【原创】Linux环境下的图形系统和AMD R600显卡编程(11)——R600指令集
1 低级着色语言tgsi
OpenGL程序使用GLSL语言对可编程图形处理器进行编程,GLSL语言(以下高级着色语言就是指GLSL)是语法类似C的高级语言,在GLSL规范中,GLSL语言被先翻译成教低级的类汇编语言,然后被翻译成硬件特定的指令集。OpenGL体系管理委员会于2002年6月和2002年9月分别通过了两个官方扩展:ARB_VERTEX_PROGRAM与ARB_FRAGMENT_PROGRAM来统一对低级着色语言的支持,GLSL语言被编译成针对这两个扩展的低级着色语言(因此这两个扩展可以看成是GLSL运行的虚拟机),显卡厂商的驱动将低级着色语言翻译成GPU指令。这两个扩展的1.0版本分别是arbvpl0和arbfpl0,这两个扩展的2.0版本分别是arbvp20和arbfp2。
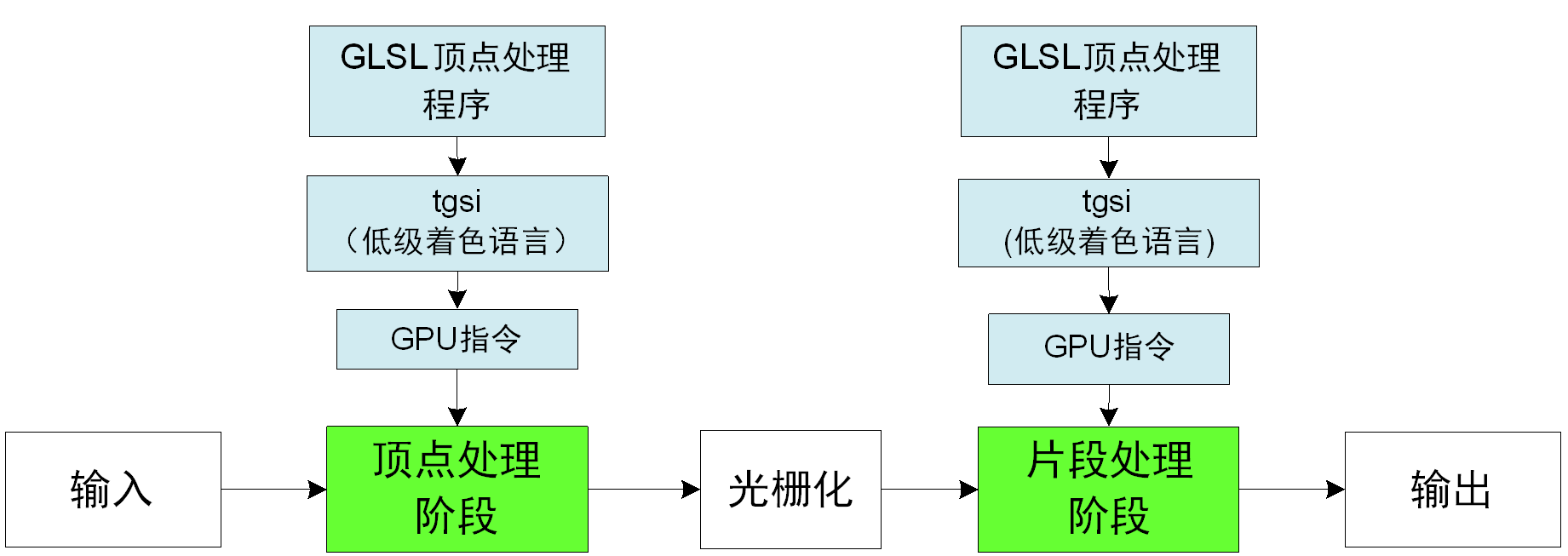
图1
目前,在Mesa上,GLSL首先被编译器翻译成tgsi中间语言,然后显卡特定的驱动将这些tgsi语言的代码编译成GPU指令,这个过程如图1示(不考虑geometry shader和tesselation shader)。这里有tgsi的详细描述。这篇硕士论文“高级着色语言及其优化编译”对GLSL和低级着色语言有比较详细的论述。
2 R600指令
在CPU上运行的程序,所有的访存指令和运算指令按照代码的堆叠顺序执行(不考虑指令集并行),如果有跳转指令则跳转到相应位置。
GPU主要用于运算,早期的GPU没有包含复杂的控制程序,R600 Shader程序和CPU程序比较显得比较简陋,必须有专门的代码指示程序的执行顺序,并且指示程序运行顺序的指令(Control Flow 指令,后面称为CF 指令)、运算指令(后面称ALU指令)和访存指令(在R600 GPU 中称为Fetch 指令)必须按照类别存放,同一种类型的指令放在一起,不同类型的指令按照某种顺序存放,同一类型的指令(不包括CF指令)构成一个Clause。图2显示了R600 GPU Shader程序在显存中存放的形式。

图2
R600的指令包含Control Flow(后面简称CF)指令,ALU(运算)指令,Vertex Fecth (取顶点)指令和Texture Fetch(取纹理)指令。指令的格式称为Microde Format。
每一个Shader程序(Pixel Shader或者Vertex Shader)包含两部分,一部分是CF指令,另一部分是Clause。 这些Clause由CF 指令初始化(或者不恰当的理解成Clause 由CF指令调用)。R600的每一条指令的格式(为了保持和手册上术语的一致,后面将使用Microcode Format这个词)都包含了2 个或者4个DWORD(CF 和ALU为2个DWORD,Vertex Fetch 和Texture Fetch 为4个DWORD,后面在说地址的时候都是以DWORD为单位的),这些Microcode Format可以在“R600 Family Instruction Set Architecture”手册上查阅到。
下面将使用两个实例来说明R600的指令集。和下面这两个实例等价的GLSL程序大概是这个样子的:
// vertex shader
attribute vec4 a_position;
attribute vec3 a_texture;
varying vec2 v_texCoord;
void main()
{
gl_Position = a_position;
v_texCoord = a_texture;
}
// pixel shader
uniform sample2D sampler;
varying vec2 v_texCoord;
void main ()
{
gl_FragColor = texture2D(sampler, v_texCoord);
}
3 Vertex Shader示例
下面使用一个具体的实例来说明,下面的程序来自我们的R600 EXA驱动的Copy过程的Vertex Shader(请参考后续章节),按照图2的要求,这段程序被分成了两部分,第一部分是CF指令,共四条指令,指令0~指令3(指令3为空指令,用于对齐),第二部分为取顶点指令,共两条指令,指令4~ 指令5,分别用于取顶点位置坐标和纹理坐标。
int R600_copy_vs(RADEONChipFamily ChipSet, uint32_t* shader)
{
int i = 0;
/* 0 指令0 */
shader[i++] = CF_DWORD0(ADDR(4));
shader[i++] = CF_DWORD1(POP_COUNT(0), CF_CONST(0),
COND(SQ_CF_COND_ACTIVE), I_COUNT(2), CALL_COUNT(0),
END_OF_PROGRAM(0), VALID_PIXEL_MODE(0), CF_INST(SQ_CF_INST_VTX),
WHOLE_QUAD_MODE(0), BARRIER(1));
/* 1 指令1 */
shader[i++] = CF_ALLOC_IMP_EXP_DWORD0(ARRAY_BASE(CF_POS0), TYPE(SQ_EXPORT_POS), RW_GPR(1),
RW_REL(ABSOLUTE), INDEX_GPR(0), ELEM_SIZE(0));
shader[i++] = CF_ALLOC_IMP_EXP_DWORD1_SWIZ(SRC_SEL_X(SQ_SEL_X), SRC_SEL_Y(SQ_SEL_Y), SRC_SEL_Z(SQ_SEL_Z),
SRC_SEL_W(SQ_SEL_W), R6xx_ELEM_LOOP(0), BURST_COUNT(0), END_OF_PROGRAM(0),
VALID_PIXEL_MODE(0), CF_INST(SQ_CF_INST_EXPORT_DONE), WHOLE_QUAD_MODE(0),
BARRIER(1));
/* 2 指令2 */
shader[i++] = CF_ALLOC_IMP_EXP_DWORD0(ARRAY_BASE(0), TYPE(SQ_EXPORT_PARAM), RW_GPR(0),
RW_REL(ABSOLUTE), INDEX_GPR(0), ELEM_SIZE(0));
shader[i++] = CF_ALLOC_IMP_EXP_DWORD1_SWIZ(SRC_SEL_X(SQ_SEL_X), SRC_SEL_Y(SQ_SEL_Y),
SRC_SEL_Z(SQ_SEL_Z), SRC_SEL_W(SQ_SEL_W), R6xx_ELEM_LOOP(0),
BURST_COUNT(0), END_OF_PROGRAM(1), VALID_PIXEL_MODE(0),
CF_INST(SQ_CF_INST_EXPORT_DONE), WHOLE_QUAD_MODE(0), BARRIER(0));
/* 3 指令3*/
shader[i++] = 0x00000000;
shader[i++] = 0x00000000;
/* 4/5 指令4 */
shader[i++] = VTX_DWORD0(VTX_INST(SQ_VTX_INST_FETCH), FETCH_TYPE(SQ_VTX_FETCH_VERTEX_DATA),
FETCH_WHOLE_QUAD(0), BUFFER_ID(0), SRC_GPR(0), SRC_REL(ABSOLUTE),
SRC_SEL_X(SQ_SEL_X), MEGA_FETCH_COUNT(16));
shader[i++] = VTX_DWORD1_GPR(DST_GPR(1), DST_REL(0), DST_SEL_X(SQ_SEL_X), DST_SEL_Y(SQ_SEL_Y),
DST_SEL_Z(SQ_SEL_0), DST_SEL_W(SQ_SEL_1), USE_CONST_FIELDS(0),
DATA_FORMAT(FMT_32_32_FLOAT), NUM_FORMAT_ALL(SQ_NUM_FORMAT_SCALED),
FORMAT_COMP_ALL(SQ_FORMAT_COMP_SIGNED), SRF_MODE_ALL(SRF_MODE_ZERO_CLAMP_MINUS_ONE));
shader[i++] = VTX_DWORD2(OFFSET(0),
#if X_BYTE_ORDER == X_BIG_ENDIAN
ENDIAN_SWAP(SQ_ENDIAN_8IN32),
#else
ENDIAN_SWAP(SQ_ENDIAN_NONE),
#endif
CONST_BUF_NO_STRIDE(0), MEGA_FETCH(1));
shader[i++] = VTX_DWORD_PAD;
/* 6/7 指令5 */
shader[i++] = VTX_DWORD0(VTX_INST(SQ_VTX_INST_FETCH), FETCH_TYPE(SQ_VTX_FETCH_VERTEX_DATA),
FETCH_WHOLE_QUAD(0), BUFFER_ID(0), SRC_GPR(0), SRC_REL(ABSOLUTE),
SRC_SEL_X(SQ_SEL_X), MEGA_FETCH_COUNT(8));
shader[i++] = VTX_DWORD1_GPR(DST_GPR(0), DST_REL(0), DST_SEL_X(SQ_SEL_X), DST_SEL_Y(SQ_SEL_Y),
DST_SEL_Z(SQ_SEL_0), DST_SEL_W(SQ_SEL_1), USE_CONST_FIELDS(0),
DATA_FORMAT(FMT_32_32_FLOAT), NUM_FORMAT_ALL(SQ_NUM_FORMAT_SCALED),
FORMAT_COMP_ALL(SQ_FORMAT_COMP_SIGNED),
SRF_MODE_ALL(SRF_MODE_ZERO_CLAMP_MINUS_ONE));
shader[i++] = VTX_DWORD2(OFFSET(8),
#if X_BYTE_ORDER == X_BIG_ENDIAN
ENDIAN_SWAP(SQ_ENDIAN_8IN32),
#else
ENDIAN_SWAP(SQ_ENDIAN_NONE),
#endif
CONST_BUF_NO_STRIDE(0), MEGA_FETCH(0));
shader[i++] = VTX_DWORD_PAD;
return i;
}
上面程序的运行过程如
结合下面这几张图详细描述程序运行的过程。
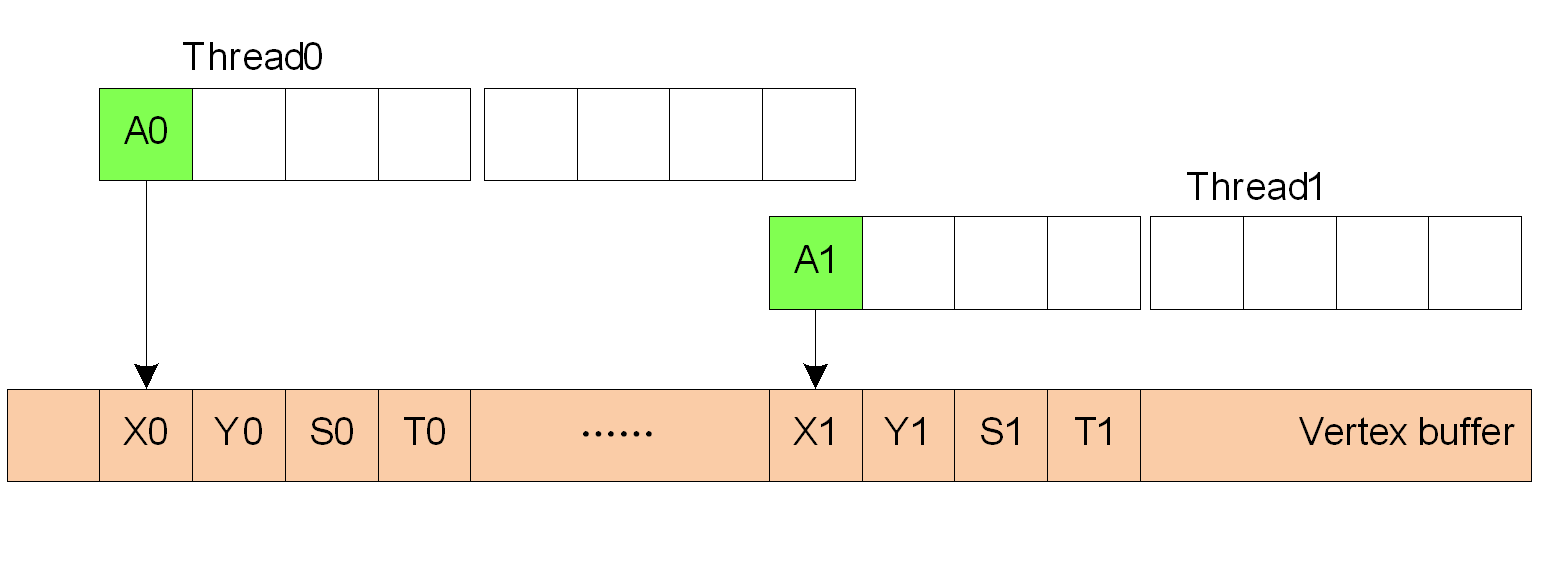
图3

图4
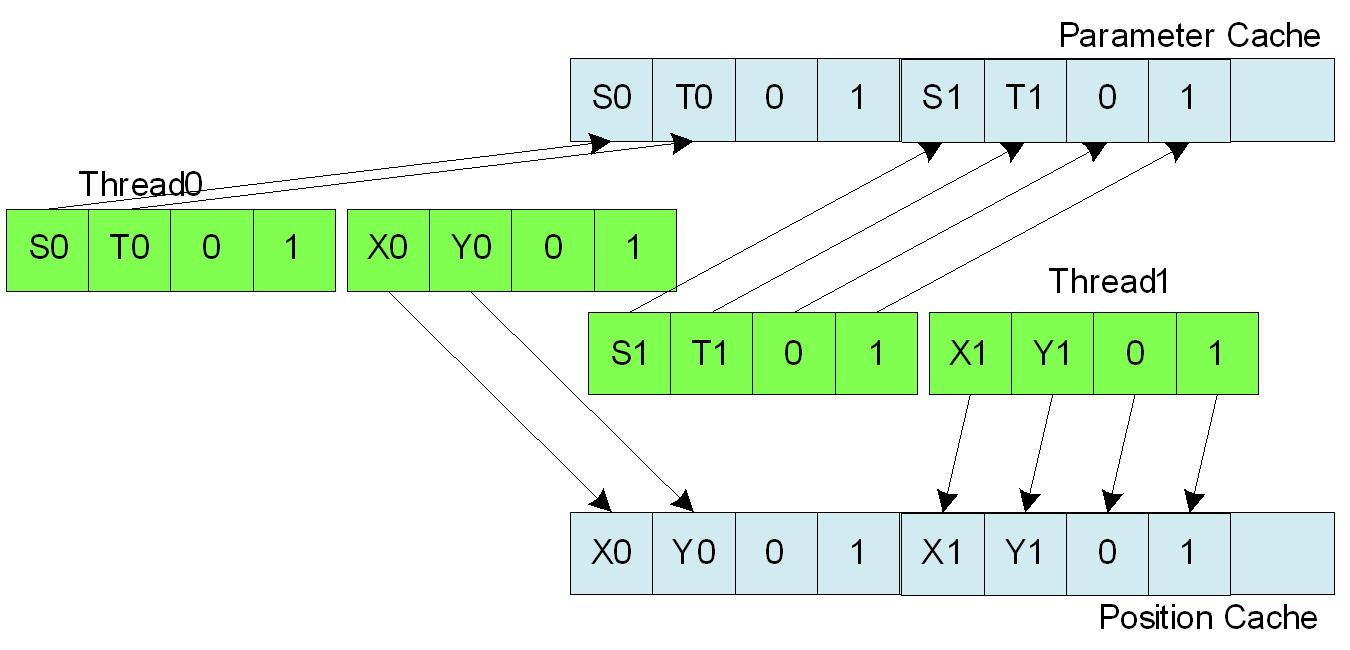
图5
图3示,初始状态,图中有两个线程,此刻两个线程正在要两个顶点数据进行处理。
- CF指令0, 指令0的ADDR位指示程序从地址4处的指令(指令4)开始运行,I_COUNT位指示共执行2条指令(指令4和指令5),执行完后回到指令0,指令0的END_OF_PROGRAM位表明程序还没有结束,继续执行CF指令1。
- Vertex Fetch Clause,CF的指令0指明程序会从第指令4处开始执行,指令4和指令5构成一个Vertex Fetch Clause,两条指令一起完成取顶点数据,这里是要进行Copy操作,顶点数据包括顶点的位置坐标和纹理坐标。由于是2D操作,因此这里的坐标的有效分量只有两个。 指令4的VTX_INST位表明改指令是一条取数据的指令,从BUFFER_ID为0 的内存处取顶点(FETCH_TYPE)数据,SRC_GPR为索引号所在的源寄存器位置,一次取的数据量为16字节(一个四元向量的大小),取出来的数据被放置在编号为1的寄存器中(DST_GPR),DST_SEL_X(SQ_SEL_X)表明取出来的向量的X分量放置到目的寄存器第一个DWORD位置处,Y分量放置到第二个DWORD(DST_SEL_Y(SQ_SEL_Y)),目的寄存器的第三个DWORD 处被置为0,第四个DWORD 处被置为1(可以使用0,1或者0.5)。指令5和指令4类似,由于所有顶点属性数据已经取完,因此原来存在于GPR0 的地址不再需要,可以覆盖掉。图4。
- CF指令1和指令2,这是两条输出指令,指令所做的工作如图5示,指令1用于输出顶点的位置坐标(TYPE(SQ_EXPORT_POS)),这条指令从GPR1(RW_GPR(1))中读取数据,将数据输出到Position Buffer 0 中(ARRAY_BASE(CF_POS0))。输出的时候还有一个Swizzle操作,这条指令的Swizzle操作没有变换向量各个分量。指令1的END_OF_PROGRAM标志表明程序还没有结束,因此继续执行指令2,指令2的END_OF_PROGRAM位表明程序至此结束(后面如果还写有指令将不会被执行)。
4 Pixel Shader示例
/* copy ps --------------------------------------- */
int R600_copy_ps(RADEONChipFamily ChipSet, uint32_t* shader)
{
int i=0;
/* CF INST 指令 0 */
shader[i++] = CF_DWORD0(ADDR(2));
shader[i++] = CF_DWORD1(POP_COUNT(0), CF_CONST(0), COND(SQ_CF_COND_ACTIVE), I_COUNT(1),
CALL_COUNT(0), END_OF_PROGRAM(0), VALID_PIXEL_MODE(0), CF_INST(SQ_CF_INST_TEX),
WHOLE_QUAD_MODE(0), BARRIER(1));
/* CF INST 指令 1 */
shader[i++] = CF_ALLOC_IMP_EXP_DWORD0(ARRAY_BASE(CF_PIXEL_MRT0), TYPE(SQ_EXPORT_PIXEL), RW_GPR(0),
RW_REL(ABSOLUTE), INDEX_GPR(0), ELEM_SIZE(1));
shader[i++] = CF_ALLOC_IMP_EXP_DWORD1_SWIZ(SRC_SEL_X(SQ_SEL_X), SRC_SEL_Y(SQ_SEL_Y),
SRC_SEL_Z(SQ_SEL_Z), SRC_SEL_W(SQ_SEL_W), R6xx_ELEM_LOOP(0), BURST_COUNT(1),
END_OF_PROGRAM(1), VALID_PIXEL_MODE(0), CF_INST(SQ_CF_INST_EXPORT_DONE),
WHOLE_QUAD_MODE(0), BARRIER(1));
/* TEX INST 指令 2 */
shader[i++] = TEX_DWORD0(TEX_INST(SQ_TEX_INST_SAMPLE), BC_FRAC_MODE(0), FETCH_WHOLE_QUAD(0),
RESOURCE_ID(0), SRC_GPR(0), SRC_REL(ABSOLUTE), R7xx_ALT_CONST(0));
shader[i++] = TEX_DWORD1(DST_GPR(0), DST_REL(ABSOLUTE), DST_SEL_X(SQ_SEL_X), /* R */
DST_SEL_Y(SQ_SEL_Y), /* G */
DST_SEL_Z(SQ_SEL_Z), /* B */
DST_SEL_W(SQ_SEL_W), /* A */
LOD_BIAS(0),
COORD_TYPE_X(TEX_UNNORMALIZED), COORD_TYPE_Y(TEX_UNNORMALIZED),
COORD_TYPE_Z(TEX_UNNORMALIZED), COORD_TYPE_W(TEX_UNNORMALIZED));
shader[i++] = TEX_DWORD2(OFFSET_X(0), OFFSET_Y(0), OFFSET_Z(0), SAMPLER_ID(0), SRC_SEL_X(SQ_SEL_X),
SRC_SEL_Y(SQ_SEL_Y), SRC_SEL_Z(SQ_SEL_0), SRC_SEL_W(SQ_SEL_1));
shader[i++] = TEX_DWORD_PAD;
return i;
}
这里总共三条指令,其中CF指令0和CF指令1是两条CF指令,TEX指令2是一条取纹理的指令。
指令0表明程序将从addr为2的指令2处开始执行,指令2是一条texture fetch 指令,这条指令根据GPR0中给出的纹理坐标(SRC_GPR(0),根据前面semantic的配置,被插值的纹理坐标存放在GPR0中)从id号为0的纹理资源中取出纹理值,放入到GPR0中(DST_GPR(0x0))。
取纹理操作完成后,执行指令1,指令1是一条输出指令,将取到的纹理直接放到Render target 0(ARRAY_BASE(CF_PIXEL_MRT0))上去。
R600显卡的指令远不止以上这些,读者在理解上面的内容之后,阅读R600指令集手册将不会有太大困难,感兴趣的可以深入进去了解更多的指令。
【原创】Linux环境下的图形系统和AMD R600显卡编程(11)——R600指令集的更多相关文章
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(1)——Linux环境下的图形系统简介
Linux/Unix环境下最早的图形系统是Xorg图形系统,Xorg图形系统通过扩展的方式以适应显卡和桌面图形发展的需要,然而随着软硬件的发展,特别是嵌入式系统的发展,Xorg显得庞大而落后.开源社区 ...
- Linux环境下的图形系统和AMD R600显卡编程(1)——Linux环境下的图形系统简介
转:https://www.cnblogs.com/shoemaker/p/linux_graphics01.html Linux/Unix环境下最早的图形系统是Xorg图形系统,Xorg图形系统通过 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(2)——Framebuffer、DRM、EXA和Mesa简介【转】
转自:http://www.cnblogs.com/shoemaker/p/linux_graphics02.html 1. Framebuffer Framebuffer驱动提供基本的显示,fram ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(6)——AMD显卡GPU命令格式
前面一篇blog里面描述了命令环缓冲区机制,在命令环机制下,驱动写入PM4(不知道为何会取这样一个名字)包格式的命令对显卡进行配置.这一篇blog将详细介绍命令包的格式. 当前定义了4中命令包,分别是 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(5)——AMD显卡显命令处理机制
通常通过读写设备寄存器对设备进行编程,在X86系统上,有专门的IO指令进行编程,在其他诸如MIPS.SPARC这类系统上,通过将设备的寄存器映射到内存地址空间直接使用读写内存的方式对设备进行编程. R ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(3)——AMD显卡简介
早期的显卡仅用于显示,后来显卡中加入了2D加速部件,这些部件用于做拷屏,画点,画线等操作.随着游戏.三维模拟以及科学计算可视化等需要,对3D的需求逐渐增加,早期图形绘制工作由CPU来完成,要达到真实感 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(10)——R600显卡的3D引擎编程
3D图形处理流水线需要流经多个硬件单元才能得到最后的渲染结果,流水线上的所有的硬件单元必须被正确编程,才能得到正确的结果. 总体上看,从图形处理流水线的源头开始,需要准备好vertex和index,在 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(7)——AMD显卡的软件中断
CPU上处理的中断可以分成“硬件中断”和“软件中断”两类,比如网卡产生的中断称为硬件中断,而如果是软件使用诸如"int 0x10"(X86平台上)这样的指令产生中断称为软件中断,硬 ...
- 【原创】Linux环境下的图形系统和AMD R600显卡编程(4)——AMD显卡显存管理机制
显卡使用的内存分为两部分,一部分是显卡自带的显存称为VRAM内存,另外一部分是系统主存称为GTT内存(graphics translation table和后面的GART含义相同,都是指显卡的页表,G ...
- Linux环境下的图形系统和AMD R600显卡编程(2)——Framebuffer、DRM、EXA和Mesa简介
转:https://www.cnblogs.com/shoemaker/p/linux_graphics02.html 1. Framebuffer Framebuffer驱动提供基本的显示,fram ...
随机推荐
- Android开发——View滑动的三种实现方式
0. 前言 Android开发中,我们常常需要View滑动实现一些绚丽的效果来优化用户体验.一般View的滑动可以用三种方式实现. 转载请注明出处:http://blog.csdn.net/seu ...
- html+css调用服务器端字体
在浏览网页时,由于客户端没有安装某些特殊字体,导致网页文字无法按设计正常显示,这时我们可以使用服务器字体来避免这种现象的发送 语法 @font-face { /* 自定义字体名称 */ font-fa ...
- 1 Mongodb安装
1.NoSQL简介 NoSQL,全名Not Only SQL,指的是非关系型的数据库 随着访问量的上升,网站的数据库性能出现了问题,于是NoSQL被设计出来了 优点.缺点 优点 高扩展性 分布式计算 ...
- jQuery的.on方法
jQuery on()方法是官方推荐的绑定事件的一个方法. $(selector).on(event,childSelector,data,function,map)由此扩展开来的几个以前常见的方法有 ...
- 怎么将oracle的sql文件转换成mysql的sql文件-- 费元星
http://jingyan.baidu.com/article/ca41422fe01f251eaf99ed6e.html
- 《Cracking the Coding Interview》——第3章:栈和队列——题目3
2014-03-18 05:17 题目:设计一个栈,这个栈实际上由一列子栈组成.每当一个子栈的大小达到n,就新产生下一个子栈.整个栈群对外看起来就像普通栈一样,支持取顶top().压入push().弹 ...
- 一个初学者的辛酸路程-基于Django写BBS项目
前言 基于Django的学习 详情 登录界面 找个模板 http://v3.bootcss.com/examples/signin/ 右键,检查源码 函数 def login(request) ...
- 【转载】Unity插件研究院之自动保存场景
原文: http://wiki.unity3d.com/index.php?title=AutoSave 最近发现Unity老有自动崩溃的BUG. 每次崩溃的时候由于项目没有保存所以Hierarch ...
- Python全栈工程师(while、占位符)
ParisGabriel Python 入门基础 UnicodeASCII 用8个位表示文字 ,最高位一定是零,低七位表示数值Unicode是由16个位组成的(65535) 最 ...
- sdram之乒乓操作
在实时显示时,为了保证画面显示的完整性需要对SDRAM进行乒乓操作. SDRAM 中有 4 个bank ,地址分别为00 01 10 11,后面将用 0 1 2 3来描述 bank 0和1 作为第一个 ...