render tree与css解析
浏览器在构造DOM树的同时也在构造着另一棵树-Render Tree,与DOM树相对应暂且叫它Render树吧,我们知道DOM树为javascript提供了一些列的访问接口(DOM API),但这棵树是不对外的。它的主要作用就是把HTML按照一定的布局与样式显示出来,用到了CSS的相关知识。从MVC的角度来说,可以将render树看成是V,dom树看成是M,C则是具体的调度者,比HTMLDocumentParser等。
新概念Render树
每一个Render树的节点称之为renderer或者render object,查看WEBKIT的源代码我们可以发现Renderer一个基础的类定义,这个类是所有renderer对象的基类。

class RenderObject{
virtual void layout();
virtual void paint(PaintInfo);
virtual void rect repaintRect();
Node* node; //the DOM node
RenderStyle* style; // the computed style
RenderLayer* containgLayer; //the containing z-index layer
}
从中我们可以发现renderer包含了一个dom对象以及为其计算好的样式规则,提供了布局以及显示方法。具体效果图如下:(firefox的Frames对应renderers,content对应dom)
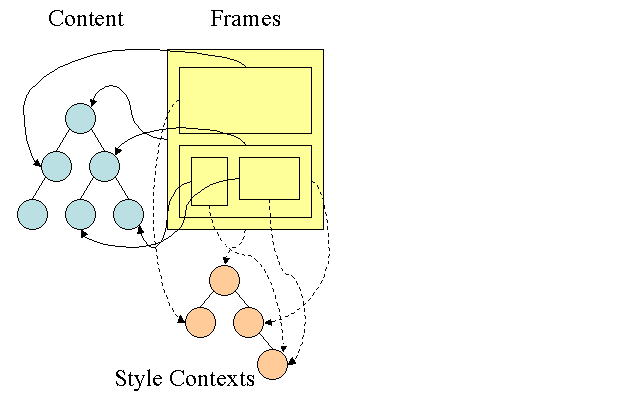
具体显示的时候,每一个renderer体现了一个矩形区块的东西,即我们常说的CSS盒子模型的概念,它本身包含了一些几何学相关的属性,如 宽度width,高度height,位置position等。每一个renderer还有一个很重要的属性,就是如何显示它,display。我们知道元 素的display有很多种,常见的就有none,inline,block,inline-block....,不同的display它们之间到底有啥 不同呢?我们看一下代码:
RenderObject* RenderObject::createObject(Node* node, RenderStyle* style)
{
Document* doc = node->document();
RenderArena* arena = doc->renderArena();
...
RenderObject* o = 0; switch (style->display()) {
case NONE:
break;
case INLINE:
o = new (arena) RenderInline(node);
break;
case BLOCK:
o = new (arena) RenderBlock(node);
break;
case INLINE_BLOCK:
o = new (arena) RenderBlock(node);
break;
case LIST_ITEM:
o = new (arena) RenderListItem(node);
break;
...
} return o;
}
更详细的可见WEBKIT源码了,上面只是列出了片段。
DOM树与Render树
可以这么说,没有DOM树就没有Render树,但是它们之间可不是简单的一对一的关系。我们已经知道了 render树是用于显示的,那不可见的元素当然不会在这棵树中出现了,譬如<header>,您还能想到哪些呢?除此之外,diplay等 于none的也不会被显示在这棵树里头,但是visibility等于hidden的元素是会显示在这棵树里头的,可以自己想一下为什么。说了这么多 render树,我们还没见一下它的真容呢,它到底会是个什么模样呢?我们看一下图。
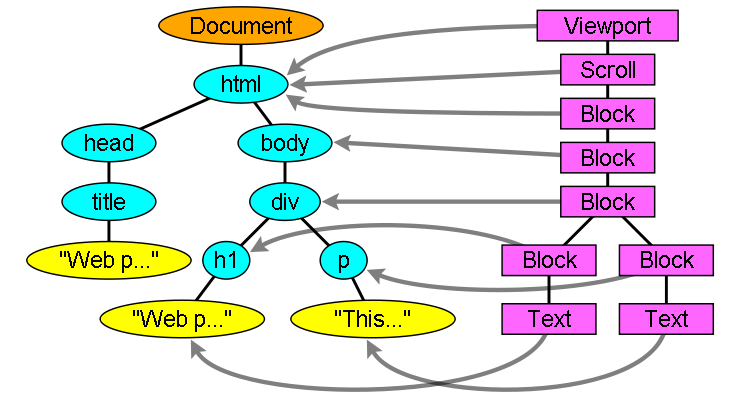
与DOM对象类型很丰富啊,什么head,title,div,而Render树相对来说就比较单一了,毕竟它的职责就是为了以后的显示渲染用 嘛。从上图我们还可以看出,有些DOM元素没有对应的renderer,而有些DOM元素却对应了好几个renderer,对应多个renderer的情 况是普遍存在的,就是为了解决一个renderer描述不清楚如何显示出来的问题,譬如select元素,我们就需要三个renderer,one for the display area, one for the drop down list box and one for the button。
上图中还有一种关系未可看出,即renderer与dom元素的位置也可能是不一样的。说的就是那些添加了float:ETC或者position:absolute的元素,因为它们脱离了正常的文档流顺序,构造Render树的时候会针对它们实际的位置进行构造。
DOM树可能会被我们随时更新,不仅限于解析阶段,譬如$elment.append啦或 者$elment.addClass啦,我们看到页面立即进行了显示刷新,浏览器针对这种情况进行了相关处理。Dom树的根节点我们知道是 doument,Render树的根节点不同浏览器可能有不同的叫法,webkit叫它RenderView,firefox叫它ViewPortFrame。
CSS的解析
CSS用到的所有词汇定义规范如下:
comment \/\*[^*]*\*+([^/*][^*]*\*+)*\/ num [0-9]+|[0-9]*"."[0-9]+ nonascii [\200-\377] nmstart [_a-z]|{nonascii}|{escape} nmchar [_a-z0-9-]|{nonascii}|{escape} name {nmchar}+ ident {nmstart}{nmchar}* |
注:ident代表样式中的class,name代表样式中的id。
CSS用到的语法BNF格式的定义如下:
ruleset : selector [ ',' S* selector ]* '{' S* declaration [ ';' S* declaration ]* '}' S* ; selector : simple_selector [ combinator selector | S+ [ combinator selector ] ] ; simple_selector : element_name [ HASH | class | attrib | pseudo ]* | [ HASH | class | attrib | pseudo ]+ ; class : '.' IDENT ; element_name : IDENT | '*' ; attrib : '[' S* IDENT S* [ [ '=' | INCLUDES | DASHMATCH ] S* [ IDENT | STRING ] S* ] ']' ; pseudo : ':' [ IDENT | FUNCTION S* [IDENT S*] ')' ] ; |
样式计算
每个HTML元素上,我们可能定义了很多不同类型的样式,如字体啦,颜色啦,布局啦等等。即使元素上不被我们定义样式,浏览器或者用户个性设置也会为它默认创造一些样式。
样式计算一项极其复杂的过程,我们定义样式的时候可以采用类似类的定义方式为一批元素设置样式,但是解析构造renderer的时候,浏览器是 为每一个构造样式定义的。我们可能定义了极其多的样式而且有各种不同的规则,那找到元素匹配的样式规则是挺困难的。浏览器有多重算法错误来实现计算工作, 具体就不细分析了,一个元素最终经过计算可能匹配到了很多条样式规则,他们之间存在一定的优先顺序,从低到高有:
- 浏览器默认样式
- 用户个性化浏览器设置
- HTML开发者定义的一般样式
- HTML开发者定义的!important样式
- 用户个性化浏览器设置!important样式
更详细的优先计算公式
- count 1 if the declaration is from is a 'style' attribute rather than a rule with a selector, 0 otherwise (= a)
- count the number of ID attributes in the selector (= b)
- count the number of other attributes and pseudo-classes in the selector (= c)
- count the number of element names and pseudo-elements in the selector (= d)
具体可见http://www.w3.org/TR/CSS2/cascade.html#specificity
举例说明
* {} /* a=0 b=0 c=0 d=0 -> specificity = 0,0,0,0 */
li {} /* a=0 b=0 c=0 d=1 -> specificity = 0,0,0,1 */
li:first-line {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul li {} /* a=0 b=0 c=0 d=2 -> specificity = 0,0,0,2 */
ul ol+li {} /* a=0 b=0 c=0 d=3 -> specificity = 0,0,0,3 */
h1 + *[rel=up]{} /* a=0 b=0 c=1 d=1 -> specificity = 0,0,1,1 */
ul ol li.red {} /* a=0 b=0 c=1 d=3 -> specificity = 0,0,1,3 */
li.red.level {} /* a=0 b=0 c=2 d=1 -> specificity = 0,0,2,1 */
#x34y {} /* a=0 b=1 c=0 d=0 -> specificity = 0,1,0,0 */
style="" /* a=1 b=0 c=0 d=0 -> specificity = 1,0,0,0 */
布局
上面确定了renderer的样式规则后,然后就是重要的显示因素布局了。当renderer构造出来并添加到render树上之后,它并没有位置跟大小信息,为它确定这些信息的过程,我们就称之为布局。HTML采用了一种流式布局的布局模型,从上到下,从左到右顺序布局,布局的起点是从render树的根节点开始的,对应dom树的document节点,其初始位置为0,0,详细的布局过程为: 每个renderer的宽度由父节点的renderer确定。 父节点遍历子节点,确定子节点的位置(x,y),调用子节点的layout方法确定其高度。 父节点根据子节点的height,margin,padding确定自身的自身的高度。
为了避免因为局部小范围的DOM修改或者样式改变引起整个页面整体的布局重新构造,浏览器采用了一种dirty bit system的技术,使其尽可能的只改变元素本身或者包含的子元素的布局。当然有些情况无可避免的要重新构造整个页面的布局,如适合于整体的样式的改变影响了所有renderer,如body{font-size:111px} 字体大小发生了改变,还有一种情况就是浏览器窗口进行了调整,resize。
对于界面设计来说,一个页面最难搞的应该就是排版布局了,内容也比较多,我们下文进行说明
From:http://www.cnblogs.com/luluping/archive/2013/04/05/3000460.html
render tree与css解析的更多相关文章
- 渲染树render tree
CSSOM树和DOM树连接在一起形成一个render tree,渲染树用来计算可见元素的布局并且作为将像素渲染到屏幕上的过程的输入. DOM树和CSSOM树连接在一起形成render tree . r ...
- 浏览器-05 HTML和CSS解析1
一个浏览器内核几个主要部分,HTML/CSS解析器,网络处理,JavaScript引擎,2D/3D图形引擎,多媒体支持等; HTML 解析和 DOM 网页基本结构 一个网页(Page),每个Page都 ...
- IE6常见CSS解析Bug及hack
IE6常见CSS兼容问题总结 1)图片间隙 A)div中的图片间隙(该bug出现在IE6及更低版本中) 描述:在div中插入图片时,图片会将div下方撑大三像素. hack1:将</div> ...
- ASP.NET重写Render 加载CSS样式文件和JS文件(切换CSS换皮肤)
网页换皮肤的方式有很多种,最简单的通常就是切换页面CSS,而CSS通常写在外部CSS文件里.那么切换CSS其实就是更换html里的link href路径.我在网上搜索了下. 一般有两种方式: 1.页面 ...
- css解析规则
1.因为css对空格不敏感,因此在每个样式后都要加一个分号,不然会把写在后面的样式当成一个整体来解析,直到遇到分号为止. 2.当遇见不认识的属性或值时,将忽略这个属性,继续解析后面的属性. 3.对于复 ...
- 浏览器-06 HTML和CSS解析2
选择器 其实现由CSSSelector类来完成: CSSSelector的作用是储存从解析器生成的结果信息; 这里匹配指的是当需要为每个DOM中的节点计算样式时,WebKit需要根据当前的节点信息来从 ...
- nginx配置 send_timeout 引发的js、css解析失败问题
错误情况是web界面排版错误,js.css文件加载失败,通过调试器查看js和css文件路径都是对的,而且可访问. 业务使用的是 nginx+php+mysql+redis的架构 解决办法: 查了很多资 ...
- 网站怎么布局能解决不同浏览器对CSS解析的差异,使用css reset
很多地方都提到过CSS Reset这个概念,而且细心的朋友会发现,许多大网站的CSS文件中也含有CSS Reset内容. CSS Reset是什么? 在HTML标签在浏览器里有默认的样式,例如 p 标 ...
- IE6常见CSS解析Bug和hack
第一:图片间隙 a:div中的图片间隙: 描述:在div中插入图片时,图片会将div下方撑大3像素 hack1:将<div>和<img>写在一行 hack2:将<img& ...
随机推荐
- Explain分析查询语句
表的读取顺序 读取操作的类型 可用索引,实际使用的索引 表之间的引用 每张表多少行被优化器查询 索引的长度 EXPLAIN字段解释: ØTable:显示这一行的数据是关于哪张表的 Øpossible ...
- jsonp: js跨域
JSONP是JSON with padding(填充式JSON或参数式JSON)的简写,是应用JSON的一种新方法,常用于服务器与客户端跨源通信,在后来的Web服务中非常流行.本文将详细介绍JSONP ...
- 使用memcache 心得和注意事项
内存分配机制:首先要说明的是Memcached支持最大的存储对象为1M.它的内存分配比较特殊,但是这样的分配方式其实也是对于性能考虑的,简单的分配机制可以更容易回收再分配,节省对于CPU的使用.这里用 ...
- 《Advanced Bash-scripting Guide》学习(八):从一个目录移动整个目录树到另一个目录
本文所选的例子来自于<Advanced Bash-scripting Gudie>一书,译者 杨春敏 黄毅 ABS书上的例子: 从一个目录移动整个目录树到另一个目录 #!/bin/bash ...
- Mac的搜狗输入法和QQ输入法加入⌘⌥⌃⇧自定义短语
搜狗输入法(Mac):http://pinyin.sogou.com/mac/ 创建名为『搜狗输入法自定义短语.ini』的文本文件(建议用Sublime Text),内容如下,然后偏好设置的自定义短语 ...
- 51nod 1625 贪心/思维
http://www.51nod.com/onlineJudge/questionCode.html#!problemId=1625 1625 夹克爷发红包 基准时间限制:1 秒 空间限制:13107 ...
- Python - 批量改变文件名
import osimport sysimport datetime path = "E:\python_test"datename = '2016-02-11'a = datet ...
- python 生成唯一字符串UUID与MD5
1 Python使用UUID库生成唯一ID UUID是128位的全局唯一标识符,通常由32字节的字符串表示,保证时间和空间的唯一性 通过MAC地址.时间戳.命名空间.随机数.伪随机数来保证生成ID的唯 ...
- UVA - 1343 The Rotation Game (BFS/IDA*)
题目链接 紫书例题. 首先附上我第一次bfs+剪枝TLE的版本: #include<bits/stdc++.h> using namespace std; typedef long lon ...
- C#进阶之路(三):深拷贝和浅拷贝
一.前言 本文主要讨论深浅拷贝的区别,如果实现.浅拷贝日常的应用比较懂,这里不做深入讨论,那么深拷贝如何实现?目前我知道的方式有三种:反射,反序列化和表达树的方式.这里需要注意如果用反射来实现深拷贝的 ...