Teradata架构
Teradata在整体上是按Shared Nothing 架构体系进行组织的,他的定位就是大型数据仓库系统,定位比较高,他的软硬件都是NCR自己的,其他的都不识别;所以一般的企业用不起,价格很贵。由于Teradata通常被用于OLAP应用,因此单机的Teradata系统很少见,即使是单机系统,Teradata也建议使用SMP结构以尽可能地提供更好的数据库性能,在后面的介绍中,都是按多机系统进行说明的。
根据Shared Nothing的组成结构特点,在物理布局上,Teradata系统主要包括三个部分:
1. 处理节点(Node)、
2. 用于节点间通信的内部高速互联(InterConnection)
3. 数据存储介质(通常是磁盘阵列)。
每个节点都是SMP(对称多处理器结构)结构的单机,节点的物理和逻辑结构如图1所示,多个节点一起构成一个MPP(海量并行处理器结构)系统,多个节点之间的内部高速互联是通过一种被称为BYNET的硬件来实现的,整个系统的组成如图1所示。

单个节点的硬件结构
Teradata系统中的每个节点在物理上都是一个SMP处理单元,事实上就是一台多CPU或多核的计算机。节点硬件包括CPU、内存、用于安装操作系统和应用软件的本地磁盘、与外界交互的网卡及BYNET端口。节点的网卡根据具体的网络环境而不同,通常包括两种:
1. 一种是与IBM MainFrame连接的Channel Adapter
2. 另一种就是我们熟悉的局域网网卡。
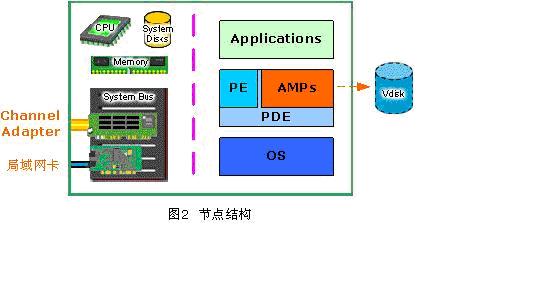
通常情况下一个节点上只会使用一种网卡,但会有多块网卡,分别用于不同的连接和冗余。
单个节点的软件结构
在软件结构上,每个节点自下向上包括操作系统软件(OS)、Teradata并行数据库扩展(PDE)和相关应用程序,其中PDE的主要职责是管理和运行虚拟处理器,其中主要包括PE和AMPs。
(1)Teradata并行数据库扩展(PDE,Parallel Database Extensions),是直接架构在操作系统之上的一个接口层,用于为Teradata提供并行环境,并保证这个并行环境的可运行性和健壮性。PDE的主要功能是执行虚拟处理器、进行Teradata并行任务调度、进行操作系统内核和Teradata数据库的运行时故障处理。
(2)虚拟处理器(VPROC,Virtual Processor),是一系列软件进程,这些进程驻留在一个节点上,依赖PDE环境运行,并接受PDE调度。可以把VPROC理解为一些Teradata的底层服务进程。虚拟处理器完成Teradata数据处理的主要工作,按照工作性质的不同,虚拟处理器主要包括两大类——解析引擎和存取模块处理器。
(3)解析引擎(PE,Parsing Engine),用于进行客户系统(通常是使用Teradata数据库的应用程序的SQL请求)和存取模块处理器之间的通讯和交互,主要的功能包括任务控制(Session Control),SQL语句的解析、优化、查询步骤的生成和分发,并行化预处理和返回查询结果。一个节点上通常有两个PE在工作。
(4)存取模块处理器(AMP,Access Module Processor),这是Teradata数据库的关键进程,用于处理所有与数据有关的文件系统的操作任务,是Teradata数据库Share Nothing架构的核心表现。通常情况下,一个节点上会有多个AMP在工作,每个AMP分别负责文件系统上不同的、固定的数据的存取操作。
(5)虚拟磁盘(VDisk,Virtual Disk),这是一个纯粹的逻辑概念,事实上不应该把它认为是软件结构的一部分。典型的Teradata MPP系统的数据存储都是以磁盘阵列(Disk Arrays)的形式实现的,在物理上是一个个存放于标准磁盘阵列柜中的磁盘阵列模块。Teradata系统中的每个AMP在处理数据存储时,会根据一种哈希算法把不同的数据均匀地分散存储到磁盘阵列中的不同的磁盘上(上海证券交易所的数据仓库就是teradata,每秒的io能达到2G,有1000多块磁盘,硬件昂贵。全表扫描一个几千万条的记录在几秒就完成了)。这样,在逻辑上我们就把磁盘阵列中不同磁盘上存储着的那些由同一个AMP负责存储和维护的数据合并在一起,就像它们在一个磁盘上一样,这就是VDisk的概念了。
(6)message passing layer 消息传递层,主要是对amp之间的通信。它负责处理Teradata数据库内部通讯,即所有的PEs和 AMPs的通讯都要经过MPL,PE分配给AMP的执行步骤通过MPL路由找到合适的AMP,处理完成后,相应消息再经 过MPL路由由AMP返回给相应的PE。MPL这种技术是Teradata并行的基础。
BYNET
在Teradata
MPP系统中,各个节点间的内部高速互联是通过BYNET实现的,我们可以认为它就是Teradata系统中那些松散耦合的节点之间互相联系的通讯总线,但事实上,它却远远没有这么简单。
BYNET是一组硬件和运行在这组硬件上的一些处理通讯任务的软件进程的组合体,用于节点之间的双向广播(bidirectional
broadcast)、多路传递(multicast)和点对点通信(point-to-point
communication),同时,BYNET还实现SQL查询过程中的合并功能(每个节点或AMP,均匀分布表中一部分数据,当查询的时候每个节点并行查询,结果汇总到某个节点反馈给查询者,提高查询速度。
Teradata架构的更多相关文章
- 数据库设计很棒的参考CDM-PDM-LDM-PowerDesigner
此页面显示了涵盖主题领域的 50 个类别中的行业特定数据模型列表,用于创建企业数据模型. 以下是我们所有 1,700 多种数据模型的字母顺序列表 1. 广告 1. 顾客 1. 派对 1. 广告中 ...
- SMP、NUMA、MPP(Teradata)体系结构介绍
从系统架构来看,目前的商用服务器大体可以分为三类,即对称多处理器结构 (SMP : Symmetric Multi-Processor) ,非一致存储访问结构 (NUMA : Non-Uniform ...
- TeraData金融数据模型
Teradata天睿公司(纽交所代码:TDC),是美国前十大上市软件公司之一.经过逾30 年的发展,Teradata天睿公司已经成为全球最大的专注于大数据分析.数据仓库和整合营销管理解决方案的供应商. ...
- 后Hadoop时代的大数据架构(转)
原文:http://zhuanlan.zhihu.com/donglaoshi/19962491 作者: 董飞 提到大数据分析平台,不得不说Hadoop系统,Hadoop到现在也超过10年 ...
- 【转载】从 LinkedIn 的数据处理机制学习数据架构
http://www.36dsj.com/archives/40584 译者:伯乐在线-塔塔 网址:http://blog.jobbole.com/69344/ LinkedIn是当今最流行的专业社交 ...
- 系统架构师JD
#################################################################################################### ...
- 当ArcGIS10.2遇到Teradata
随着计算机技术的不断发展,GIS技术也紧跟IT技术的热潮,从三维技术.到移动技术,从大数据技术到云计算技术,只要IT有的新技术,Esri ...
- 基于两种架构的ETL实现及ETL工具选型策略
企业信息化建设过程中,业务系统各自为政.相互独立造成的"数据孤岛"现象尤为普遍,业务不集成.流程不互通.数据不共享--.这给企业进行数据的分析利用.报表开发等带来了巨大困难.在此情 ...
- 大数据 - Teradata学习体会
引言 随着计算机系统在处理能力.存储能力等方面,特别是计算机软件技术的不断提高,使得信息处理技术得到飞速发展. 数据处理主要分为两大类:联机事物处理OLTP.联机分析处理OLAP.OLTP也就是传统的 ...
随机推荐
- Map泛型集合-国家中文和英文的键值映射
package collection; import java.util.HashMap; import java.util.Map; public class Test5 { public stat ...
- mysql语法语句
将一个字段中的timestamp修改成可视化时间 update table set f1 = IF( LOCATE('-',f1)>0, f1, IFNULL(FROM_UNIXTIME(f1/ ...
- 安裝jpeg-6b png error错误解决方法
安裝jpeg-6b png error错误解决方法 默认安裝jpeg-6b shell> wget ftp://ftp.uu.net/graphics/jpeg/jpegsrc.v6b.tar. ...
- Jackson反序列JSON为实体对象出现:no String-argument constructor/factory method to deserialize from String value的问题
解决方法: 1.JSON字符串中有转义字符,可以替换,也可以直接toString之后清除转移字符. 参考: https://stackoverflow.com/questions/40986738/s ...
- MySQL配置参数:wait_timeout
作者:老王 如果你没有修改过MySQL的配置,缺省情况下,wait_timeout 的初始值是. wait_timeout过大有弊端,其体现就是MySQL里大量的SLEEP进程无法及时释放,拖累系统性 ...
- NAND Flash memory in embedded systems
参考:http://www.design-reuse.com/articles/24503/nand-flash-memory-embedded-systems.html Abstract : Thi ...
- ZeroMQ使用学习记录(转)
ZMQ简介 ZMQ(ØMQ.ZeroMQ, 0MQ)看起来像是一套嵌入式的网络链接库,但工作起来更像是一个并发式的框架.它提供的套接字可以在多种协议中传输消息,如线程间.进程间.TCP.广播等.你可以 ...
- JavaWeb项目实现文件下载
File file = new File(path);// path是根据日志路径和文件名拼接出来的 String filename = file.getName();// 获取日志文件名称 Inpu ...
- GCD部分使用方法
1,用gcd延迟运行任务 假设我们须要某个方法在一段时间后运行.那么我们经常会调用这个方案 - (void)viewDidLoad{ [super viewDidLoad]; [self perfor ...
- selenium的PageObject设计模式
PageObject设计模式1. Web自动化测试框架(WebTestFramework)是基于Selenium框架且采用PageObject设计模式进行二次开发形成的框架. 2. web测试时,建议 ...