1121509ac1dc
通过优化目标函数的下界,间接优化目标函数。受初值影响大,不能保证全局最优,但保证收敛到稳定点。
如果我们从算法思想的角度来思考EM算法,我们可以发现我们的算法里已知的是观察数据,未知的是隐含数据和模型参数,在E步,我们所做的事情是固定模型参数的值,优化隐含数据的分布,而在M步,我们所做的事情是固定隐含数据分布,优化模型参数的值。比较下其他的机器学习算法,其实很多算法都有类似的思想。
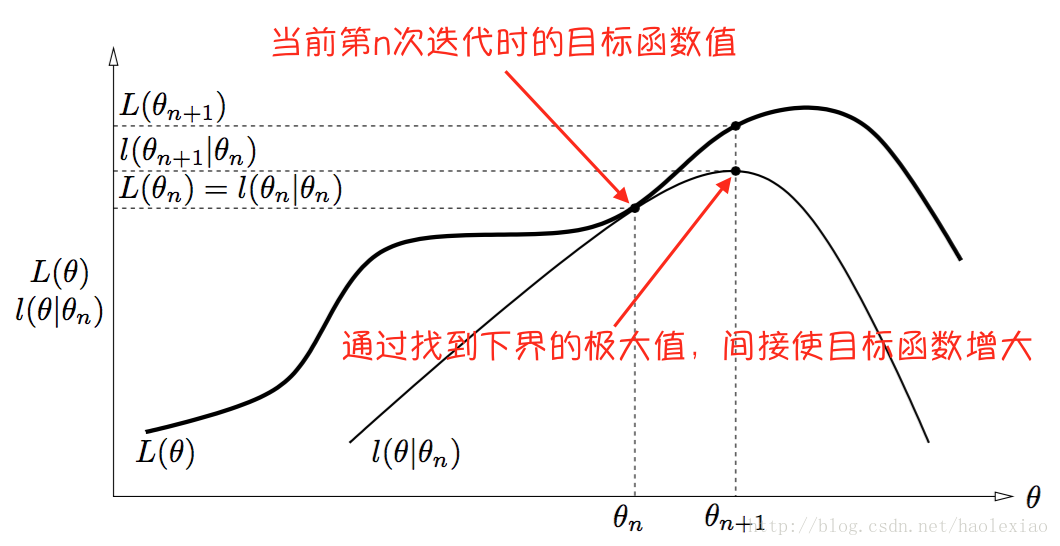
EM算法的优化过程直观理解是如下图的,即当前节点θn是如下的位置 然后找到当前函数的一个下界,且这个下界是可以在θn节点取到的.然后再找出这个下界的最大值,其横坐标就为θn+1所以上面找下界的步骤是E步骤,找下界最大值求出θn+1的步骤是M步骤。
3、算法步骤

机器学习(二十七)— EM算法的更多相关文章
- python机器学习笔记:EM算法
EM算法也称期望最大化(Expectation-Maximum,简称EM)算法,它是一个基础算法,是很多机器学习领域的基础,比如隐式马尔科夫算法(HMM),LDA主题模型的变分推断算法等等.本文对于E ...
- 机器学习中的EM算法具体解释及R语言实例(1)
最大期望算法(EM) K均值算法很easy(可參见之前公布的博文),相信读者都能够轻松地理解它. 但以下将要介绍的EM算法就要困难很多了.它与极大似然预计密切相关. 1 算法原理 最好还是从一个样例開 ...
- python大战机器学习——聚类和EM算法
注:本文中涉及到的公式一律省略(公式不好敲出来),若想了解公式的具体实现,请参考原著. 1.基本概念 (1)聚类的思想: 将数据集划分为若干个不想交的子集(称为一个簇cluster),每个簇潜在地对应 ...
- 【机器学习笔记】EM算法及其应用
极大似然估计 考虑一个高斯分布\(p(\mathbf{x}\mid{\theta})\),其中\(\theta=(\mu,\Sigma)\).样本集\(X=\{x_1,...,x_N\}\)中每个样本 ...
- opencv3中的机器学习算法之:EM算法
不同于其它的机器学习模型,EM算法是一种非监督的学习算法,它的输入数据事先不需要进行标注.相反,该算法从给定的样本集中,能计算出高斯混和参数的最大似然估计.也能得到每个样本对应的标注值,类似于kmea ...
- 简单易学的机器学习算法——EM算法
简单易学的机器学习算法——EM算法 一.机器学习中的参数估计问题 在前面的博文中,如“简单易学的机器学习算法——Logistic回归”中,采用了极大似然函数对其模型中的参数进行估计,简单来讲即对于一系 ...
- EM算法浅析(二)-算法初探
EM算法浅析,我准备写一个系列的文章: EM算法浅析(一)-问题引出 EM算法浅析(二)-算法初探 一.EM算法简介 在EM算法之一--问题引出中我们介绍了硬币的问题,给出了模型的目标函数,提到了这种 ...
- 从最大似然到EM算法浅解
从最大似然到EM算法浅解 zouxy09@qq.com http://blog.csdn.net/zouxy09 机器学习十大算法之中的一个:EM算法.能评得上十大之中的一个,让人听起来认为挺NB的. ...
- EM算法--第一篇
在统计计算中,最大期望(EM)算法是在概率(probabilistic)模型中寻找参数最大似然估计或者最大后验估计的算法,其中概率模型依赖于无法观测的隐藏变量(LatentVariable).最大期望 ...
- 从极大似然函数到EM算法
最近看斯坦福大学的机器学习课程,空下来总结一下参数估计相关的算法知识. 一.极大似然估计: 大学概率论课程都有讲到参数估计的两种基本方法:极大似然估计.矩估计.两种方法都是利用样本信息尽量准确的去描述 ...
随机推荐
- KVM WEB管理工具webvirtmgr安装和使用
生产环境的KVM宿主机越来越多,需要对宿主机的状态进行调控.这里用webvirtmgr进行管理.图形化的WEB,让人能更方便的查看kvm 宿主机的情况和操作 1 安装支持的软件源 yum -y ins ...
- python多进程理论
什么是进程 进程:正在进行的一个过程或者说一个任务.而负责执行任务则是cpu. 举例(单核+多道,实现多个进程的并发执行): 你在一个时间段内有很多任务要做:python学习的任务,赚钱的任务,交女朋 ...
- F110使用的函数
BAPI_ACC_DOCUMENT_POST BAPI_GL*POST 1.F-59 [没有找到函数]BAPI_ACC_DOCUMENT_POST 必须创建有借贷2 line 的凭证,需求要参考原始的 ...
- Webpack,Browserify和Gulp三者之间到底是怎样的关系
转:https://zhidao.baidu.com/question/1799220342210982227.html怎么解释呢?因为 Gulp 和 browserify / webpack 不是一 ...
- 剑指offer 面试55题
面试55题: 题目:二叉树的深度 题:输入一棵二叉树,求该树的深度.从根结点到叶结点依次经过的结点(含根.叶结点)形成树的一条路径,最长路径的长度为树的深度. 解题思路: ①如果一棵树只有一个节点,它 ...
- linux 后台进程管理利器supervisor
Linux的后台进程运行有好几种方法,例如nohup,screen等,但是,如果是一个服务程序,要可靠地在后台运行,我们就需要把它做成daemon,最好还能监控进程状态,在意外结束时能自动重启. ...
- 内置函数(Day16)
现在python一共为我们提供了68个内置函数.它们就是python提供给你直接可以拿来使用的所有函数 内置函数 abs() divmod() input() open() stati ...
- Python 7 多线程及进程
进程与线程: 进程的概念: 1.程序的执行实例称为进程. 2.每个进程都提供执行程序所需的资源.一个进程有一个虚拟地址空间.可执行代码.对系统对象的开放句柄.一个安全上下文.一个独特的进程标识符.环境 ...
- 请求json和xml数据时的方式
当请求xml数据时,直接通过NSMutableData接收后解析, NSURL *url = [NSURL URLWithString:PATH]; _receiveData = [[NSMutabl ...
- 优化MD5和IP在(MySQL)数据库中的存储
1.MD5在MySQL数据库中的存储 用CHAR(32)来存储MD5值是一个常见的技巧.如果你的应用程序使用VARCHAR(32),则对每个值得字符串长度都需要花费额外的不 必要的开销.这个十六进制的 ...