java集合框架1
1、综述
所有集合类都位于java.util包下。集合中只能保存对象(保存对象的引用变量)。(数组既可以保存基本类型的数据也可以保存对象)。
当我们把一个对象放入集合中后,系统会把所有集合元素都当成Object类的实例进行处理。从JDK1.5以后,这种状态得到了改进:可以使用泛型来限制集合里元素的类型,并让集合记住所有集合元素的类型(参见具体泛型的内容)。
Java的集合类主要由两个接口派生而出:Collection和Map,Collection和Map是Java集合框架的根接口,这两个接口又包含了一些接口或实现类。
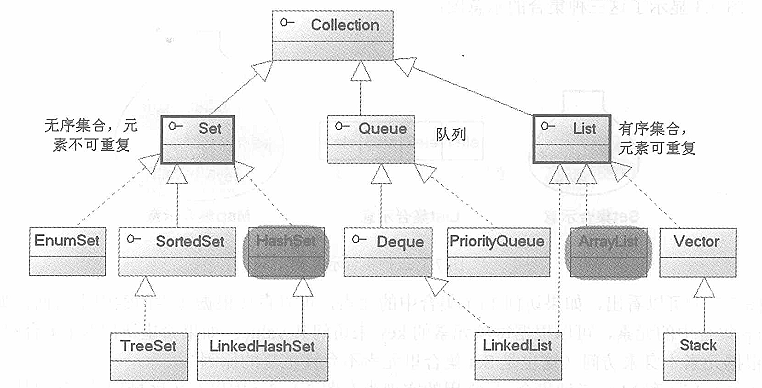
Set和List接口是Collection接口派生的两个子接口,Queue是Java提供的队列实现,类似于List。
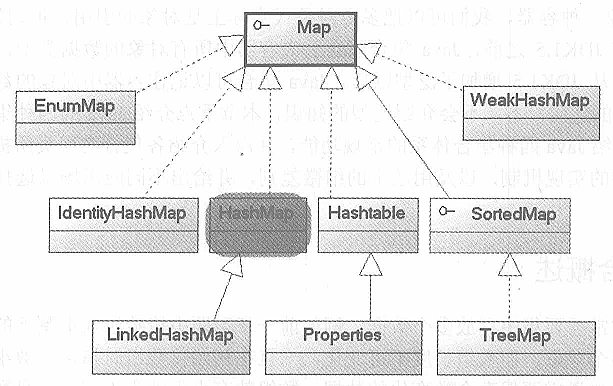
Map实现类用于保存具有映射关系的数据(key-value)。
Set、List和Map可以看做集合的三大类。
List集合是有序集合,集合中的元素可以重复,访问集合中的元素可以根据元素的索引来访问。
Set集合是无序集合,集合中的元素不可以重复,访问集合中的元素只能根据元素本身来访问(也是集合里元素不允许重复的原因)。
Map集合中保存Key-value对形式的元素,访问时只能根据每项元素的key来访问其value。
对于Set、List和Map三种集合,最常用的实现类分别是HashSet、ArrayList和HashMap三个实现类。
2、Collection接口
Collection接口是List、Set和Queue接口的父接口,同时可以操作这三个接口。
Collection接口定义操作集合元素的具体方法大家可以参考API文档,Collection 是任何对象组,元素各自独立,通常拥有相同的套用规则。
基本操:
增加元素add(Object obj); addAll(Collection c);
删除元素 remove(Object obj); removeAll(Collection c);
求交集 retainAll(Collection c);
删除元素 remove(Object obj); removeAll(Collection c);
求交集 retainAll(Collection c);
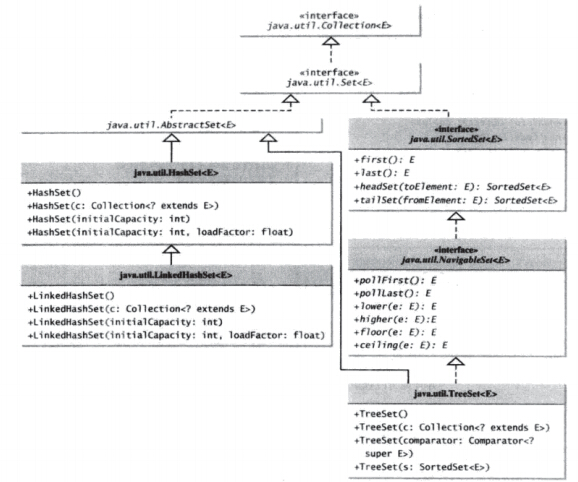
Set接口的三个具体类是:
HashSet--基于散列表的集,加进散列表的元素要实现hashCode()方法
LinkedHashSet--对集迭代时,按增加顺序返回元素
TreeSet--基于(平衡)树的数据结构
散列集HashSet
1. 继承结构
java.lang.Object
|_ java.util.AbstractCollection<E>
|_ java.util.AbstractSet<E>
|_ java.util.HashSet<E>
2. 主要方法
add(Object)
addAll(Collection)
remove(object)
removeAll(Collection)
size()
iterator()
toArray()
clear()
isEmpty()
contain(object)
containAll(Collection)
Set集合中不允许出现相同的项,Set集合在用Add()方法添加一个新项时,首先会调用equals(Object o)来比较新项和已有的某项是否相等,而不是用==来判断相等性,所以对于字符串等已重写equals方法的类,是按值来比较相等性的
下面的程序创建了一个散列集来存储字符串,并且使用一个迭代器来遍历这个规则集中的元素:
public class Main
{
public static void main(String args[]) {
Set<String> set = new HashSet<String>();
set.add("London");
set.add("Paris");
set.add("New York");
set.add("New York");
set.add("Beijing");
set.add("Guangzhou");
System.out.println(set); Iterator<String> iterator = set.iterator();
while(iterator.hasNext()) {
System.out.print(iterator.next().toUpperCase() + " ");
}
}
}
注意:字符串没有按照顺序存储,因为散列集中的元素是没有特定的顺序的
当然也可以不使用迭代器,而用for-each循环来简化上面的迭代代码:
for(Object i: set)
System.out.print(i);
由于一个规则集是Collection的一个实例,所有定义在Collection中的方法都可以用在规则集上,下面的代码就是一个例子:
public class Main
{
public static void main(String args[]) {
Set<String> set1 = new HashSet<String>(); set1.add("London");
set1.add("Paris");
set1.add("New York");
set1.add("San Francisco");
set1.add("Beijing");
set1.add("Guangzhou"); System.out.println(set1);
System.out.println(set1.size() + "elements in set1"); set1.remove("London");
System.out.println("\nset1 is " + set1);
System.out.println(set1.size() + " elements in set1"); Set<String> set2 = new HashSet<String>();
set2.add("London");
set2.add("Shanghai");
set2.add("Paris"); System.out.println("\nset2 is " + set2);
System.out.println(set2.size() + " elements in set2"); System.out.println("\nIs Taipei in set2? " + set2.contains("Taipei"));
set1.addAll(set2);
System.out.println("\nafter adding set2 to set1, set1 is " + set1);
set1.removeAll(set2);
System.out.println("After removing set2 from set1, set1 is " + set1);
set1.retainAll(set2); //保留共有的元素
System.out.println("After removing common elements in set2 " + "from set1, set1 is " + set1);
}
}
运行结果如下:
[San Francisco, New York, Guangzhou, Paris, Beijing, London]
6elements in set1
set1 is [San Francisco, New York, Guangzhou, Paris, Beijing]
5 elements in set1
set2 is [Shanghai, Paris, London]
3 elements in set2
Is Taipei in set2? false
after adding set2 to set1, set1 is [San Francisco, New York, Guangzhou, Shanghai, Paris, Beijing, London]
After removing set2 from set1, set1 is [San Francisco, New York, Guangzhou, Beijing]
After removing common elements in set2 from set1, set1 is []
链式散列集--LinkedHashSet
LinkedHashSet,顾名思义,就是在Hash的实现上添加了Linked的支持。对于LinkedHashSet,在每个节点上通过一个链表串联起来,这样,就可以保证确定的顺序。对于希望有常量复杂度的高效存取性能要求、同时又要求排序的情况下,可以直接使用LinkedHashSet。
LinkedHashSet用一个链表实现来扩展HashSet类,它支持对规则集内的元素的排序。HashSet中的元素是没有被排序的它实现了Set接口。存入Set的每个元素必须是唯一的,因为Set不保存重复元素。但是Set接口不保证维护元素的次序。Set与Collection有完全一样的接口Iterable,同时Set继承了Collection。LinkedHashSet具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的顺序),于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
下面是一个测试程序:
public class Main
{
public static void main(String args[]) {
Set<String> set = new LinkedHashSet<String>();
set.add("London");
set.add("Paris");
set.add("New York");
set.add("San Francisco");
set.add("Beijing");
set.add("New York"); System.out.println(set);
for(Object i: set)
System.out.print(i.toString().toLowerCase() + " ");
}
}
如果不需要维护元素被插入的顺序,就应该使用HashSet,它会比LinkedHashSet更加的高效
树形集TreeSet
继承结构:
java.lang.Object
|_ java.util.AbstractCollection<E>
|_ java.util.AbstractSet<E>
|_ java.util.TreeSet<E>
类声明:
public class TreeSet<E>
extends AbstractSet<E>
implements SortedSet<E>, Cloneable, java.io.Serializable //它实现了sortedSet,有排序的功能
TreeSet的主要性质
1、TreeSet中不能有重复的元素;
2、TreeSet具有排序功能;
3、TreeSet中的元素必须实现Comparable接口并重写compareTo()方法,TreeSet判断元素是否重复、以及确定元素的顺序靠的都是这个方法;
4、对于java类库中定义的类,TreeSet可以直接对其进行存储,如String,Integer等(因为这些类已经实现了Comparable接口);
java常用类实现Comparable接口,并提供了比较大小的标准。实现Comparable接口的常用类:
BigDecimal、BigIneger以及所有数值型对应包装类:按它们对应的数值的大小进行比较。
Character:按字符的UNICODE值进行比较。
Boolean:true对应的包装类实例大于false对应的包装类实例。
String:按字符串中字符的UNICODE值进行比较。
Date、Time:后面的时间、日期比前面的时间、日期大。
public class Main
{
public static void main(String args[]) {
Set<String> set = new HashSet<String>();
set.add("London");
set.add("Paris");
set.add("New York");
set.add("San Francisco");
set.add("Beijing");
set.add("New York"); TreeSet<String> treeSet = new TreeSet<String>(set);
System.out.println("Sorted tree set: " + treeSet); //下面的方法在SortedSet接口
System.out.println("first(): " + treeSet.first()); //返回第一个元素
System.out.println("last(): " + treeSet.last()); //返回最后一个元素
System.out.println("headSet(): " + treeSet.headSet("New York")); //返回New York之前的所有元素
System.out.println("tailSet(): " + treeSet.tailSet("New York")); //返回New York 及其之后的所有元素 //使用NavigableSet接口里面的方法
System.out.println("lower(\"p\"): " + treeSet.lower("P")); //返回小于"P"的最大元素
System.out.println("higher(\"p\"): " + treeSet.higher("P")); //返回大于"P"的最小元素
System.out.println("floor(\"p\"): " + treeSet.floor("P")); //返回小于等于"P"的最大元素
System.out.println("ceiling(\"p\"): " + treeSet.ceiling("P")); //返回大于等于"P"的最小元素
System.out.println("pollFirst(\"p\"): " + treeSet.pollFirst()); //删除第一个元素,并返回被删除的元素
System.out.println("pollLast(\"p\"): " + treeSet.pollLast()); //删除最后一个元素,并返回被删除的元素
System.out.println("New tree set: " + treeSet);
}
}
运行结果如下:
Sorted tree set: [Beijing, London, New York, Paris, San Francisco]
first(): Beijing
last(): San Francisco
headSet(): [Beijing, London]
tailSet(): [New York, Paris, San Francisco]
lower("p"): New York
higher("p"): Paris
floor("p"): New York
ceiling("p"): Paris
pollFirst("p"): Beijing
pollLast("p"): San Francisco
New tree set: [London, New York, Paris]
比较器接口Comparator
有时希望将元素插入到一个树集合中,这些元素可能不是java.lang.Comparable的实例,这时可以定义一个比较容器来比较这些元素
Comparetor接口有两个方法:compare和equals
public int compare(Object element1, Object element2);
如果element1小于element2,就返回一个负值,如果大于就返回一个正值,若相等,则返回0;
public boolean equals(Object element);
如果指定对象也是一个比较器,并且与这个比较器具有相同的排序,则返回true
public class Main
{
public static void main(String args[]) {
Person a[] = new Person[4];
a[0] = new Person("zhangsan", 11);
a[1] = new Person("lisi", 23);
a[2] = new Person("wangwu", 33);
a[3] = new Person("wuzhong", 26);
compareName cn = new compareName();
compareAge ca = new compareAge();
for(int i = 0; i < a.length; i++) a[i].print();
System.out.println();
System.out.println("sorting by age:");
Arrays.sort(a, ca);
for(int i = 0; i < a.length; i++) a[i].print();
System.out.println();
System.out.println("sorting by name:");
Arrays.sort(a, cn);
for(int i = 0; i < a.length; i++) a[i].print();
}
} class Person {
public String name;
public int age;
Person(String n, int a) {
name = n;
age = a;
}
public void print() {
System.out.println("Name is " + name + ", Age is " + age);
}
} class compareAge implements Comparator<Person> {
public int compare(Person p1, Person p2) {
if (p1.age > p2.age) return -1;
else if (p1.age < p2.age) return 1;
else return 0;
}
} class compareName implements Comparator<Person> {
public int compare(Person p1, Person p2) {
return p1.name.compareTo(p2.name);
}
}
运行结果:
Name is zhangsan, Age is 11
Name is lisi, Age is 23
Name is wangwu, Age is 33
Name is wuzhong, Age is 26
sorting by age:
Name is wangwu, Age is 33
Name is wuzhong, Age is 26
Name is lisi, Age is 23
Name is zhangsan, Age is 11
sorting by name:
Name is lisi, Age is 23
Name is wangwu, Age is 33
Name is wuzhong, Age is 26
Name is zhangsan, Age is 11
java集合框架1的更多相关文章
- Java集合框架List,Map,Set等全面介绍
Java集合框架的基本接口/类层次结构: java.util.Collection [I]+--java.util.List [I] +--java.util.ArrayList [C] +- ...
- Java集合框架练习-计算表达式的值
最近在看<算法>这本书,正好看到一个计算表达式的问题,于是就打算写一下,也正好熟悉一下Java集合框架的使用,大致测试了一下,没啥问题. import java.util.*; /* * ...
- 【集合框架】Java集合框架综述
一.前言 现笔者打算做关于Java集合框架的教程,具体是打算分析Java源码,因为平时在写程序的过程中用Java集合特别频繁,但是对于里面一些具体的原理还没有进行很好的梳理,所以拟从源码的角度去熟悉梳 ...
- Java 集合框架
Java集合框架大致可以分为五个部分:List列表,Set集合.Map映射.迭代器.工具类 List 接口通常表示一个列表(数组.队列.链表 栈),其中的元素 可以重复 的是:ArrayList 和L ...
- Java集合框架之map
Java集合框架之map. Map的主要实现类有HashMap,LinkedHashMap,TreeMap,等等.具体可参阅API文档. 其中HashMap是无序排序. LinkedHashMap是自 ...
- 22章、Java集合框架习题
1.描述Java集合框架.列出接口.便利抽象类和具体类. Java集合框架支持2种容器:(1) 集合(Collection),存储元素集合 (2)图(Map),存储键值对.
- Java集合框架实现自定义排序
Java集合框架针对不同的数据结构提供了多种排序的方法,虽然很多时候我们可以自己实现排序,比如数组等,但是灵活的使用JDK提供的排序方法,可以提高开发效率,而且通常JDK的实现要比自己造的轮子性能更优 ...
- (转)Java集合框架:HashMap
来源:朱小厮 链接:http://blog.csdn.net/u013256816/article/details/50912762 Java集合框架概述 Java集合框架无论是在工作.学习.面试中都 ...
- Java集合框架
集合框架体系如图所示 Java 集合框架提供了一套性能优良,使用方便的接口和类,java集合框架位于java.util包中, 所以当使用集合框架的时候需要进行导包. Map接口的常用方法 Map接口提 ...
- Java集合框架(常用类) JCF
Java集合框架(常用类) JCF 为了实现某一目的或功能而预先设计好一系列封装好的具有继承关系或实现关系类的接口: 集合的由来: 特点:元素类型可以不同,集合长度可变,空间不固定: 管理集合类和接口 ...
随机推荐
- Android 标题栏封装
自定义命名空间与xml文件:
- cas单点登出
由于项目需求要实现单点登出需要在网上找了N久终于实现单点登出. 使用cas-server-core-3.3.3.jar(CAS Server 3.3.3) 使用cas-client-core-3.1. ...
- cocos2dx开发笔记
1.帧动画:SpriteTest=>SpriteAnimationSplit 2.sourceinsight显示代码行 option->document option->editin ...
- MyBatis学习总结(5)——实现关联表查询
一对一关联 提出需求 根据班级id查询班级信息(带老师的信息) 创建表和数据 创建一张教师表和班级表,假设一个老师负责教一个班,那么老师和班级之间的关系就是一对一的关系. create table t ...
- BCB遍历所有窗体的组件
for(iFormIdx=0; iFormIdx<Screen->FormCount; iFormIdx++) { TForm *pForm = Screen->Forms[iFor ...
- 进程间通信的WM_COPYDATA的使用
http://blog.csdn.net/ao929929fei/article/details/6316174 接收数据的一方 ON_WM_COPYDATA() afx_msg BOOL OnCop ...
- POJ 2947 Widget Factory (高斯消元 判多解 无解 和解集 模7情况)
题目链接 题意: 公司被吞并,老员工几乎全部被炒鱿鱼.一共有n种不同的工具,编号1-N(代码中是0—N-1), 每种工具的加工时间为3—9天 ,但是现在老员工不在我们不知道每种工具的加工时间,庆幸的是 ...
- hdu 3501 Calculation 2 (欧拉函数)
题目 题意:求小于n并且 和n不互质的数的总和. 思路:求小于n并且与n互质的数的和为:n*phi[n]/2 . 若a和n互质,n-a必定也和n互质(a<n).也就是说num必定为偶数.其中互质 ...
- bzoj2823
最小圆覆盖 有个东西叫作随机增量法,具体可以baidu 这里来说说怎么求三点共圆 这其实就是求两条线段的交点 在编程中,我们解方程是比较麻烦的一个比较好的方法是利用相似三角形 设线段AB,CD交P,则 ...
- liunx上运行mybase
mybase 是个人知识管理软件,国内用他的人很多,尤其是程序员.我也是mybase的忠实使用者,有大量的积累. 以前一直用Windows,mybase使用完全没有问题,后来转投ubuntu阵营 ...