sqlserver的索引创建
随着系统数据的增多,一些查询逐渐变慢,这时候我们可以根据sqlserver的执行计划,查看sql的开销,然后根据开销创建索引。
索引有聚集索引与非聚集索引。
聚集索引:聚集索引在存储上是按照顺序存储的,就像字典里的汉字。
非聚集索引:物理存储不连续,但逻辑上是连续的,因为单独维护着数据的存储位置与数据的关系。
首先写入100000数据
DECLARE @i INT,
@num int
SET @i=0
SET @num=100000
WHILE @i<=@num
BEGIN
IF NOT EXISTS(SELECT * FROM dbo.meter_manage WHERE meter_id=@i)
INSERT INTO dbo.meter_manage
( meter_id ,
meter_no ,
meter_name
)
VALUES
( @i , -- meter_id - int
'asdasd'+CONVERT(VARCHAR(20),@i), -- meter_no - varchar(500)
'asdsf'++CONVERT(VARCHAR(20),@i) -- meter_name - varchar(500)
);
SET @i=@i+1;
END
go
非聚集索引的创建:
create NONCLUSTERED INDEX index1 ON meter_manage(meter_no)
效果:
select * from meter_manage where meter_no='asdasd2'
创建非聚集索引之前,耗时23毫秒左右

创建非聚集索引之后,瞬间完成

经常使用多条件语句查询时,我们可创建复合索引。
select * from meter_manage where meter_no='asdasd2' and meter_name='asdsf2'
未创建非聚集索引,耗时30毫秒:

在meter_no字段创建单索引,耗时3毫秒:
create NONCLUSTERED INDEX index1 ON meter_manage(meter_no)

条件查询位置更换:
select * from meter_manage where meter_name='asdsf2' and meter_no='asdasd2'

查询速度没变,同样3毫秒。
我们同时在另一个字段meter_name上也建立一个非聚集索引:
create NONCLUSTERED INDEX index2 ON meter_manage(meter_name)

发现两个非聚集索引的时间与一个聚集索引的时间没有太大变化,查看执行计划,只命中了index1索引:
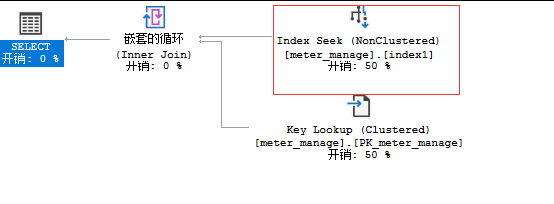
分析:
我们来想象一下当数据库有N个索引并且查询中分别都要用上他们的情况:
查询优化器(用大白话说就是生成执行计划的那个东西)需要进行N次主二叉树查找[这里主二叉树的意思是最外层的索引节点],此处的查找流程大概如下:
查出第一条column1主二叉树等于1的值,然后去第二条column2主二叉树查出foo的值并且当前行的coumn1必须等于1,最后去column主二叉树查找bar的值并且column1必须等于1和column2必须等于foo。
如果这样的流程被查询优化器执行一遍,就算不死也半条命了,查询优化器可等不及把以上计划都执行一遍,贪婪算法(最近邻居算法)可不允许这种情况的发生,所以当遇到以下语句的时候,数据库只要用到第一个筛选列的索引(column1),就会直接去进行表扫描了。
select count(1) from table1 where column1 = 1 and column2 = 'foo' and column3 = 'bar'
所以与其说是数据库只支持一条查询语句只使用一个索引,倒不如说N条独立索引同时在一条语句使用的消耗比只使用一个索引还要慢。
所以如上条的情况,最佳推荐是使用index(column1,column2,column3) 这种联合索引,此联合索引可以把b+tree结构的优势发挥得淋漓尽致:
一条主二叉树(column=1),查询到column=1节点后基于当前节点进行二级二叉树column2=foo的查询,在二级二叉树查询到column2=foo后,去三级二叉树column3=bar查找。
结论:两个单独索引通常数据库只能使用其中一个
创建复合索引:
create index idx1 on meter_manage(meter_no,meter_name)

瞬间完成,发现多条件下适合创建复合索引。
条件位置改变一下
select * from meter_manage where meter_name='asdsf2' and meter_no='asdasd2'

同样瞬间完成。查看执行计划命中了idx1
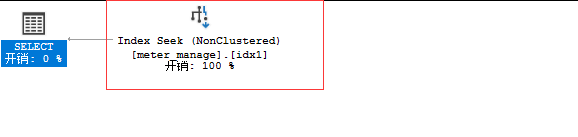
我们去掉二个条件:
select * from meter_manage where meter_no='asdasd2'

同样瞬间完成,也命中了索引 idx1

我们去掉第一个条件:
select * from meter_manage where meter_name='asdsf2'

耗时27毫秒,与不加索引没什么区别,查看执行计划,发现虽然命中了idx1
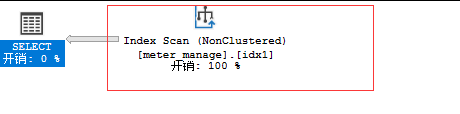
但是类型却是Index Scan,与之前的Index Seek不同
区别:
[Table Scan] 表扫描(最慢),对表记录逐行进行检查
[Clustered Index Scan] 聚集索引扫描(较慢),按聚集索引对记录逐行进行检查
[Index Scan] 索引扫描(普通),根据索引滤出部分数据在进行逐行检查
[Index Seek] 索引查找(较快),根据索引定位记录所在位置再取出记录
[Clustered Index Seek] 聚集索引查找(最快),直接根据聚集索引获取记录
因此,字段上同时存在聚集索引与非聚集索引,这种情况下只会命中聚集索引,因为聚集索引最快,例如:主键上创建非聚集索引
create NONCLUSTERED INDEX index3 ON meter_manage(meter_id)

瞬间完成,执行计划:

sqlserver的索引创建的更多相关文章
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(下)
SQLSERVER聚集索引与非聚集索引的再次研究(下) 上篇主要说了聚集索引和简单介绍了一下非聚集索引,相信大家一定对聚集索引和非聚集索引开始有一点了解了. 这篇文章只是作为参考,里面的观点不一定正确 ...
- SQLServer覆盖索引
为了更好地理解覆盖索引,在正式介绍覆盖索引之前,首先稍微来谈一谈有关索引的一些基础知识. 数据页和索引页 在SQLServer中,数据存储的基本单位是页,一页的大小为8KB,分别由页首,数据行和行偏移 ...
- 索引-mysql索引创建、查看、删除及使用示例
mysql索引创建.查看.删除及使用示例 1.创建索引: ALTER TABLE用来创建普通索引.UNIQUE索引或PRIMARY KEY索引. ALTER TABLE table_name ADD ...
- SqlServer 使用脚本创建分发服务及事务复制的可更新订阅
原文:SqlServer 使用脚本创建分发服务及事务复制的可更新订阅 [创建使用本地分发服务器] /************************[使用本地分发服务器配置发布]*********** ...
- sqlserver 数据库索引建立原则
1.始终包含聚集索引 当表中不包含聚集索引时,表中的数据是无序的,这会降低数据检索效率.即使通过索引缩小了数据检索的范围,但由于数据本身是无序的,当从表中提取实际数据时,会产生频繁的定位问题,这也使得 ...
- mysql 优化实例之索引创建
mysql 优化实例之索引创建 优化前: pt-query-degist分析结果: # Query 23: 0.00 QPS, 0.00x concurrency, ID 0x78761E301CC7 ...
- MongoDB索引创建(5)
索引创建 1:索引提高查询速度,降低写入速度,权衡常用的查询字段,不必在太多列上建索引 2. 在mongodb中,索引可以按字段升序/降序来创建,便于排序 3. 默认是用btree来组织索引文件,2. ...
- Lucene7.1.0版本的索引创建与查询以及维护,包括新版本的一些新特性探索!
一 吐槽 lucene版本更新实在太快了,往往旧版本都还没学会,新的就出来,而且每个版本改动都特别大,尤其是4.7,6,6,7.1.......ε=(´ο`*)))唉,但不可否认,新版本确实要比旧版本 ...
随机推荐
- linux 内核的链表操作(好文不得不转)
以下全部来自于http://www.ibm.com/developerworks/cn/linux/kernel/l-chain/index.html 无任何个人意见. 本文详细分析了 2.6.x 内 ...
- secret CRT 会话光标不闪烁问题
点击 选项->会话选项 然后在取消即可,就有了闪烁的光标,应该是个bug.
- 关于一种fastjson的死循环情况记录
最近在一次项目中,使用fastjson做接口转换中,碰到了一个Stack Overflow.发现在getxxx方法内如果再次嵌套使用fastjson作json转换,就会无限循环. 错误实例: clas ...
- WPF案例:如何设计搜索框(自定义控件的原则和方法)
我们平时自定义WPF控件的方法有:Style,DataTemplate,ControlTemplate, DependencyProperty, CustomControl等几个方法. 按照优先顺序应 ...
- bootstrap 多色表格
有时候需要用到多色显示不同类型的表格 用bootstrap的样式即可 <tr class="active"> <tr class="success&qu ...
- Java类与继承
Java:类与继承 对于面向对象的程序设计语言来说,类毫无疑问是其最重要的基础.抽象.封装.继承.多态这四大特性都离不开类,只有存在类,才能体现面向对象编程的特点,今天我们就来了解一些类与继承的相 ...
- __thiscalll C++底层识别成员函数
问题描述: class myClass { public: void SetNumber(int nNumber) { m_nInt = nNumber; } private: int m_nInt; ...
- Spring学习十一
一: 创建bean的方法: 1: 如果不采用构造注入:默认调用bean的无参构造函数,因此该类必须要提供无参构造函数,用无参构造函数用反射创建bean. : 如果采用构造 ...
- VMware:Configuration file was created by a VMware product with more features than this version
Few days ago,I opened the Genesys demo VM by VMware Server 1.0.4 and got an error like this: "C ...
- 关于win7 下双击不能打开jar 文件
关于这个问题解决如下: 我的java 安装路径为C:\java\jdk1.6\bin 1,首先检查jdk 的路径是否安装正确. 2,导出jar 包时,是否有添加 main class. 如果通过在do ...