sqlchemy - day3
session
直接上代码,创建表结构,初始化部分数据。
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:max123@127.0.0.1/test?charset=utf8", echo=True)
from sqlalchemy import *
from sqlalchemy.orm import relationship
from sqlalchemy.ext.declarative import declarative_base
from datetime import datetime, date
from sqlalchemy.orm import deferred
Base = declarative_base()
class Parent(Base):
__tablename__ = 'parent'
id = Column(Integer(), primary_key=True)
name = Column(String(50))
summary = deferred(Column(Text))
children = relationship('ParentChild', back_populates='parent', cascade='all,delete-orphan')
class Child(Base):
__tablename__ = 'child'
id = Column(Integer(), primary_key=True)
name = Column(String(50))
parents = relationship('ParentChild', back_populates='child')
class ParentChild(Base):
__tablename__ = 'parent_child'
id = Column(Integer(), primary_key=True)
child_id = Column(Integer(), ForeignKey('child.id'), nullable=False)
parent_id = Column(Integer(), ForeignKey('parent.id'), nullable=False)
description = Column(String(100))
parent = relationship('Parent', back_populates='children')
child = relationship('Child', back_populates='parents')
Base.metadata.drop_all(engine)
Base.metadata.create_all(engine)
from sqlalchemy.orm import sessionmaker
Session = sessionmaker(bind=engine)
db = Session()
child_one = Child(name='purk1')
child_two = Child(name='purk2')
child_three = Child(name='purk3')
child_four = Child(name='purk4')
parent_one = Parent(name='Wu1')
parent_two = Parent(name='Wu2')
parent_child_one = ParentChild(description='association one')
parent_child_two = ParentChild(description='association two')
parent_child_one.child = child_one
parent_child_two.child = child_two
parent_one.children.extend([parent_child_one, parent_child_two])
db.add_all([parent_one, parent_two, child_four])
db.commit()
wfOrzbai
由简入难的开始
1. update
parent_one = db.query(Parent).filter_by(name='wu1').first()
parent_one.name='wu_test'
db.merge(parent_one) # update or insert
db.commit()
parent_one = db.query(Parent).filter_by(name='wu1').first()
parent_one.name='wu_test'
db.bulk_save_objects([parent_one])
db.commit()
结果
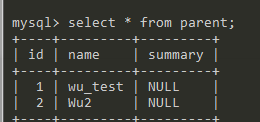
2. add
parent_three =Parent(name='Wu3')
db.add(parent_three)
db.commit()
parent_three =Parent(name='Wu3')
db.add_all([parent_three])
db.commit()
parent_three =Parent(name='Wu3')
db.merge(parent_three)
db.commit()
parent_three =Parent(name='Wu3')
db.bulk_save_objects([parent_three])
db.commit()
上面四种方式都可以得到下面的结果。

3. delete
db.delete(parent_two)
db.commit()
parent_two 被删除了。
4. select
查的内容就是涉及到query了,留到下一章节来讲。
注:
class sqlalchemy.orm.session.Session(bind=None, autoflush=True, expire_on_commit=True,_enable_transaction_accounting=True, autocom-mit=False, twophase=False,
weak_identity_map=True,binds=None, extension=None, info=None,query_cls=<class ‘sqlalchemy.orm.query.Query’>)
的expire_on_commit的配置,默认是True
parent = db.query(Parent).filter_by(name='wu1').first()
现在还没有做db.commit()的操作,访问parent的name属性,结果如下。

现在我做一个后台操作,直接数据库里面修改这parent实例对应的记录。
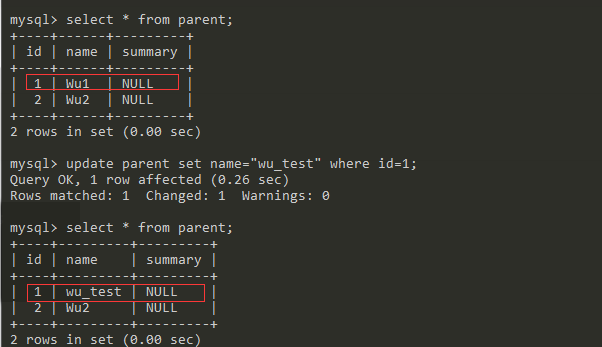
现在数据已经变为了wu_test,显然现在parent.name的值还是'Wu1',现在我在执行下面的代码。当我再次使用parent的时候,parent重新获取了一次数据。

只在commit和rollback的时候才是这样,close的时候是不会的。同时这个特性就要注意了。
sqlchemy - day3的更多相关文章
- 冲刺阶段day3
day3 项目进展 今天周三,我们五个人难得的一整个下午都能聚在一起.首先我们对昨天的成果一一地查看了一遍,并且坐出了修改.后面的时间则是做出 登录界面的窗体,完善了登录界面的代码,并且实现了其与数据 ...
- python笔记 - day3
python笔记 - day3 参考:http://www.cnblogs.com/wupeiqi/articles/5453708.html set特性: 1.无序 2.不重复 3.可嵌套 函数: ...
- python_way,day3 集合、函数、三元运算、lambda、python的内置函数、字符转换、文件处理
python_way,day3 一.集合 二.函数 三.三元运算 四.lambda 五.python的内置函数 六.字符转换 七.文件处理 一.集合: 1.集合的特性: 特性:无序,不重复的序列 如果 ...
- Spark菜鸟学习营Day3 RDD编程进阶
Spark菜鸟学习营Day3 RDD编程进阶 RDD代码简化 对于昨天练习的代码,我们可以从几个方面来简化: 使用fluent风格写法,可以减少对于中间变量的定义. 使用lambda表示式来替换对象写 ...
- Spark Tungsten揭秘 Day3 内存分配和管理内幕
Spark Tungsten揭秘 Day3 内存分配和管理内幕 恭喜Spark2.0发布,今天会看一下2.0的源码. 今天会讲下Tungsten内存分配和管理的内幕.Tungsten想要工作,要有数据 ...
- Catalyst揭秘 Day3 sqlParser解析
Catalyst揭秘 Day3 sqlParser解析 今天我们会进入catalyst引擎的第一个模块sqlparser,它是catalyst的前置模块. 树形结构 从昨天的介绍我们可以看到sqlPa ...
- Kakfa揭秘 Day3 Kafka源码概述
Kakfa揭秘 Day3 Kafka源码概述 今天开始进入Kafka的源码,本次学习基于最新的0.10.0版本进行.由于之前在学习Spark过程中积累了很多的经验和思想,这些在kafka上是通用的. ...
- python s12 day3
python s12 day3 深浅拷贝 对于 数字 和 字符串 而言,赋值.浅拷贝和深拷贝无意义,因为其永远指向同一个内存地址. 1 2 3 4 5 6 7 8 9 10 11 12 13 14 ...
- Day3 - Python基础3 函数、递归、内置函数
Python之路,Day3 - Python基础3 本节内容 1. 函数基本语法及特性 2. 参数与局部变量 3. 返回值 嵌套函数 4.递归 5.匿名函数 6.函数式编程介绍 7.高阶函数 8. ...
随机推荐
- [Java] MAP、LIST、SET集合解析
在JAVA的util包中有两个所有集合的父接口Collection和Map,它们的父子关系: java.util +Collection 这个接口extends自 --java.lang ...
- 使用PIL处理image
获得一个Image实例 import Image im = Image.open('1.jpg') #返回一个Image对象,open只对图片的头做处理,所以open操作是非常快的 resize,裁剪 ...
- KDE声音服务器 arts
KDE声音服务器 arts arts介绍arts是KDE的核心声音系统,支持多音频流.全双工.网络声音请求.ALSA与OSS驱动后端.JACK声音服务器后端等扩展,它既是声音服务器,也 提供一套音频软 ...
- oracle PL/SQL(procedure language/SQL)程序设计(续集)之PL/SQL函数
PL/SQL函数 examples:“ 构造一个邮件地址 v_mailing_address := v_name||CHR(10)|| ...
- 使用JDBC-ODBC读取Excel文件
以下代码我没有真正去实践,紧做为总结,方便以后查阅: 这种方法需要设置ODBC源..... 参考: http://xytang.blogspot.com/2008/02/how-to-connect- ...
- hdu 2295 DLX
思路:裸的DLX重复覆盖 #include<set> #include<cmath> #include<queue> #include<cstdio> ...
- CF 322E - Ciel the Commander 树的点分治
树链剖分可以看成是树的边分治,什么是点分治呢? CF322E - Ciel the Commander 题目:给出一棵树,对于每个节点有一个等级(A-Z,A最高),如果两个不同的节点有相同等级的父节点 ...
- 有一种风格,叫做 Low Poly 3D
原作:Simon阿文 杂交编辑者:RhinoC 个人更推崇使用第二款神器 ImageTriangulator :http://www.conceptfarm.ca/2013/port ...
- Android—SDCard数据存取&Environment简介
1:Environment简介: Environment是android.os包下的一个类,谷歌官方文旦的解释为:Provides access to environment variables(提供 ...
- Android 动画学习笔记
Android动画的两种:Frame帧动画.Tween动画(位移动画)[实现:存放目录res/anim] Tween动画:(位移.缩放.旋转):通过对场景里的对象不断做图像变换. 四种效果Alpha. ...