【Soft-Margin Support Vector Machine】林轩田机器学习技术
Hard-Margin的约束太强了:要求必须把所有点都分开。这样就可能带来overfiiting,把noise也当成正确的样本点了。
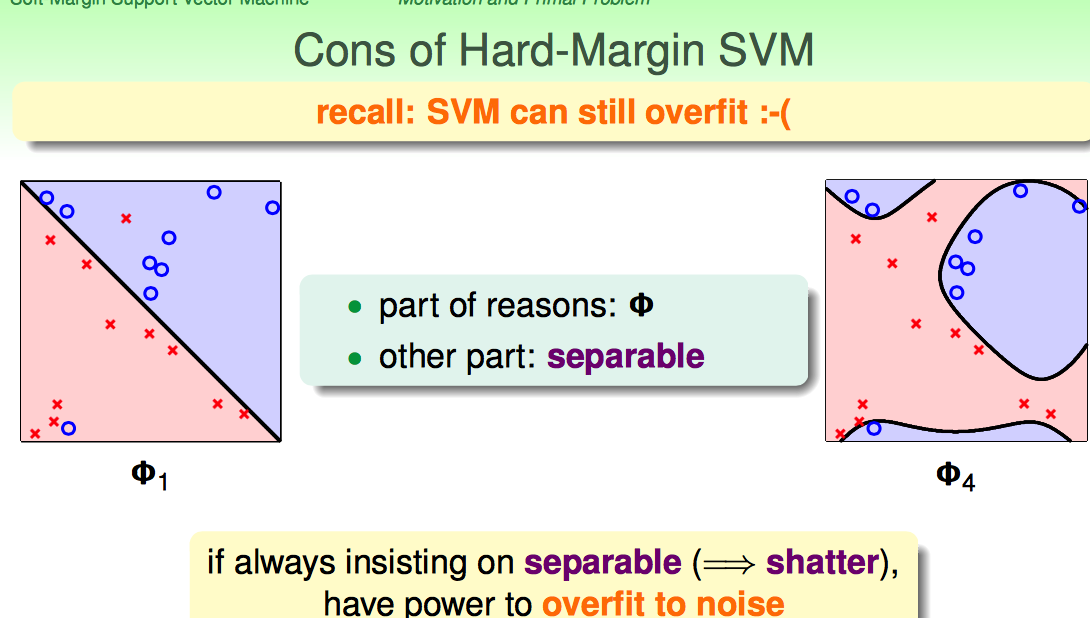
Hard-Margin有些“学习洁癖”,如何克服这种学习洁癖呢?

沿用pocket算法的思想,修改一下优化目标函数的形式,补上一个错分点的惩罚项CΣ...。
(1)C越大,对错误的容忍度就越小,margin越小
(2)C越小,对错误容忍度就越高,margin越大
因此引入的参数C是在large margin和noise tolerance之间做了一个权衡。
但是上面这种形式,有两个弊端:
(1)由于需要判断“等与不等”,所以是NP-hard Solution
(2)无法区分犯错点的错误程度
因此,引出了soft-margin的改进:

引入一个新的松弛因子kesi:
(1)既能解决学习洁癖的问题
(2)又能表示violation的程度是多少(kesi小于1还是分队的点,只不过此时点还在margin与hyperplane中间;kesi大于1表示分错了,越到hyperplance的另一端去了)
(3)还能转化成标准的QP问题,易于求解
接下来,沿用hard-margin dual svm的思路,把soft-margin SVM primal → dual。

由于不等式约束条件变成了两类,所以自然引入两个Largrange乘子;再沿用hard-margin的转化思路,转化成dual问题求解。
首先对kesi进行求导,化简原优化目标函数:

结论:
(1)利用对kesi求导为0的条件,把beta和kesi都去掉
(2)增加一个对alpha的约束条件

再进行接下来的化简,最终形式跟hard-margin很像。
不同之处在于对alpha增加了一个上界的约束条件。
一切看起来都比较顺利,但是在优化完成后,我们需要求解W和b。

W好求(alphan!=0的点,就可以作为支撑向量),问题的关键是b怎么求。


这里需要回顾KKT中的complementary slackness条件。
这里林直接给出来了,要free的那些SV(即满足kesi=0)来求解b;即对b求解有帮助的点,是真正在margin边界上的SV。
如果对之前SVM的complementary slackness内容不是很熟练,这块容易理解不好:为啥要分三类呢?
在这里,我重新理解了一下complementary slackness的意义。
意义就是,dual problem求出的最优解,带入原问题必须能使得Lagrange disappear。
由dual problem的推导可知,最优解的一个约束就是0<=alpha<=C,所以可以按照alpha取值分三种情况讨论。
(1)当alphan=0的时候:kesin=0,此时yn(W'xn+b)>=1-kesin必然成立(如果不成立,肯定不能作为最优解了);
此时,要么在margin的边界上(取等);更多的情况是yn(W'xn+b)>1(远离边界的点)
(2)当0<alphan<C的时候:kesin=0,并且yn(W'xn+b)=1-kesin=1,这两个等式都要成立;
显然,这时候就是满足条件的SV所在
(3)当alphan=C的时候:kesin可以不为零,但yn(W'xn+b)=1-kesin一定成立;
(3.a)这些点还是分对了,kesin小于1,只不过处于最大margin的内部
(3.b)这些点分错了,kesin大于1,已经越到hyperplane的另一侧了
对比hard-margin SVM问题:
之前min的目标函数是1/2W’W,但不要忘记了,之所以敢把min的目标函数写成1/2W'W的条件,是有yn(W'xn+b)>=1来保证的。
现在支撑向量依然是yn(W'xn+b)=1(绝大多数情况都有支撑向量,少数情况没有支撑向量),但是允许有一些向量可以yn(W'xn+b)<1;至于小多少,则要靠kesin来确定。
回想linear SVM的求解过程:alphan=0的点 都是SV candidates,但是不一定是SV
再联系Soft-Margin SVM的求解过程:alhphan=0的点同样要排除,因为仅仅是candidates; 但同时又多了一个约束alphan=C的时候,kesin可以不是0,kesin也可以是0,因此也仅仅能作为free SV的candidate;为了排除这两部分的candidates,掐头去尾,只取0<kesin<C的点作为free SV。
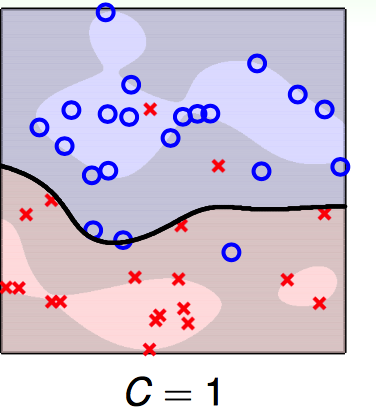
直观上松弛因子是怎么作用的?想象下面的一种情况:
输入数据是下图:
需要优化的目标函数和约束条件如下:
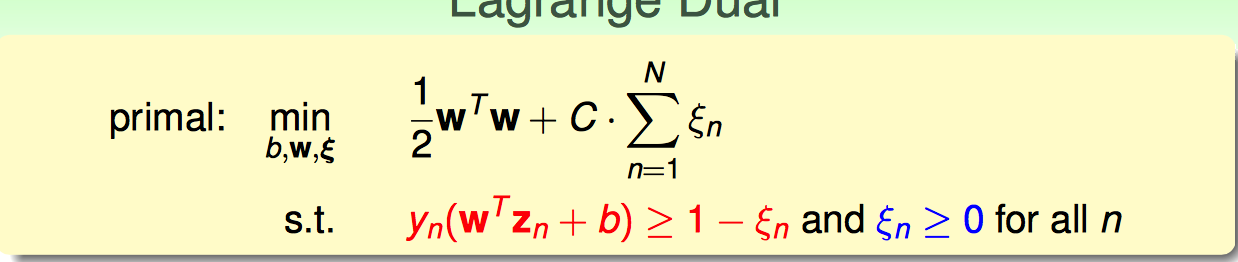
现在考虑处理hidden在圈圈中的那个红叉给分对,面临的情况是这样的:
(1)如果把其分对,则1/2W'W会增大不少(比如0<kesin<1,如果将其分对了,则就跟hard-margin SVM一样了;即yn(Wnew'xn+b)>=1,这里的Wnew = W/1-kesin;显然1/2W’W增加了,而如果这个增加的幅度大于Ckesin,则优化过程就会选择将其分错,以保证primal的问题最优)
(2)如果把其分错且认了,错就错了,则多付出的代价是C*kesin
这时候就要权衡让1/2W'W增大的与分错付出的代价C*kesin哪个大了?
如果是下面两种情况:

由于C取得很大,所以分错的代价太大了,1/2W‘W与其比起来太弱了;因此就倾向于将所有的点都分对;于是overfitting了。
实际中,要适当选取各种参数。
一般来说,如果支撑向量的个数太多了,都存在过拟合的风险。
【Soft-Margin Support Vector Machine】林轩田机器学习技术的更多相关文章
- 【Kernal Support Vector Machine】林轩田机器学习技术
考虑dual SVM 问题:如果对原输入变量做了non-linear transform,那么在二次规划计算Q矩阵的时候,就面临着:先做转换,再做内积:如果转换后的项数很多(如100次多项式转换),那 ...
- 【Gradient Boosted Decision Tree】林轩田机器学习技术
GBDT之前实习的时候就听说应用很广,现在终于有机会系统的了解一下. 首先对比上节课讲的Random Forest模型,引出AdaBoost-DTree(D) AdaBoost-DTree可以类比Ad ...
- 【Kernel Logistic Regression】林轩田机器学习技术
最近求职真慌,一方面要看机器学习,一方面还刷代码.还是静下心继续看看课程,因为觉得实在讲的太好了.能求啥样搬砖工作就随缘吧. 这节课的核心就在如何把kernel trick到logistic regr ...
- (转载)林轩田机器学习基石课程学习笔记1 — The Learning Problem
(转载)林轩田机器学习基石课程学习笔记1 - The Learning Problem When Can Machine Learn? Why Can Machine Learn? How Can M ...
- 【Linear Support Vector Machine】林轩田机器学习技法
首先从介绍了Large_margin Separating Hyperplane的概念. (在linear separable的前提下)找到largest-margin的分界面,即最胖的那条分界线.下 ...
- 【Dual Support Vector Machine】林轩田机器学习技法
这节课内容介绍了SVM的核心. 首先,既然SVM都可以转化为二次规划问题了,为啥还有有Dual啥的呢?原因如下: 如果x进行non-linear transform后,二次规划算法需要面对的是d`+1 ...
- 【Support Vector Regression】林轩田机器学习技法
上节课讲了Kernel的技巧如何应用到Logistic Regression中.核心是L2 regularized的error形式的linear model是可以应用Kernel技巧的. 这一节,继续 ...
- 【Matrix Factorization】林轩田机器学习技法
在NNet这个系列中讲了Matrix Factorization感觉上怪怪的,但是听完第一小节课程就明白了. 林首先介绍了机器学习里面比较困难的一种问题:categorical features 这种 ...
- 【 Logistic Regression 】林轩田机器学习基石
这里提出Logistic Regression的角度是Soft Binary Classification.输出限定在0~1之间,用于表示可能发生positive的概率. 具体的做法是在Linear ...
随机推荐
- Html5 web本地存储
Web Storage是HTML5引入的一个非常重要的功能,可以在客户端本地存储数据,类似HTML4的cookie,但可实现功能要比cookie强大的多,cookie大小被限制在4KB,Web Sto ...
- Ubuntu 系统安装
1.首先下载一个Ubuntu系统文件,以.ios后缀结尾的系统镜像文件压缩包. 2,下载一个ultraiso软件,用于制作u盘启动盘 3,将电脑重启,进入BOIS界面,调整系统顺序, 将启动盘系统设置 ...
- 814. Binary Tree Pruning(leetcode) (tree traverse)
https://leetcode.com/contest/weekly-contest-79/problems/binary-tree-pruning/ -- 814 from leetcode tr ...
- 简单广搜,迷宫问题(POJ3984)
题目链接:http://poj.org/problem?id=3984 解题报告: 1.设置node结构体,成员pre记录该点的前驱. 2.递归输出: void print(int i) { ) { ...
- Poj(1789),最小生成树,Prim
题目链接:http://poj.org/problem?id=1789 还是套路. #include <stdio.h> #include <string.h> #define ...
- EK算法应用,构图(POJ1149)
题目链接:http://poj.org/problem?id=1149 题意中有一点要注意,否则构图就会有问题,每个顾客走后,被打开过的那些猪圈中的猪都可以被任意的调换到其他开着的猪圈中. 这里的构图 ...
- 2018.8.15 AOP面向切面编程简单理解
在Filter过滤器中 拦截器 表面上看 -拦截器帮我们封装了很多功能 拦截器优秀的设计,可拔插设计 aop思想 在struts2中 归纳总结
- 在网页标题上加个logo
只需在title标签上加个link标签即可 <link rel="icon" href="images/icon.png" > <title& ...
- python__标准库 : 测试代码运行时间(timeit)
用 timeit.Timer.timeit() 方法来测试代码的运行时间: from timeit import Timer def t1(): li = [] ): li.append(i) def ...
- 使用file_get_contents()和curl()抓取网络资源的效率对比
使用file_get_contents()和curl()抓取网络资源的效率对比 在将小程序用户头像合成海报的时候,用到了抓取用户头像对应的网络资源,那么抓取方式有很多,比如 file_get_cont ...