Android DOM解析XML方法及优化
在Android应用开发中,我们常常要在应用启动后从服务器下载一些配置文件,这些配置文件包含一些项目中可能用到的资源,这些文件很多情况下是XML文件,这时就要将XML下载到文件中保存,之后再解析XML。解析XML的方法有DOM, SAX, JDOM, DOM4J,本文中只使用了DOM,下面先介绍DOM的基础知识和解析XML的方法,然后再结合一个项目实例来实现从XML文件的下载到解析整个过程。
DOM(Document Object Model,文档对象模型)定义了访问和操作XML的标准方法。基于DOM的XML解析器会将整个XML文档转化成对象模型集合,这个集合是树结构。这样我们就可以通过DOM接口来访问任意的节点,整个DOM树的结构和XML文档的数据分层结构相似,所以对开发者来说DOM接口的使用就很方便和直观了。但是,不足之处在于,由于这个DOM树是保存在内存中的,如果XML文档中数据很多,结构很复杂,那么就会导致其对内存的要求高,遍历一次的时间长。
下面来看一个XML文档中数据的例子。
<bookstore> <book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book> </bookstore>
该文档转化成DOM树,如下
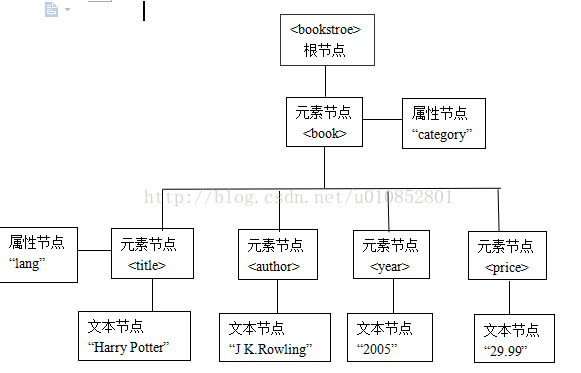
在DOM数中,XML文档中每个成分都是一个节点。
1.整个XML文档是一个文档节点;
2.每个XML标签是一个元素节点;
3.包含在XML标签中的文本是一个文档节点;
4.每个XML属性是一个属性节点;
5.注释属于注释节点。
需要注意的是:<year>2005</year> 中的year是一个元素节点,2005是元素节点year的子节点(文本节点)的值,不是year节点的值。
DOM中节点的属性
nodeName节点的名称
元素节点nodeName与标签名相同
属性节点nodeName与属性的名称
文本节点nodeName永远是#text
文档节点nodeName永远是#document
nodeValue节点的值
元素节点的nodeValue值是undefined
文本节点的nodeValue值是文本本身
属性节点的nodeValue是属性值
nodeType节点的类型
元素节点:1
属性节点:2
文本节点:3
注释节点:4
文档节点:9
DOM中的方法
getElementsByTagName()返回拥有指定名标签的所有元素。
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("title");
使用childNodes 或 getElementsByTagName() 属性或方法时,会返回 NodeList 。在NodeList中保存的节点不包含属性节点。
元素节点的 attributes 属性返回属性节点的列表。
xmlDoc=loadXMLDoc("books.xml");
x=xmlDoc.getElementsByTagName("book")[0].attributes;
下面结合在项目开发中的一个实例来完整的介绍DOM解析XML方法的使用。
1. 从服务器端下载XML文档并保存到本地
/**
* 从服务器端下载配置文件,并保存在basesettings.xml中
*
*/
private void downLoadConfigXml(){ String sValue=null;
sValue=PLATE_WWW+“baseconfig.xml” //得到URL,PLATE_WWW是平台的URL
Log.i(TAG,"baseconfig sValue=="+sValue);
final String url=sValue; //开启一个新的线程来下载XML文档
new Thread(){
public void run(){
HttpClient client=new DefaultHttpClient();
HttpGet get=new HttpGet(url);
HttpResponse response;
try{
response=client.execute(get);
HttpEntity entity=response.getEntity();
long length=entity.getContentLength();
InputSteam is=entity.getContent();
FileOutputStream fileOutputStream=null;
if(is!=null){
//开启存放XML文档的文件流
fileOutputStream=openFileOutput("baseconfig.xml",
Context.MODE_WORLD_READABLE+Context.MODE_WORLD_WRITLEABLE);
byte[]buf=new byte[1024];
int ch=-1;
while((ch=is.read(buf))!=-1){
Log.i(TAG,"ConfigXml下载中...");
fileOutputStream.write(buf,0,ch);
}
}
fileOutputStream.flush();
//下载完毕,关闭文件流
if(fileOutputStream!=null){
fileOutputStream.close();
}
Log.i(TAG,"ConfigXml下载完成");
}catch(ClientProtocolException e){
e.printStackTrace();
//下载出现错误,通过Handler来做出UI上的提示
mHandler .obtainMessage(GlobalDef.WM_ALL_SERVER_FAIL).sendToTarget();
}catch(){
e.printStackTrace();
//下载出现错误,通过Handler来做出UI上的提示
mHandler .obtainMessage(GlobalDef.WM_ALL_SERVER_FAIL).sendToTarget();
}
}
}.start();
}
2.创建DOM解析器
/**
* DOM解析器:包含对XML文档的加载和解析方法
*/
public class MyXml{
Document mDocument;//代表整个XML文档树,其nodeName为#document
Element mDocRoot;//根节点,也是一个元素节点
NodeList mNodeList;//节点链表
Node mNode;//节点
int mNodeIndex=0;//遍历树时的索引 //DOM加载XML文档:有以下三种
public boolean loadXML(byte[] sXML){ DocumentBuilderFactory docFactory=DocumentBuildFactory.newInstance();
DocumentBuild docBuilder;
try{
docBuilder=docFactory.newDocumentBuilder();
InputStream is=new ByteArrayInputStream(sXML);
mDocument=docBuilder.parse(is,"GB2312");//文档节点
mDocRoot=mDocument.getDoucmentElement();//返回DOM树的根结点
}catch(Exception e){
e.printStackTrace();
return false;
}
return true;
} public boolean loadXML(byte[] sXML, String sCodec)//设置编码形式
{
DocumentBuilderFactory docFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder docBuilder;
try {
String str = new String(sXML, sCodec);
docBuilder = docFactory.newDocumentBuilder();
InputStream is = new ByteArrayInputStream(str.getBytes()); mDocument = docBuilder.parse(is);
mDocRoot = m_Document.getDocumentElement(); } catch (Exception e) {
e.printStackTrace();
return false;
}
return true;
} public boolean loadIS(InputStream is, String sCodec)
{
DocumentBuilderFactory docFactory = DocumentBuilderFactory.newInstance();
DocumentBuilder docBuilder;
try {
docBuilder = docFactory.newDocumentBuilder();
mDocument = docBuilder.parse(is);
mDocRoot = m_Document.getDocumentElement();//获取根节点 } catch (Exception e) {
e.printStackTrace();
return false;
} catch (OutOfMemoryError e) {
e.printStackTrace();
return false;
}
return true;
}
}
所要解析的XML文档内容
<items>
<gifthead>
<gifttype>1</gifttype>
<giftname>初次相见</giftname>
<giftsort>1</giftsort>
</gifthead>
<item>
<index>100001</index>
<picname>100001.bmp</picname>
<bigpicname>100001.gif</bigpicname>
<itemname>鲜花</itemname>
</item>
<NewVer>1</NewVer>
</items>
我们通过DOM在XML中寻找节点时,往往效率低下,因为每寻找一个节点就需要从新遍历一次DOM树,在这里我在MyXml类中封装了方法GetNodeList,可以把要查询的节点的路径作为参数传入,这样就可以优化这个查询效率。比如<item>的子节点中的<picname>节点,那么以picname/item/items的形式传入,即可获得所有的item节点下的picname节点。
public boolean SelectNodeToList(String sExpress)
{
if(mDocRoot==null)
return false;
mNodeList = GetNodeList(sExpress);
mNodeIndex = 0;
if(mNodeList !=null)
{
return true;
}
else
return false;
} public NodeList GetNodeList(String sExpress)
{
if(mDocRoot==null)
return null;
try {
String [] sNodePaths = sExpress.split("/");//用“/”来分隔String,分隔后的字段中没有“/”,得到[, , items] Element currentNode = m_DocRoot;
List<String> sNodeTree = new ArrayList<String>();
for(int i = 0;i<sNodePaths.length;i++)
{
if(sNodePaths[i].length()!=0)
{
sNodeTree.add(sNodePaths[i]);//“item”加到List中
}
}
for(int i = 0;i<sNodeTree.size() - 1;i++)
{
// Log.i(i+": ");
// Log.i(sNodeTree.get(i));
if(!sNodeTree.get(i).equals(""))
{
// Log.i("currentNode = (Element) (currentNode.getElementsByTagName(sNodeTree.get(i))).item(0);");
currentNode = (Element) (currentNode.getElementsByTagName(sNodeTree.get(i))).item(0);//获取根节点的子节点中所有名为items节点集合中的第一个节点
}
}
// Log.i(sNodeTree.size()-1+": ");
// Log.i(sNodeTree.get(sNodeTree.size()-1));
mNodeList = currentNode.getElementsByTagName(sNodeTree.get(sNodeTree.size()-1));
if(mNodeList.getLength() == 0 && currentNode.getNodeName().equals(sNodeTree.get(sNodeTree.size()-1)) &¤tNode == mDocRoot)
{
mNodeList = mDocument.getChildNodes();
}//修正Android4.0系统收不到消息的bug } catch (Exception e) {
Log.i(TAG, "GetNodeList m_NodeList = currentNode.getElementsByTagName(sNodeTree.get(sNodeTree.size()-1)) error.");
e.printStackTrace();
return null;
}
if(mNodeList !=null)
{
return mNodeList;
}
else
return null;
} public Node GetNode(String sExpress)
{
if(mDocRoot==null)
return null;
if(sExpress.equals("."))
return m_DocRoot; try { String [] sNodePaths = sExpress.split("/"); Element currentNode = m_DocRoot;
List<String> sNodeTree = new ArrayList<String>();
for(int i = 0;i<sNodePaths.length;i++)
{
if(sNodePaths[i].length()!=0)
{
sNodeTree.add(sNodePaths[i]);
}
}
for(int i = 0;i<sNodeTree.size() - 1;i++)
{
// Log.i(i+": ");
// Log.i(sNodeTree.get(i));
if(!sNodeTree.get(i).equals(""))
{
// Log.i("currentNode = (Element) (currentNode.getElementsByTagName(sNodeTree.get(i))).item(0);");
currentNode = (Element) (currentNode.getElementsByTagName(sNodeTree.get(i))).item(0);
}
}
// Log.i(sNodeTree.size()-1+": ");
// Log.i(sNodeTree.get(sNodeTree.size()-1)); mNodeList = currentNode.getElementsByTagName(sNodeTree.get(sNodeTree.size()-1)); } catch (Exception e) {
e.printStackTrace();
}
if(mNodeList !=null)
{
return mNodeList.item(0);
}
else
return null;
} public Node QueryNode(boolean bReset)
{
// Log.i("QueryNode "+bReset);
if (bReset)
{
mNodeIndex = 0;
return mNodeList.item(mNodeIndex);
} try
{
// Log.i("QueryNode "+bReset);
mNode = null;
mNode = mNodeList.item(mNodeIndex);
mNodeIndex++;
// Log.i("mNodeIndex"+mNodeIndex+"="+mNode);
}
catch(Exception e)
{
Log.w(TAG, "QueryNode mNode = mNodeList.item(mNodeIndex) error.");
} return m_Node;
} //获取m_Node节点下指定的节点的值
public String GetValueByName(String sName)
{
//Log.i(TAG, "GetValueByName: sName = "+sName);
Element element = (Element)m_Node;
String sValue = null;
if(sName.equals("."))
{
try{
sValue = mNode.getFirstChild().getNodeValue();
}catch(Exception e){
Log.i(TAG, "GetValueByName("+ sName +") --> sValue = mNode.getFirstChild().getNodeValue() error.");
}
}
else
{
try
{
NodeList nodelist = element.getElementsByTagName(sName);
if(nodelist != null)
{
sValue = nodelist.item(0).getFirstChild().getNodeValue();
}
}catch(Exception e){
// Log.i(TAG, "GetValueByName ("+ sName +") --> sValue = nodelist.item(0).getFirstChild().getNodeValue() error.");
}
}
if(sValue==null)
{
// Log.w(TAG, sName+"节点值sValue==null, Return");
}
return sValue;
}
Android DOM解析XML方法及优化的更多相关文章
- Android DOM解析XML示例程序
DOM方式解析xml是先把xml文档都读到内存中,然后再用DOM API来访问树形结构,并获取数据的.DOM比较符合人的思维模式,但是其对内存的消耗比较大. activity_main.xml < ...
- android DOM解析Xml
文章转自:http://blog.sina.com.cn/s/blog_a661f16c0101d5qp.html People类是自己写的一个类,主要保存各个字符串数据. 由于没学过Xml语法只 ...
- Android之DOM解析XML
一.DOM解析方法介绍 DOM是基于树形结构的节点或信息片段的集合,允许开发人员使用DOM API遍历XML树,检索所需数据.分析该结构通常需要加载整个文档和构造树形结构,然后才可以检索和更新节点信息 ...
- Android中解析XML格式数据的方法
XML介绍:Extensible Markup Language,即可扩展标记语言 一.概述 Android中解析XML格式数据大致有三种方法: SAX DOM PULL 二.详解 2.1 SAX S ...
- [置顶] Android学习系列-Android中解析xml(7)
Android学习系列-Android中解析xml(7) 一,概述 1,一个是DOM,它是生成一个树,有了树以后你搜索.查找都可以做. 2,另一种是基于流的,就是解析器从头到尾解析一遍xml文件. ...
- JAVA中使用DOM解析XML文件
XML是一种方便快捷高效的数据保存传输的格式,在JSON广泛使用之前,XML是服务器和客户端之间数据传输的主要方式.因此,需要使用各种方式,解析服务器传送过来的信息,以供使用者查看. JAVA作为一种 ...
- Java从零开始学四十二(DOM解析XML)
一.DOM解析XML xml文件 favorite.xml <?xml version="1.0" encoding="UTF-8" standalone ...
- xml语法、DTD约束xml、Schema约束xml、DOM解析xml
今日大纲 1.什么是xml.xml的作用 2.xml的语法 3.DTD约束xml 4.Schema约束xml 5.DOM解析xml 1.什么是xml.xml的作用 1.1.xml介绍 在前面学习的ht ...
- python 解析XML python模块xml.dom解析xml实例代码
分享下python中使用模块xml.dom解析xml文件的实例代码,学习下python解析xml文件的方法. 原文转自:http://www.jbxue.com/article/16587.html ...
随机推荐
- mysql 不同库不同表字段数据复制
需求:把一个表某个字段内容复制到另一张表的某个字段. 实现sql语句1: UPDATE file_manager_folder f1 LEFT OUTER JOIN file_manager_fold ...
- Android源码下载之----内核需要另外下载
用repo sync下载的android源码默认不包含kernel目录,需要自己另外下载. 下载命令:$ git clone https://android.googlesource.com/kern ...
- 【React Native开发】React Native配置执行官方样例-刚開始学习的人的福音(8)
),React Native技术交流4群(458982758),请不要反复加群! 欢迎各位大牛,React Native技术爱好者加入交流!同一时候博客左側欢迎微信扫描关注订阅号,移动技术干货,精彩文 ...
- Leetcode - CopyWithRandomList
Algorithm: Iterate and copy the original list first. For the random pointer, just copy the value fro ...
- 鸟哥的Linux私房菜-----6、文件与文件夹管理
- 服务器端获取表单数据的编码解码问题(servlet)
首先需要明确指出的是,这里的服务器是指tomcat. 在页面没有明确指定编码的情况下,客户端通过input标签和字符串向服务器传递两个值param1和param2.如果直接使用request.getP ...
- 【BZOJ2728】[HNOI2012]与非 并查集+数位DP
[BZOJ2728][HNOI2012]与非 Description Input 输入文件第一行是用空格隔开的四个正整数N,K,L和R,接下来的一行是N个非负整数A1,A2……AN,其含义如上所述. ...
- 【BZOJ4930】棋盘 拆边费用流
[BZOJ4930]棋盘 Description 给定一个n×n的棋盘,棋盘上每个位置要么为空要么为障碍.定义棋盘上两个位置(x,y),(u,v)能互相攻击当前仅 当满足以下两个条件: 1:x=u或y ...
- JVM性能优化, Part 5 Java的伸缩性
很多程序员在解决JVM性能问题的时候,花开了很多时间去调优应用程序级别的性能瓶颈,当你读完这本系列文章之后你会发现我可能更加系统地看待这类的问题.我说过JVM的自身技术限制了Java企业级应用的伸缩性 ...
- 【leetcode刷题笔记】Subsets
Given a set of distinct integers, S, return all possible subsets. Note: Elements in a subset must be ...