RabbitMQ队列,Redis\Memcached缓存
RabbitMQ
RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统。
MQ全称Message Queue,消息队列(MQ)是一种应用程序对应用程序的通信方式。应用程序通过读写出入队列的消息(针对应用程序的数据)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信,直接调用通常是用于诸如远程过程调用的技术。排队指的是应用程序通过队列来通信。队列的使用除去了接收和发送应用程序同时执行的要求。
安装python RabbitMQ 模块
pip install pika
or
easy_install pika
实现一一个简单的队列通信
send端:
import pika
#与RabbitMQ server建立连接
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost')) #服务器地址
channel = connection.channel() #声明queue队列以向其发送消息信息,queue=’hello’ 指定队列名字
channel.queue_declare(queue='hello') #message不能直接发送给queue,需要exchange到达queue,此处使用以空字符串的默认的exchage
#使用默认exchange时允许荣光routing_key明确指定message被发送给哪个queue
#body参数指定了要发送的message内存
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
#关闭与RabbitMQ server间的连接
connection.close()
receive端:
import pika
#建立到达RabbitMQ server的连接
#这里RabbitMQ 位于本机 localhost
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel() #声明queue,确认要从中接收message的queue
# queue_declare 函数 可以运行多次,但只会创建一次
#若可以确认queue是已经存在的,则这里可以省略,但是要习惯这里重新声明
channel.queue_declare(queue='hello')
# 定义回调函数
#一旦从queue中接收到一个消息回调函数将被调用
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
# 从queue接收消息的设置
#包括重哪个queue接收消息,用于处理消息的callback,是否要确认消息
#默认情况下要对消息进行确认,以防消息丢失
#此处 no_ack=True ,不对消息进行确认
channel.basic_consume(callback,
queue='hello',
no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C')
# 开始循环从queue中接收消息,并使用回调函数进行处理
channel.start_consuming()
Work Queues
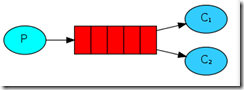
在这种模式下,RabbitMQ会默认把p发的消息依次分发给各个消费者(C),有点类似轮询
P端代码:
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel() #声明queue
channel.queue_declare(queue='task_queue') import sys
# 从命令行构造将要发送的消息
message = ' '.join(sys.argv[1:]) or "Hello World!"
#除了要声明queue是持久化的外,还要生命消息是持久化的
#basic_publish的properties参数指定的消息属性
#此处pika.BasicProperties中的delivery_mode = 2 指明消息为持久化
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2,
))
print(" [x] Sent %r" % message)
connection.close()
C端代码:
import pika,time
#默认情况RabbitMQ 将消息以round-robin方式发送给下一个consumer
#每个consumer接收到的平均 消息量是一样的
connection = pika.BlockingConnection(pika.ConnectionParameters(
'localhost'))
channel = connection.channel() def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_consume(callback,
queue='task_queue',
) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
消息持久化
在声明Queue时使用queue_declare,添加durable=True,代表着消息被持久化了,就是RabbitMQ重启后queue仍然存在
#仅仅对message进行确认不能保证消息,不丢失,比如RabbitMQ 崩溃了queue就会丢失
channel.queue_declare(queue='hello', durable=True)
消息公平分发
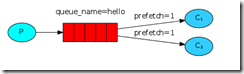
类似负载均衡
如果Rabbit按顺序把消息发送到各个消费者,不考虑负载情况的话,有可能出现配置不高的消费者堆积了很多消息处理不完,配置高的消费着一直清闲。为了解决这个问题,可以再过各个消费者端,配置 perfetch=1,意思就是告诉RabbitMQ在这个消费者还没有处理完之前不再接收新的消息。
channel.basic_qos(prefetch_count=1)
带消息持久化和公平分发的完整代码
生产者:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True) message = ' '.join(sys.argv[1:]) or "Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print(" [x] Sent %r" % message)
connection.close()
消费者:
import pika
import time connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.queue_declare(queue='task_queue', durable=True)
print(' [*] Waiting for messages. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
time.sleep(body.count(b'.'))
print(" [x] Done")
ch.basic_ack(delivery_tag = method.delivery_tag) channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue') channel.start_consuming()
Publish、Subscribe(消息发布,订阅)
之前的例子都是1对1的消息发送和接收,即消息只能发送到指定的queue里,但有时候想让queue有类似广播的效果,这时候就要用到exchange。
exchange在定义的时候是有类型的,以决定到底是哪些queue符合条件,可以接收消息
fanout:所有bind到exchange的queue都可以接收到消息
direct:通过routingKey和exchange 决定的那个唯一的queue可以接收消息
topic:所有符合routingKey(此时可以是一个表达)的bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,* 代表任何字符
使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout
headers:通过headers来决定把消息发给哪些queue
例子:
消息Publisher:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
消费Subscriber:
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='logs',
type='fanout') result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue channel.queue_bind(exchange='logs',
queue=queue_name) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r" % body) channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
有选择的接收消息(exchange type=direct)
RabbitMQ还支持根据关键字发送,即:队列绑定关键字,发送者将数据根据关键字发送到消息exchange,exchange根据关键字判断应该将数据发送至指定队列。
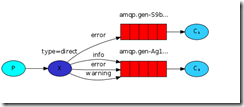
publisher:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') severity = sys.argv[1] if len(sys.argv) > 1 else 'info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
Subscriber:
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='direct_logs',
type='direct') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]\n" % sys.argv[0])
sys.exit(1) for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True) channel.start_consuming()
### no_ack=False,如果生产者遇到情况挂掉,那么RabbitMQ会重新将该任务添加到队列中。
更细致的消息过滤
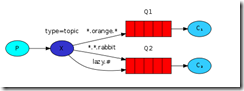
pubisher
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') routing_key = sys.argv[1] if len(sys.argv) > 1 else 'anonymous.info'
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='topic_logs',
routing_key=routing_key,
body=message)
print(" [x] Sent %r:%r" % (routing_key, message))
connection.close()
Subscriber
import pika
import sys connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel() channel.exchange_declare(exchange='topic_logs',
type='topic') result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue binding_keys = sys.argv[1:]
if not binding_keys:
sys.stderr.write("Usage: %s [binding_key]...\n" % sys.argv[0])
sys.exit(1) for binding_key in binding_keys:
channel.queue_bind(exchange='topic_logs',
queue=queue_name,
routing_key=binding_key) print(' [*] Waiting for logs. To exit press CTRL+C') def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body)) channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
Remote procedure call(RPC)
fibonacci_rpc = FibonacciRpcClient()
result = fibonacci_rpc.call(4)
print("fib(4) is %r" % result)
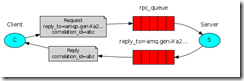
RPC server
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) channel = connection.channel() channel.queue_declare(queue='rpc_queue') def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
# 回调函数,从queue接收到消息后调用该函数进行处理
def on_request(ch, method, props, body):
n = int(body) print(" [.] fib(%s)" % n)
response = fib(n)
# exchange 为空字符串则将消息发送给routing_key指定的queue
# 这里queue为回调函数参数的props中reply_ro指定的queue
# 要发送的消息为计算所地的背波那契数
# properties 中 correlation_id 只定为回调函数参数props中的的correlation_id
# 最后对消息进行确认
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id = \
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
# 只有consumer已经处理并确认了上一条消息时queue才会派发新的消息
channel.basic_qos(prefetch_count=1)
# 设置consumeer参数,即从哪个queue获取消息使用哪个函数进行处理,是否对消息进行确认
channel.basic_consume(on_request, queue='rpc_queue') print(" [x] Awaiting RPC requests")
# 开始接收并处理消息
channel.start_consuming()
RPC client
import pika
import uuid
# 在一个类中封装了connection建立,queue声明,consumer配置,回调函数等
class FibonacciRpcClient(object):
def __init__(self):
# 建立到RabbitMQ的connection
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost')) self.channel = self.connection.channel()
# 声明一个临时的回调队列
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
#此处clinet既是producer又是consumer,因此要配置consumer参数
# 这里的指明从client自己创建的临时队列中接收消息
# 并使用on_response函数处理消息
#不对消息进行确认
self.channel.basic_consume(self.on_response, no_ack=True,
queue=self.callback_queue)
# 定义回调函数
# 比较类的corr_id属性与props中corr_id属性的值
# 若相同则response属性为接收到的消息
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id:
self.response = body def call(self, n):
# 初始化response 和corr_id属性
self.response = None
self.corr_id = str(uuid.uuid4())
# 使用默认exchange向server中定义的rpc_queue发送消息
# 在properties中指定replay_to属性和correlation_id属性用于告知远程server
# correlation_id属性用于匹配 request和response
self.channel.basic_publish(exchange='',
routing_key='rpc_queue',
properties=pika.BasicProperties(
reply_to = self.callback_queue,
correlation_id = self.corr_id,
),
# 消息需要为字符串
body=str(n))
while self.response is None:
self.connection.process_data_events()
return int(self.response)
# 生成类的实例
fibonacci_rpc = FibonacciRpcClient() print(" [x] Requesting fib(30)")
# 调用实例的call方法
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)
Memcached
memcached是一个高性能的分布式内存对象缓存系统,用于动态web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态,数据库驱动网站的速度。
memcached基于一个存储键值对的hashmap。其守护进程(demeon)是用C写的,但是客户端可以用任何语言来编写,并通过memcached协议与守护进程通信。
安装省略
启动memcached
memcached -d -m 10 -u root -l 10.211.55.4 -p 12000 -c 256 -P /tmp/memcached.pid 参数说明:
-d 是启动一个守护进程
-m 是分配给Memcache使用的内存数量,单位是MB
-u 是运行Memcache的用户
-l 是监听的服务器IP地址
-p 是设置Memcache监听的端口,最好是1024以上的端口
-c 选项是最大运行的并发连接数,默认是1024,按照你服务器的负载量来设定
-P 是设置保存Memcache的pid文件
memcached命令:
存储命令: set/add/replace/append/prepend/cas
获取命令: get/gets
其他命令: delete/stats..
第一次操作
import memcache mc = memcache.Client(['10.211.55.4:12000'], debug=True) #debug=True 表示运行出现错误时,显示错误信息,上线后移除该参数
mc.set("foo", "bar")
ret = mc.get('foo')
print(ret)
天生支持集群
python-memcached模块原生支持集群操作,其原理是在内存维护一个i额主机列表,且集群中主机的权重值和主机在列表中重复出现的次数成正比。
如果用户在内存中创建一个键值对(如:k1 = ‘v1’),那么要执行以下步鄹:
- 根据算法将k1转换成一个数字
- 将数字和主机长度求余数,得到一个值N(0 <= N < 列表长度)
- 在主机列表中根据第2步得到的值为索引获取主机,例如host_list[N]
- 连接 将第3步中获取的主机,将 k1 = ‘v1’放置在该服务器的内存中
代码实现如下:
mc = memcache.Client([('1.1.1.1:12000', 1), ('1.1.1.2:12000', 2), ('1.1.1.3:12000', 1)], debug=True)
mc.set('k1', 'v1')
add
添加一条键值对,如果已经存在的key,重复执行add操作异常
import memcache mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.add('k1', 'v1')
# mc.add('k1', 'v2') # 报错,对已经存在的key重复添加,失败!!!
replace
replace修改某个key的值,如果key不存在,则异常
import memcache mc = memcache.Client(['10.211.55.4:12000'], debug=True)
# 如果memcache中存在kkkk,则替换成功,否则异常
mc.replace('kkkk','999')
set 和 set_multi
set 设置一个键值对,如果key不存在,则创建,如果key存在,则修改
set_multi 设置多个键值对,如果key不存在,则创建,如果key存在,则修改
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set('key0', 'wupeiqi')
mc.set_multi({'key1': 'val1', 'key2': 'val2'})
delete 和 delete_multi
delete 删除指定的一个键值对
delete_multi 删除指定的多个键值对
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.delete('key0')
mc.delete_multi(['key1', 'key2'])
get 和 get_multi
get 获取一个键值对
get_multi 获取多个键值对
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True)
val = mc.get('key0')
item_dict = mc.get_multi(["key1", "key2", "key3"])
append 和 prepend
append 修改指定key的值,在该值后面追加内容
prepend 修改指定key的值,在该值前面插入内容
import memcache mc = memcache.Client(['10.211.55.4:12000'], debug=True)
# k1 = "v1" mc.append('k1', 'after')
# k1 = "v1after" mc.prepend('k1', 'before')
# k1 = "beforev1after"
decr 和 incr
incr 自增,将某一个值增加N(默认为1)
decr 自减
import memcache mc = memcache.Client(['10.211.55.4:12000'], debug=True)
mc.set('k1', '777') mc.incr('k1')
# k1 = 778 mc.incr('k1', 10)
# k1 = 788 mc.decr('k1')
# k1 = 787 mc.decr('k1', 10)
# k1 = 777
gets 和 cas
如果商城剩余个数,假设count = 900
A用户刷新页面得到的的count = 900
B用户刷新页面得到的的count = 900
如果A,B都购买商品则缓存中的结构都是count = 899,但是实际不是这样
为了避免这样的情况发生,需要用到gets 和cas
import memcache
mc = memcache.Client(['10.211.55.4:12000'], debug=True, cache_cas=True) v = mc.gets('product_count')
# ...
# 如果有人在gets之后和cas之前修改了product_count,那么,下面的设置将会执行失败,剖出异常,从而避免非正常数据的产生
mc.cas('product_count', "899")
ps:本质上每次执行gets时,会从memcached中获取一个自增的数字,通过cas去修改gets的值时,会携带之前获取的自增值和memcache中的自增值进行比较,如果相等,则额可以提交,如果不相等,那么表示gets和cas执行之间,又有其他人执行了gets(获取了缓冲的指定值),可能出现非正常数据,则不允许修改。
Redis
redis是一个key-value存储系统,和memcache类似,它支持的Value类型相对更多,包括字符串,列表,set(集合),zset(有序集合),hash。这些数据类型都支持push,pop,add,remove及取交集并集差集及更丰富的操作。在此基础上,redis支持各种不同方式的排序。与memcache一样,为了保证效率,数据都是缓存在内存中,区别的是redis会周期性的把更新的数据写入磁盘或者把修改写入追加的记录文件,并且在此基础上实现了主从同步。每个redis有16个库,用户自己无法创建,默认使用第一个库(db = 0)。
操作模式
redis-py提供了两类redis和strictedis用于实现redis的命令,stricttedis用于实习大部分官方命令,并使用官方的语法和命令,reids是stricttedis的子类,用于向后兼容旧版本的redis-py
import redis r = redis.Redis(host='10.211.55.4', port=6379)
r.set('foo', 'Bar')
print(r.get('foo'))
连接池
redis-py使用connection pool 来管理对一个redis server的所有连接,避免每次建立,释放连接的开销。默认,每个redis实例都会维护一个自己的连接池,然后为参数reids,这样就可以实现多个redis实例共享一个连接池。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool)
r.set('foo', 'Bar')
print(r.get('foo'))
操作:
set(name,value,ex=None,px=None,nx=False,xx=False)
在Redis中设置值,默认,不存在则创建,存在则修改
参数:
ex,过期时间(秒)
px,过期时间(毫秒)
nx,如果设置为True,则只有name不存在时,当前set操作才执行
xx,如果设置为True,则只有name存在时,岗前set操作才执行
setnx(name,value)
设置值,只有name不存在时,执行设置操作(添加)
setex(name,value,time)
# 设置值
# 参数:
# time,过期时间(数字秒 或 timedelta对象)
psetex(name,time_ms,value)
# 设置值
# 参数:
# time_ms,过期时间(数字毫秒 或 timedelta对象)
mset(*args,**kwargs)
批量设置值
如:
mset(k1='v1', k2='v2')
或
mget({'k1': 'v1', 'k2': 'v2'})
get(name)
#获取值
mget(keys,*args)
批量获取
如:
mget('ylr', 'abc')
或
r.mget(['ylr', 'abc'])
getset(name,value)
# 设置新值并获取原来的值
getrange(key,start,end)
# 获取子序列(根据字节获取,非字符)
# 参数:
# name,Redis 的 name
# start,起始位置(字节)
# end,结束位置(字节)
# 如: "我是谁" ,0-3表示 "我"
setrange(name,offset,value)
# 修改字符串内容,从指定字符串索引开始向后替换(新值太长时,则向后添加)
# 参数:
# offset,字符串的索引,字节(一个汉字三个字节)
# value,要设置的值
setbit(name,offset,value)
# 对name对应值的二进制表示的位进行操作
# 因为值在redis里面是以字符形式存在的,所以这里在操作数字的时候,这里数字需要先找到对应的ASCII的值,把这个ASCII十进制数转换为二进制数,再进行操作 # 参数:
# name,redis的name
# offset,位的索引(将值变换成二进制后再进行索引)
# value,值只能是 1 或 0 # 注:如果在Redis中有一个对应: n1 = "foo",
那么字符串foo的二进制表示为:01100110 01101111 01101111
所以,如果执行 setbit('n1', 7, 1),则就会将第7位设置为1,
那么最终二进制则变成 01100111 01101111 01101111,即:"goo" # 扩展,转换二进制表示:
source = "foo" for i in source:
num = ord(i)
print(bin(num).replace('b',''))
getbit(name,offset)
# 获取name对应的值的二进制表示中的某位的值 (0或1)
bitcount(key,start=None,end=None)
# 获取name对应的值的二进制表示中 1 的个数
# 参数:
# key,Redis的name
# start,位起始位置
# end,位结束位置
bitop(operation,dest,*keys)
# 获取多个值,并将值做位运算,将最后的结果保存至新的name对应的值 # 参数:
# operation,AND(并) 、 OR(或) 、 NOT(非) 、 XOR(异或)
# dest, 新的Redis的name
# *keys,要查找的Redis的name # 如:
bitop("AND", 'new_name', 'n1', 'n2', 'n3')
# 获取Redis中n1,n2,n3对应的值,然后讲所有的值做位运算(求并集),然后将结果保存 new_name 对应的值中
strlen(name)
# 返回name对应值的字节长度(一个汉字3个字节)
incr(self,name,amount=1)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数:
# name,Redis的name
# amount,自增数(必须是整数) # 注:同incrby
incrbyfloat(self,name,amout=1.0)
# 自增 name对应的值,当name不存在时,则创建name=amount,否则,则自增。 # 参数:
# name,Redis的name
# amount,自增数(浮点型)
decr(self,name,amout =1)
# 自减 name对应的值,当name不存在时,则创建name=amount,否则,则自减。 # 参数:
# name,Redis的name
# amount,自减数(整数)
append(key,value)
# 在redis name对应的值后面追加内容 # 参数:
key, redis的name
value, 要追加的字符串
hash操作
hset(name,key,value)
# name对应的hash中设置一个键值对(不存在,则创建;否则,修改) # 参数:
# name,redis的name
# key,name对应的hash中的key
# value,name对应的hash中的value # 注:
# hsetnx(name, key, value),当name对应的hash中不存在当前key时则创建(相当于添加)
hmset(name,mapping)
# 在name对应的hash中批量设置键值对 # 参数:
# name,redis的name
# mapping,字典,如:{'k1':'v1', 'k2': 'v2'} # 如:
# r.hmset('xx', {'k1':'v1', 'k2': 'v2'})
hget(name,key)
# 在name对应的hash中获取根据key获取value
hmget(name,keys,*agrs)
# 在name对应的hash中获取多个key的值 # 参数:
# name,reids对应的name
# keys,要获取key集合,如:['k1', 'k2', 'k3']
# *args,要获取的key,如:k1,k2,k3 # 如:
# r.mget('xx', ['k1', 'k2'])
# 或
# print(r.hmget('xx', 'k1', 'k2'))
hgetall(name)
# 获取name对应hash的所有键值
hlen(name)
# 获取name对应的hash中键值对的个数
hkeys(name)
# 获取name对应的hash中所有的key的值
hvals(name)
# 获取name对应的hash中所有的value的值
hexists(name,key)
# 检查name对应的hash是否存在当前传入的key
hdel(name,*keys)
# 将name对应的hash中指定key的键值对删除
hincrby(name,key,amount=1)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount
# 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(整数)
hincrbyfloat(name,key,amount=1.0)
# 自增name对应的hash中的指定key的值,不存在则创建key=amount # 参数:
# name,redis中的name
# key, hash对应的key
# amount,自增数(浮点数) # 自增name对应的hash中的指定key的值,不存在则创建key=amount
hscan(name,cursor=0,match=None,count=None)
# 增量式迭代获取,对于数据大的数据非常有用,hscan可以实现分片的获取数据,并非一次性将数据全部获取完,从而放置内存被撑爆 # 参数:
# name,redis的name
# cursor,游标(基于游标分批取获取数据)
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# 第一次:cursor1, data1 = r.hscan('xx', cursor=0, match=None, count=None)
# 第二次:cursor2, data1 = r.hscan('xx', cursor=cursor1, match=None, count=None)
# ...
# 直到返回值cursor的值为0时,表示数据已经通过分片获取完毕
hscan_iter(name,match=None,count=None)
# 利用yield封装hscan创建生成器,实现分批去redis中获取数据 # 参数:
# match,匹配指定key,默认None 表示所有的key
# count,每次分片最少获取个数,默认None表示采用Redis的默认分片个数 # 如:
# for item in r.hscan_iter('xx'):
# print(item)
list操作
redis中的list在内存中按照一个name对应一个list来存储。
lpush(name,values)
# 在name对应的list中添加元素,每个新的元素都添加到列表的最左边 # 如:
# r.lpush('oo', 11,22,33)
# 保存顺序为: 33,22,11 # 扩展:
# rpush(name, values) 表示从右向左操作
lpushx(name,value)
# 在name对应的list中添加元素,只有name已经存在时,值添加到列表的最左边 # 更多:
# rpushx(name, value) 表示从右向左操作
llen(name)
# name对应的list元素的个数
linsert(name,where,refvale,value)
# 在name对应的列表的某一个值前或后插入一个新值 # 参数:
# name,redis的name
# where,BEFORE或AFTER
# refvalue,标杆值,即:在它前后插入数据
# value,要插入的数据
r.lset(name,index,value)
# 对name对应的list中的某一个索引位置重新赋值 # 参数:
# name,redis的name
# index,list的索引位置
# value,要设置的值
r.lrem(name,vale,num)
# 在name对应的list中删除指定的值 # 参数:
# name,redis的name
# value,要删除的值
# num, num=0,删除列表中所有的指定值;
# num=2,从前到后,删除2个;
# num=-2,从后向前,删除2个
lpop(name)
# 在name对应的列表的左侧获取第一个元素并在列表中移除,返回值则是第一个元素 # 更多:
# rpop(name) 表示从右向左操作
lindex(name,index)
# 在name对应的列表中根据索引获取列表元素
lrange(name,start,end)
# 在name对应的列表分片获取数据
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
ltrim(name,start,end)
# 在name对应的列表中移除没有在start-end索引之间的值
# 参数:
# name,redis的name
# start,索引的起始位置
# end,索引结束位置
rpoplpush(src,dst)
# 从一个列表取出最右边的元素,同时将其添加至另一个列表的最左边
# 参数:
# src,要取数据的列表的name
# dst,要添加数据的列表的name
blpop(keys,timeout)
# 将多个列表排列,按照从左到右去pop对应列表的元素 # 参数:
# keys,redis的name的集合
# timeout,超时时间,当元素所有列表的元素获取完之后,阻塞等待列表内有数据的时间(秒), 0 表示永远阻塞 # 更多:
# r.brpop(keys, timeout),从右向左获取数据
brpoplpush(src,dst,timeout=0)
# 从一个列表的右侧移除一个元素并将其添加到另一个列表的左侧 # 参数:
# src,取出并要移除元素的列表对应的name
# dst,要插入元素的列表对应的name
# timeout,当src对应的列表中没有数据时,阻塞等待其有数据的超时时间(秒),0 表示永远阻塞
自定义增量迭代
# 由于redis类库中没有提供对列表元素的增量迭代,如果想要循环name对应的列表的所有元素,那么就需要:
# 1、获取name对应的所有列表
# 2、循环列表
# 但是,如果列表非常大,那么就有可能在第一步时就将程序的内容撑爆,所有有必要自定义一个增量迭代的功能: def list_iter(name):
"""
自定义redis列表增量迭代
:param name: redis中的name,即:迭代name对应的列表
:return: yield 返回 列表元素
"""
list_count = r.llen(name)
for index in xrange(list_count):
yield r.lindex(name, index) # 使用
for item in list_iter('pp'):
print(item)
set操作
set集合就是不允许重复的列表
sadd(name,values)
# name对应的集合中添加元素
scard(name)
# 获取name对应的集合中元素个数
sdiff(keys,*args)
# 在第一个name对应的集合中且不在其他name对应的集合的元素集合
sdiffstore(dest,keys,*args)
# 获取第一个name对应的集合中且不在其他name对应的集合,再将其新加入到dest对应的集合中
sinter(keys,*args)
# 获取多一个name对应集合的并集
sinterstore(dest,keys,*args)
# 获取多一个name对应集合的并集,再讲其加入到dest对应的集合中
sismember(name,value)
# 检查value是否是name对应的集合的成员
smembers(name)
# 获取name对应的集合的所有成员
smove(src,dst,value)
# 将某个成员从一个集合中移动到另外一个集合
spop(name)
# 从集合的右侧(尾部)移除一个成员,并将其返回
sranmember(name,numbers)
# 从name对应的集合中随机获取 numbers 个元素
srem(name,values)
# 在name对应的集合中删除某些值
sunion(keys,*args)
# 获取多一个name对应的集合的并集
sunionstore(dest,keys,*args)
# 获取多一个name对应的集合的并集,并将结果保存到dest对应的集合中
sscan(name,cursor=0,match=None,count=None)
sscan_iter(name,match=None,count=None)
# 同字符串的操作,用于增量迭代分批获取元素,避免内存消耗太大
有序集合
在集合的基础上,为每元素排序,元素的排序需要根据另外一个值来进行比较,所以,对于有序集合,每一个元素有两个值,即:值和分数,分数用来做排序
zadd(name,*args,**kwargs)
# 在name对应的有序集合中添加元素
# 如:
# zadd('zz', 'n1', 1, 'n2', 2)
# 或
# zadd('zz', n1=11, n2=22)
zcard(name)
# 获取name对应的有序集合元素的数量
zcount(name,min,max)
# 获取name对应的有序集合中分数 在 [min,max] 之间的个数
zincrby(name,value,amount)
# 自增name对应的有序集合的 name 对应的分数
r.zrange(name,start,end,desc=False,withscores=False,score_cast_func=float)
# 按照索引范围获取name对应的有序集合的元素 # 参数:
# name,redis的name
# start,有序集合索引起始位置(非分数)
# end,有序集合索引结束位置(非分数)
# desc,排序规则,默认按照分数从小到大排序
# withscores,是否获取元素的分数,默认只获取元素的值
# score_cast_func,对分数进行数据转换的函数 # 更多:
# 从大到小排序
# zrevrange(name, start, end, withscores=False, score_cast_func=float) # 按照分数范围获取name对应的有序集合的元素
# zrangebyscore(name, min, max, start=None, num=None, withscores=False, score_cast_func=float)
# 从大到小排序
# zrevrangebyscore(name, max, min, start=None, num=None, withscores=False, score_cast_func=float)
zrank(name,value)
# 获取某个值在 name对应的有序集合中的排行(从 0 开始) # 更多:
# zrevrank(name, value),从大到小排序
zrangebylex(name,min,max,start=None,num=None)
# 当有序集合的所有成员都具有相同的分值时,有序集合的元素会根据成员的 值 (lexicographical ordering)来进行排序,而这个命令则可以返回给定的有序集合键 key 中, 元素的值介于 min 和 max 之间的成员
# 对集合中的每个成员进行逐个字节的对比(byte-by-byte compare), 并按照从低到高的顺序, 返回排序后的集合成员。 如果两个字符串有一部分内容是相同的话, 那么命令会认为较长的字符串比较短的字符串要大 # 参数:
# name,redis的name
# min,左区间(值)。 + 表示正无限; - 表示负无限; ( 表示开区间; [ 则表示闭区间
# min,右区间(值)
# start,对结果进行分片处理,索引位置
# num,对结果进行分片处理,索引后面的num个元素 # 如:
# ZADD myzset 0 aa 0 ba 0 ca 0 da 0 ea 0 fa 0 ga
# r.zrangebylex('myzset', "-", "[ca") 结果为:['aa', 'ba', 'ca'] # 更多:
# 从大到小排序
# zrevrangebylex(name, max, min, start=None, num=None)
zrem(name,values)
# 删除name对应的有序集合中值是values的成员
# 如:zrem('zz', ['s1', 's2'])
zremrangebyrank(name,min,max)
# 根据排行范围删除
zremrangebyscore(name,min,max)
# 根据分数范围删除
zermrangebylex(name,min,max)
# 根据值返回删除
zscore(name,value)
# 获取name对应有序集合中 value 对应的分数
zinterstore(dest,keys,aggregate=None)
# 获取两个有序集合的交集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zunionstore(dest,keys,aggregate=None)
# 获取两个有序集合的并集,如果遇到相同值不同分数,则按照aggregate进行操作
# aggregate的值为: SUM MIN MAX
zscan(name,cursor=0,match=None,count=None,score_cast_func=float)
zscan_iter(name,match=None,conut=None,socre_cast_func=float)
# 同字符串相似,相较于字符串新增score_cast_func,用来对分数进行操作
其他常用操作
delete(*names)
# 根据删除redis中的任意数据类型
exists(name)
# 检测redis的name是否存在
keys(pattern=’*’)
# 根据模型获取redis的name # 更多:
# KEYS * 匹配数据库中所有 key 。
# KEYS h?llo 匹配 hello , hallo 和 hxllo 等。
# KEYS h*llo 匹配 hllo 和 heeeeello 等。
# KEYS h[ae]llo 匹配 hello 和 hallo ,但不匹配 hillo
expire(name,time)
# 为某个redis的某个name设置超时时间
rename(src,dst)
# 对redis的name重命名为
move(name,db)
# 将redis的某个值移动到指定的db下
randomkey()
# 随机获取一个redis的name(不删除)
type(name)
# 获取name对应值的类型
scan(cursor=0,match=None,count=None)
scan_iter(match=None,count=None)
# 同字符串操作,用于增量迭代获取key
管道
redis-py默认在执行每次请求都会创建(连接池申请连接)和断开(归还连接池)一次连接操作,如果想要在一次请求中指定多个命令,则可以使用pipline实现一次请求指定多个命令。
import redis pool = redis.ConnectionPool(host='10.211.55.4', port=6379) r = redis.Redis(connection_pool=pool) # pipe = r.pipeline(transaction=False)
pipe = r.pipeline(transaction=True) r.set('name', 'alex')
r.set('role', 'sb') pipe.execute()
发布订阅
例子:
monitor 代码:
import redis
class RedisHelper:
def __init__(self):
self.__conn = redis.Redis(host='10.211.55.4')
self.chan_sub = 'fm104.5'
self.chan_pub = 'fm104.5'
def public(self, msg):
self.__conn.publish(self.chan_pub, msg)
return True
def subscribe(self):
pub = self.__conn.pubsub()
pub.subscribe(self.chan_sub)
pub.parse_response()
return pub
订阅者:
from monitor.RedisHelper import RedisHelper obj = RedisHelper()
redis_sub = obj.subscribe() while True:
msg= redis_sub.parse_response()
print(msg)
发表者:
from monitor.RedisHelper import RedisHelper obj = RedisHelper()
obj.public('hello')
RabbitMQ队列,Redis\Memcached缓存的更多相关文章
- RabbitMQ队列/Redis缓存
一.RabbitMQ队列 RabbitMQ安装(Centos7安装):1.安装依赖:yum install socat (不安装会报错)2.下载rpm包:wget http://www.rabbitm ...
- python RabbitMQ队列/redis
RabbitMQ队列 rabbitMQ是消息队列:想想之前的我们学过队列queue:threading queue(线程queue,多个线程之间进行数据交互).进程queue(父进程与子进程进行交互或 ...
- springboot2.0+redis实现消息队列+redis做缓存+mysql
本博客仅供参考,本人实现没有问题. 1.环境 先安装redis.mysql 2.springboot2.0的项目搭建(请自行完成),本人是maven项目,因此只需配置,获取相应的jar包,配置贴出. ...
- Day10 - Python协程、异步IO、redis缓存、rabbitMQ队列
Python之路,Day9 - 异步IO\数据库\队列\缓存 本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitM ...
- Day10-Python3基础-协程、异步IO、redis缓存、rabbitMQ队列
内容目录: Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko S ...
- Python之协程、异步IO、redis缓存、rabbitMQ队列
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko SS ...
- 异步IO\数据库\队列\缓存\RabbitMQ队列
本节内容 Gevent协程 Select\Poll\Epoll异步IO与事件驱动 Python连接Mysql数据库操作 RabbitMQ队列 Redis\Memcached缓存 Paramiko SS ...
- 缓存、队列(Memcached、redis、RabbitMQ)
本章内容: Memcached 简介.安装.使用 Python 操作 Memcached 天生支持集群 redis 简介.安装.使用.实例 Python 操作 Redis String.Hash.Li ...
- Python自动化 【第十一篇】:Python进阶-RabbitMQ队列/Memcached/Redis
本节内容: RabbitMQ队列 Memcached Redis 1. RabbitMQ 安装 http://www.rabbitmq.com/install-standalone-mac.htm ...
随机推荐
- nginx 基础配置详解
#本文只对nginx的最基本配置项做一些解释,对于配置文件拆分管理,更详细的集群健康检查的几种方式,检查策略等在此不做详细解释了. #运行用户user nobody;#启动进程,通常设置成和cpu的数 ...
- Linux项目部署发布
Linux项目部署发布 1.部署环境准备,准备python3和虚拟环境解释器,virtualenvwrapper pip3 install -i https://pypi.douban.com/sim ...
- 《linux 内核全然剖析》 fork.c 代码分析笔记
fork.c 代码分析笔记 verifiy_area long last_pid=0; //全局变量,用来记录眼下最大的pid数值 void verify_area(void * addr,int s ...
- 存储过程 & 触发器
触发器主要是通过事件进行触发而被执行的,而存储过程可以通过存储过程名字而被直接调用.当对某一表进行诸如UPDATE. INSERT. DELETE 这些操作时, 就会自动执行触发器所定义的SQL 语句 ...
- GeekforGeeks Trie - 键树简单介绍 - 构造 插入 和 搜索
版权声明:本文作者靖心,靖空间地址:http://blog.csdn.net/kenden23/,未经本作者同意不得转载. https://blog.csdn.net/kenden23/article ...
- SAP 改表方法
SAP中直接修改表.视图的Tcode有SE16N和SM30. 1. SE16N修改表需要先输入命令&SAP_EDIT,回车左下角显示激活SAP编辑功能后,就可以对相应的表进行新增.删除.修改的 ...
- selenium鼠标悬停操作
有些网页一打开会有一个弹窗,弹窗不消失无法进行取元素操作,只有把鼠标悬停在上面弹窗才会消失,这时就用到了selenium的悬停操作 鼠标悬停 move_to_element() 定位到要悬停的元素 ...
- HDU - 1033 Edge 【模拟】
题目链接 http://acm.hdu.edu.cn/showproblem.php?pid=1033 题意 给定一个起始点 300 420 走的第一步是 310 420 下面的每一步 都由 输入决定 ...
- iOS UIImage 拉伸问题 (适用于UIButton等需要局部拉伸的情况)
图片 有的切图切很大 还占用ipa大小,有时候 切图 只需要 局部或者说 一个压缩的图片的抽象状态 直接上代码 CGFloat top = ; // 顶端盖高度 ; // 底端盖高度 ; // 左端盖 ...
- P2163 [SHOI2007]园丁的烦恼
题目 P2163 [SHOI2007]园丁的烦恼 做法 关于拆点,要真想拆直接全部用树状数组水过不就好了 做这题我们练一下\(cdq\)分治 左下角\((x1,y1)\)右上角\((x2,y2)\), ...