what is feeding and what is 读扩散 and 写扩散?
what is feeding?
通俗点说feed系统就是当你登陆进对应网站后:微信朋友圈的动态、人人网上看到的一件件新鲜事、新浪微博上推到你面前的一条条新围脖等等。系统中的每一条消息就是一个feed。feed的获取方式主要有两种:push(推)以及pull(拉)。也就是接下来所说的读扩散和写扩散。
feed流业务最大的特点是“我们的主页由别人发布的feed组成”,获得朋友圈消息feed流集合,从技术上说,主要有“拉取”与“推送”两种方式。feed流的推与拉主要指的是这里。
feed的特点
有好友关系,例如关注,粉丝
我们的主页由别人发布的feed组成
feed的经典动作
关注,取关
发布feed
拉取自己的主页feed流
feed的核心元数据
关系数据
feed数据
feeding流之读扩散?
例如:某feed系统里有ABCD四个用户,其中:
A关注了BC,D关注了B
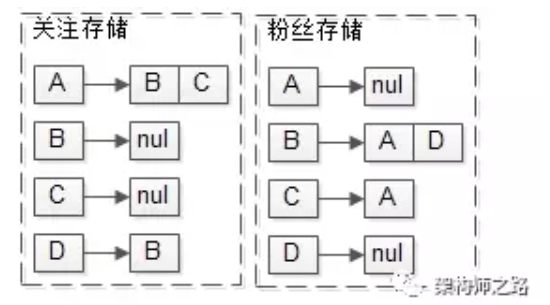
其关系存储又包含关注关系与粉丝关系,“A关注了BC,D关注了B”的潜台词是“B有两个粉丝AD,C有一个粉丝A”。
B发布过四条feed:msg1, msg3, msg5, msg10
C发布过两条feed:msg2, msg8

每一个用户,都有一个feed队列,记录自己曾经发布的所有feed数据。
在拉模式中,发布一条feed的流程非常简单,例如C新发布了一条msg12:
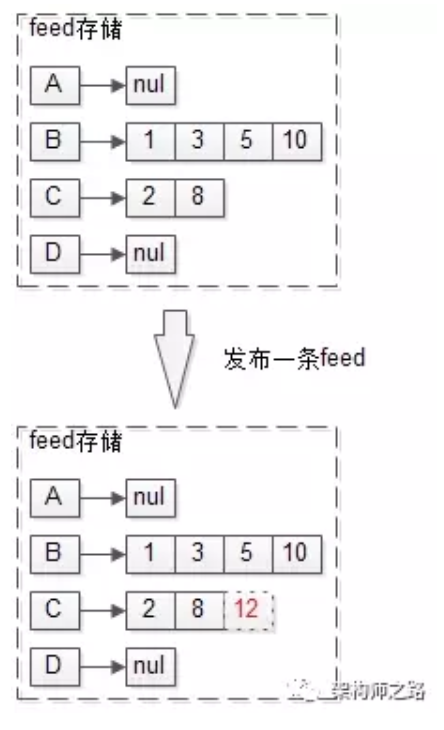
此时只需往C的feed队列里加入一条feed即可。
在拉模式中,取消关注的流程也非常简单,例如A取消关注C:
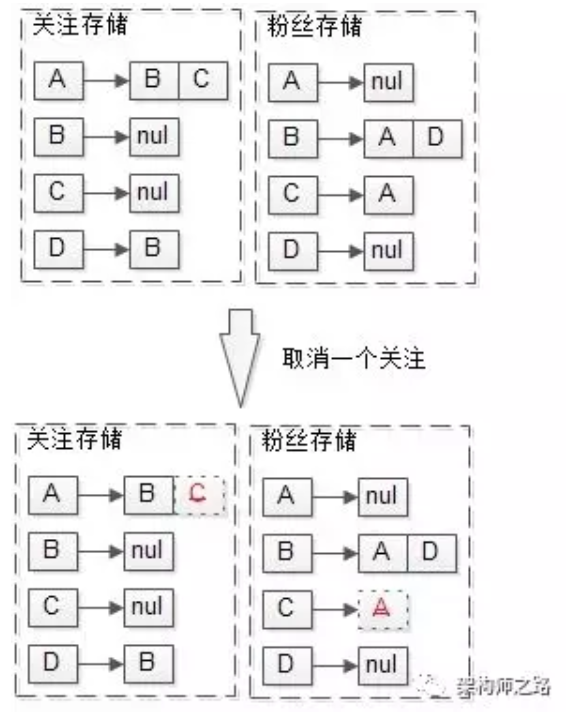
此时只需要在A的关注列表里删除C,并在C的粉丝列表里删除A即可。
在拉模式中,用户A获取“由别人发布的feed组成的主页”的过程比较复杂,此时需要:
获取A的关注列表
list<gz_uid> = select uid from GZ where uid=A
获取所关注的用户发布的feed
list<msg> = NULL;
for(uid in list<gz_uid>){
list<some_msg> =
select * from F where uid=$uid offset | limit
list<msg> += list<some_msg>;
}
对消息进行rank排序(假设按照发布时间排序),分页取出对应的一页feeds
sort_msg_by_time(list<msg>);
get_one_page(list<msg>, page_num);
feed流的拉模式(“读扩散”)有什么优缺点?
优点:
存储结构简单,数据存储量较小,关系数据与feed数据都只存一份
取消关注,发布feed的业务流程非常简单
存储结构,业务流程都比较容易理解,非常适合项目早期用户量、数据量、并发量不大时的快速实现
缺点也显而易见:
拉取朋友圈feed流列表的业务流程非常复杂
有多次数据访问,并且要进行大量的内存计算,大量数据的网络传输,性能较低
在拉模式中,系统的瓶颈容易出现在“用户所发布feed列表”的读取上,而每个用户发布feed的频率其实是很低的,此时,架构优化的核心是通过缓存降低数据存储磁盘IO。
当用户量、数据量、并发量数据逐步增加之后,拉模式会慢慢扛不住了,需要升级优化,但对于“取消关注”与“发布feed”这两个写流程又会有冲击和影响。
feeding流之写扩散?
推模式(写扩散),关系数据的存储与拉模式(读扩散)完全一样。
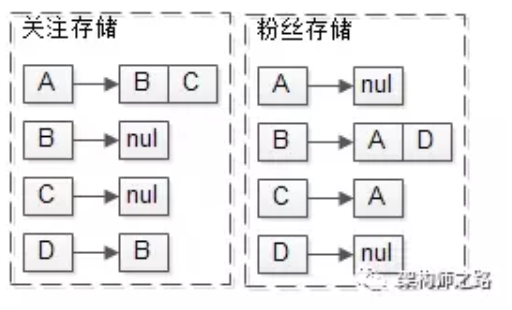
feed数据,每个用户也存储自己发布的feed。
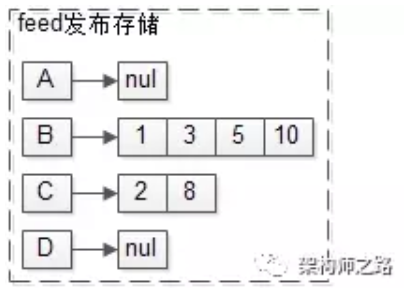
如上图:
B曾经发布过1,3,5,10
C曾经发布过2,8
画外音:不妨设,这里的msgid按照feed的发布时间偏序。
feed数据存储,与拉(读扩散)不同的是,每个用户还需要存储自己收到的feed流。
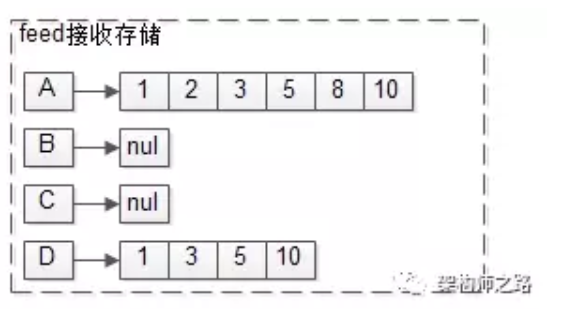
如上图:
A关注了BC,所以A的接收队列是1,2,3,5,8,10
D关注了B,所以D的接受队列是1,3,5,10
在推模式(写扩散)中,获取“由别人发布的feed组成的主页”会变得异常简单,假设一页消息为3条feed,A如果要看自己朋友圈的第二页消息,直接返回1,2,3即可。
画外音:第一页朋友圈是最新的消息,即5,8,10。
在推模式(写扩散)中,发布一条feed的流程会更复杂一点。
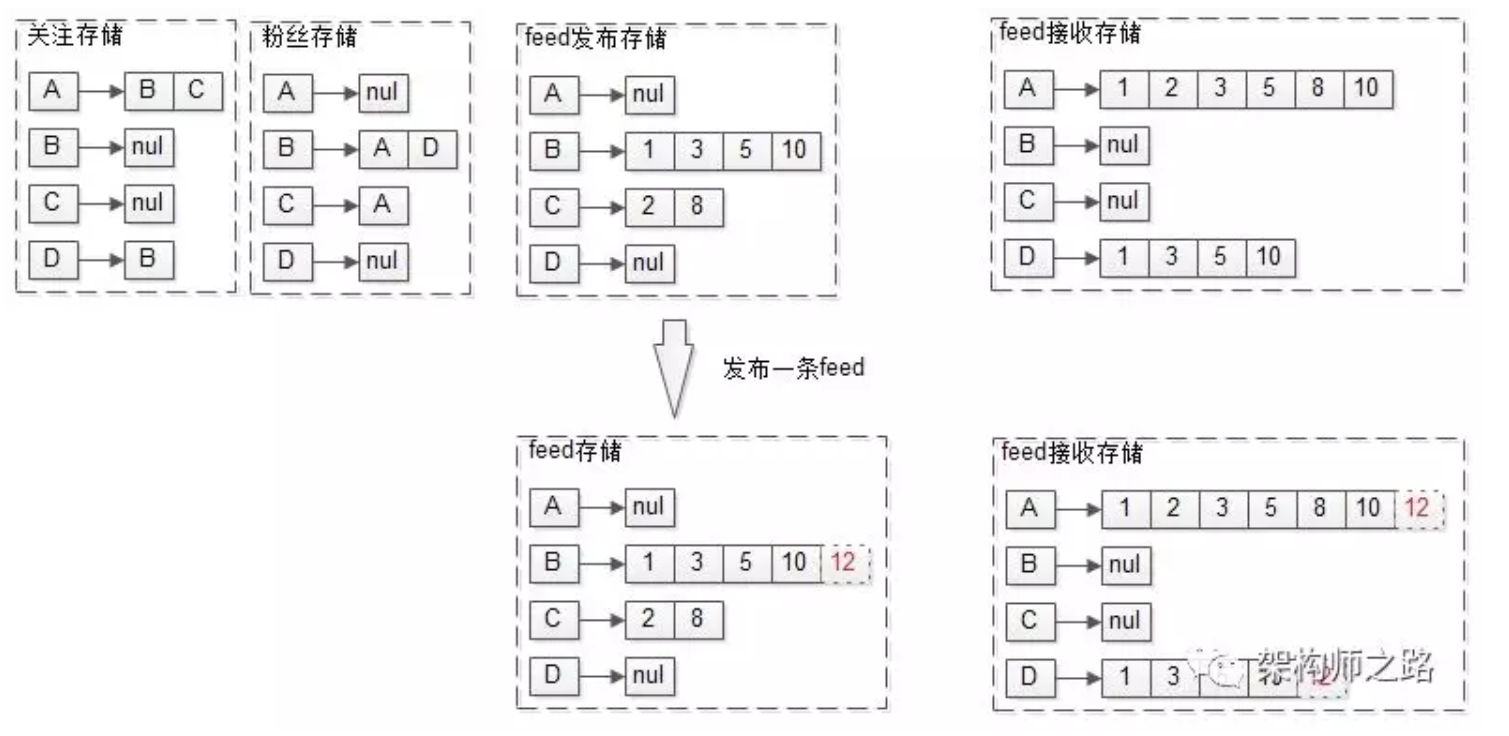
例如B新发布了一条msg12:
在B的发布feed存储里加入消息12
查询B全部粉丝AD
在粉丝AD的接收feed存储里也加入消息12
之所以该方案称为推模式(写扩散),就是因为,用户发布feed的时候:
直接将feed推到了粉丝的接收列表里,故称为“推模式”
不止写发布feed存储,而且要写多个粉丝的接收feed存储,故称为“写扩散”
在推模式(写扩散)中,添加关注的流程也会变得复杂。
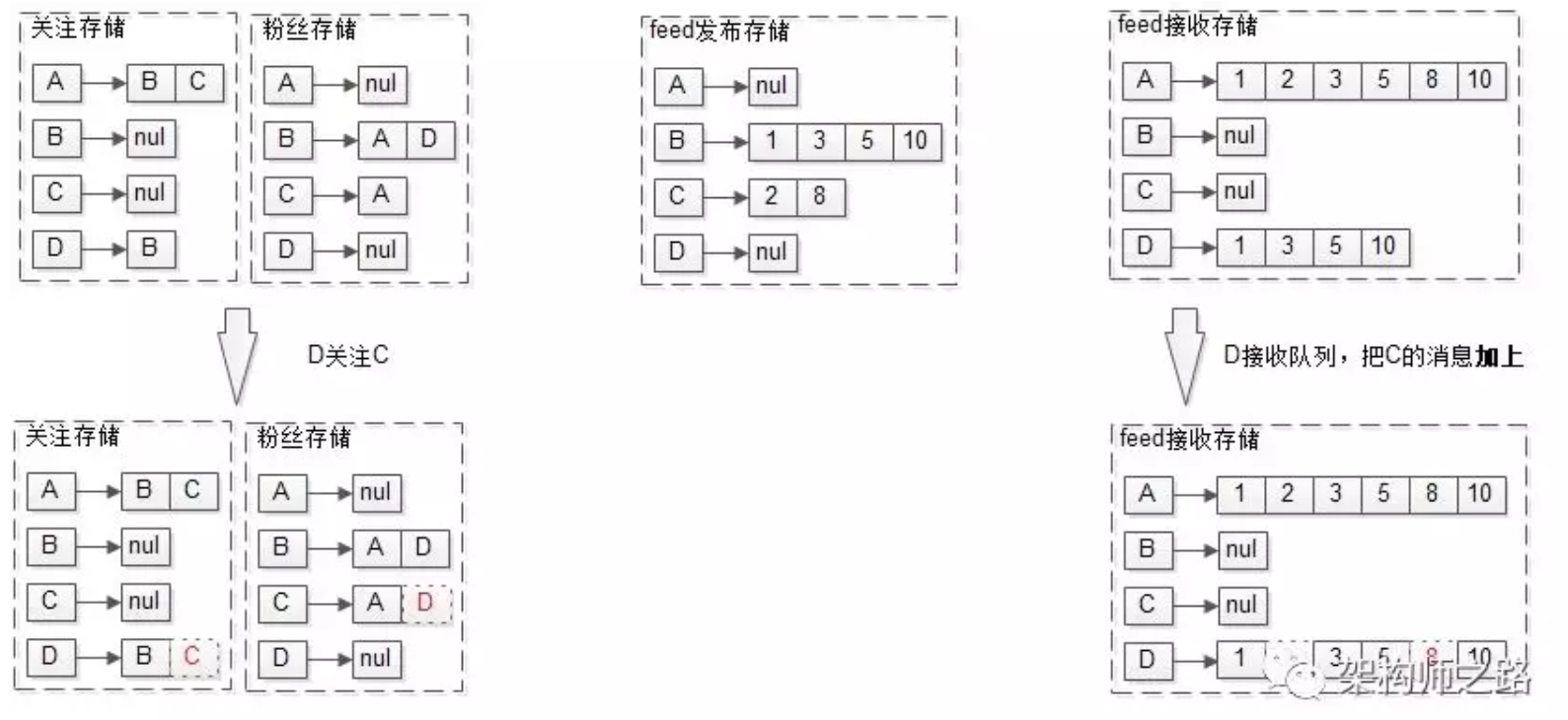
例如D新增关注C:
在D的关注存储里添加C
在C的粉丝存储里添加D
在D的接收feed存储里加入C发布的feed
画外音:有些产品有这样的逻辑,“关注之后才能看到feed”,这样的话就不需要第三步,旧feed无需插入。
在推模式(写扩散)中,取消关注的流程也会变得复杂。

例如A取消关注C:
在A的关注存储里删除C
在C的粉丝存储里删除A
在A的接收feed存储里删除C发布的feed
feed流的推模式(写扩散)的优点是:
消除了拉模式(读扩散)的IO集中点,每个用户都读自己的数据,高并发下锁竞争少
画外音:拉模式(读扩散)中,用户发布feed存储容易称为IO瓶颈。
拉取朋友圈feed流列表的业务流程异常简单,速度很快
拉取朋友圈feed流列表,不需要进行大量的内存计算,网络传输,性能很高
画外音:feed业务是典型的读多写少业务场景,读写比甚至高于100:1,即平均发布1条消息,有至少100次阅读。
其缺点是:
极大极大消耗存储资源,feed数据会存储很多份,例如杨幂5KW粉丝,她每次一发博文,消息会冗余5KW份
画外音:有朋友提出,可以存储一份消息实体,只冗余msgid,这样的话,拉取feed流列表时,还要再次拉取实体,网络时延会更长,所以很多公司选择直接冗余消息实体,当然,这是一个用户体验与存储量的折衷设计。
新增关注,取消关注,发布feed的业务流会更复杂
小结
feed流业务的推拉模式小结:
拉模式,读扩散,feed存一份,存储小,用户集中访问数据,性能差
推模式,写扩散,feed存多份,用冗余存储换锁冲突,性能高

what is feeding and what is 读扩散 and 写扩散?的更多相关文章
- C#多线程:使用ReaderWriterLock类实现多用户读/单用户写同步
摘要:C#提供了System.Threading.ReaderWriterLock类以适应多用户读/单用户写的场景.该类可实现以下功能:如果资源未被写操作锁定,那么任何线程都可对该资源进行读操作锁定, ...
- 改动Oracle GoldenGate(ogg)各个进程的读检查点和写检查点
请注意:请谨慎改动Oracle GoldenGate(ogg)各个进程的读检查点和写检查点. 请确保已经 掌握 ogg 各个进程的读检查点和写检查点的详细含义. BEGIN {NOW | yyyy-m ...
- laravel(lumen)配置读写分离后,强制读主(写)库数据库,解决主从延迟问题
在Model里面加上下面这句,强制读主(写)库数据库,解决主从延迟问题. public static function boot() { //清空从连接,会自动使用主连接 DB::connection ...
- 【转】Linux中文件的可读,可写,可执行权限的解读以及chmod,chown,chgrp命令的用法
chmod是更改文件的权限 chown是改改文件的属主与属组 chgrp只是更改文件的属组. 一.文件权限解读 如上图所示,开头的-rwxrw-r--这一字符串标识文件权限. 这个字符串有10位,可以 ...
- 使用ReaderWriterLock类实现多用户读/单用户写同步
使用ReaderWriterLock类实现多用户读/单用户写同步[1] 2015-03-12 应用程序在访问资源时是进行读操作,写操作相对较少.为解决这一问题,C#提供了System.Threadin ...
- operator[],识别读操作和写操作
body, table{font-family: 微软雅黑; font-size: 10pt} table{border-collapse: collapse; border: solid gray; ...
- HBase 的Get(读),Put(写),Delete(删),Scan(扫描)和Increment(列值递增)
一.HBase介绍 1.基本概念 HBase是一种Hadoop数据库,经常被描述为一种稀疏的,分布式的,持久化的,多维有序映射,它基于行键.列键和时间戳建立索引,是一个可以随机访问的存储和检索数据的平 ...
- python学习二十一天文件可读,可写,可执行的操作
文件无非是可读,可写,可执行的操作,分别对应的模式 r ,w,x,只读模式,只写模式,只执行模式,a模式为追加模式,实际也是写操作模式,r+,w+,a+ 可读写模式,下面详细说模式的用法 1,文件的模 ...
- C#操作XML(读XML,写XML,更新,删除节点,与dataset结合等)【转载】
已知有一个XML文件(bookstore.xml)如下: Corets, Eva 5.95 1.插入节点 往节点中插入一个节点: 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ...
随机推荐
- Instance Segmentation入门总结
前一阵子好忙啊,好久没更新了.最近正好挖了新坑,来更新下.因为之前是做检测的,而目前课题顺道偏到了instance segmentation,这篇文章简单梳理一下从检测.分割结果到instance s ...
- 一键完成SAP部署的秘密,想知道么?
诸如 SAP 这样的企业级应用已成为普遍的流行趋势.考虑到不同行业和需求的特点,所选平台必须能够为不同层面用户和各种 IT 活动提供灵活的容量需求. 此时上云也许是种不错的选择,而想上云的企业,一方面 ...
- 猿创|有赞的zan framework安装与使用[2]
下载并安装comoser curl -sS https://getcomposer.org/installer | php 结果各种超时 不能忍,打开迅雷下载installer:https://get ...
- python入门24 json模块
现在很多接口传参和响应都是json串. json.dumps() python对象转化为json字符串 json.loads() json字符串转化为python对象.[]转变成list,{}转变 ...
- 【转载】#438 - Benefits of Using Interfaces
You might wonder why you'd define an interface, have a class implement that interface and then acces ...
- linux shell中 if else以及大于、小于、等于逻辑表达式介绍
在linux shell编程中,大多数情况下,可以使用测试命令来对条件进行测试,这里简单的介绍下, 比如比较字符串.判断文件是否存在及是否可读等,通常用"[]"来表示条件测试. 注 ...
- postgres循环sql
CREATE OR replace function loop_addDevice(i integer) RETURNS integer as $$ declare count alias ; all ...
- POJ-3267 The Cow Lexicon---删除字符匹配单词
题目链接: https://cn.vjudge.net/problem/POJ-3267 题目大意: 题意就是给出一个主串,和一本字典,问最少在主串删除多少字母,可以使其匹配到字典的单词序列. PS: ...
- POJ 3088 斯特林
题意:有一个n个按钮的锁,按下一些按钮打开门,有多少开门方式,其中,一些按钮可以选,可以不选,选中的按钮 可以分成一些集合,集合之间无序,是同时按下的. 分析: 1.首先选择 i 个按钮,组合数 2. ...
- 【[HEOI2016/TJOI2016]游戏】
据说是网络流棋盘模型了 我们把每一个连续子段都看成一个点,我们先把所有的行上的连续子段找出来给他们编上号,所有列上的连续子段找出来也编上号 现在每个格子都有两个编号了,\(a[i][j]\)表示行所对 ...