mysql InnoDB 索引小记
0、索引结构
1)、MyISAM与InnoDB索引结构比较,如下:

2)、MyISAM的索引结构
主键索引和二级索引结构很像,叶子存储的都是索引以及数据存储的物理地址,其他节点存储的仅仅是索引信息。其数据物理地址相连。


3)、InnoDB的索引结构
主键索引的每一个叶子存储的都是一行数据,而二级索引的每一个叶子存储的是二级索引以及主键索引,其他节点存储的仅仅是索引信息。


1、索引使用原则
1)、最左前缀匹配原则,mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。 2)、=和in可以乱序,比如a = 1 and b = 2 and c = 3 建立(a,b,c)引可以任意顺序,mysql的查询优化器会帮你优化成索引可以识别的形式 3)、尽量选择区分度高的列作为索引,区分度的公式是count(distinct col)/count(*),表示字段不重复的比例,比例越大我们扫描的记录数越少,唯一键的区分度是1,而一些状态、性别字段可能在大数据面前区分度就是0,那可能有人会问,这个比例有什么经验值吗?使用场景不同,这个值也很难确定,一般需要join的字段我们都要求是0.1以上,即平均1条扫描10条记录。 4)、索引列不能参与计算,保持列“干净”,比如from_unixtime(create_time) = ’2016-03-24’就不能使用到索引,原因很简单,b+树中存的都是数据表中的字段值,但进行检索时,需要把所有元素都应用函数才能比较,显然成本太大。所以语句应该写成create_time = unix_timestamp(’2016-03-24’); 5)、尽量的扩展索引,不要新建索引。比如表中已经有a的索引,现在要加(a,b)的索引,那么只需要修改原来的索引即可。 6)、如果表记录比较少,则可以不用使用索引。
2、使用联合索引的七种情况
1)、全列索引
mysql会使用索引,列顺序可以颠倒。 2)、最左前缀索引
mysql会使用索引 3)、查询条件用到了索引中的精确匹配,但中间某个条件未提供
mysql不会使用索引,但是如果把中间缺失的那个索引列补上,则可以有index优化。
“IN”可以用于索引列。 4)、查询条件未指定索引第一列
mysql不会使用索引。 5)、匹配某列的前缀字符串
只要通配符%不出现在开头,mysql可以为此列使用索引。 6)、范围查询
范围列可以用到索引,必须是最左前缀,但范围列后面的索引则列无法用到索引。 7)、查询条件列含有函数或者表达式
mysql不会为此列使用索引。
MySQL中的样例库中titles中

将索引emp_no删除,之后

当Where后面的查询条件都跟索引中列顺序一致时,

当其顺序与索引中顺序不一致时,

备注:这是由于MySQL的查询优化器会自动调整where条件的顺序来使用合适的索引。


备注:以上查询,Where条件中只是使用了索引中连续的一个或几个,当没有遵循最左前缀查询时,则只能进行全表扫描!

当联合索引中缺少某列时,且该列是可枚举的,此时可以将该列枚举一下,填坑的方式使其能够形成最左前缀。

当联合索引遇到>,<,>=,<=等符号时,则索引停止,这里跟普通的联合索引有所不同,当不是主键联合索引时,则当第一列使用了该种符号,则不会使用索引,当第二列使用时,则第一列才会使用索引。
如user表中的联合所有是(username,passport,loginTime),则当
1)、select * from user where username < 'Lee Tao' and passport = '123456';时,不会使用索引;
2)、select * from user where username = 'Lee Tao' and passport > '123456';时,则只会使用第一列username长度的索引;

不能在索引列上进行计算,也不能在索引列上添加函数计算,否则也不会使用该索引。
order by中当是联合主键时,是会使用索引,当是普通的联合索引时,若想要使用索引,则需要force index或查询的就是索引列,如:



一般order by需要跟limit或where一起使用时才能使用索引。
以下是普通索引的样例:




以上根据比例,新增有限制长度的索引。


当使用>=时,当是索引第一列时,则不会使用索引。
备注:对于同一张表的查询,每次只会用一个索引!
综上,存在联合索引a_b_c(a,b,c),其中假设每个列的长度分别为1,2,3,则根据where条件不同,应用最左前缀匹配原则,有:
1)、a = 1 and b = 2 and c = 3时,使用联合索引a_b_c(1+2+3)进行等值查找;
2)、a = 1 and b = 2时,使用联合索引a_b_c(1+2)进行查找,由于缺了c,只能使用部分索引;
3)、a = 1 and c = 3时,使用联合索引a_b_c(1)进行查找,由于缺了b,只能使用部分索引;当b是可枚举时,可以使用填坑的方式,将其补齐,如a = 1 and b in (1,2) and c = 3时,此时使用联合索引(1 + 2 + 3);
4)、a = 1时,使用联合索引a_b_c(1)进行查找,由于只有a,只能使用部分索引;
5)、b = 2 或 c = 3 或 b = 2 and c = 3时,由于此时不满足最左前缀匹配,故不会使用联合索引a_b_c;
6)、a = 1 and b = 2 and c > 3时,使用联合索引a_b_c(1 + 2),其中当索引列遇到>,<,>=,<=等符号时,则索引停止;
7)、a > 1 and b = 2时,当该索引是普通索引时,则不会使用索引,否则会使用索引a_b_c(1)。
备注:
1)、建立索引根据(表中该列的不同的值的行数) / (表中的所有记录行数 )的比例,越接近1,说明其可区分度高,则可以建立索引,当接近0时,即可区分度不高时,如性别或状态什么,就不适合建立索引。
2)、能建立联合索引的尽量建立联合索引。
小知识:前缀索引
前缀索引的选择
select count(distinct column_name) / count(*) from table_name;
select count(distinct left(column_name, prefix_length)) / count(*) from table_name;
建立前缀索引
alter table table_name add index(column_name(prefix_length));
前缀索引的优缺点:有效减少了索引文件的大小,提高了索引的速度,但不能在order by 或group by 中使用,也不能作用在覆盖索引(Covering Index)。
图说mysql查询执行流程【来自于网络】
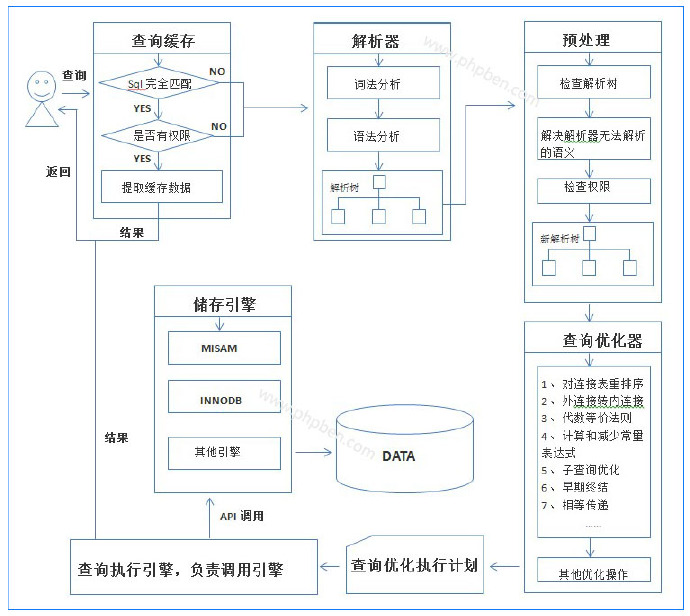
1)、查询缓存,判断sql语句是否完全匹配,再判断是否有权限,两个判断为假则到解析器解析语句,为真则提取数据结果返回给用户。
2)、解析器解析。解析器先词法分析,语法分析,检查错误比如引号有没闭合等,然后生成解析树。
3)、预处理。预处理解决解析器无法决解的语义,如检查表和列是否存在,别名是否有错,生成新的解析树。
4)、优化器做大量的优化操作。
5)、生成执行计划。
6)、查询执行引擎,负责调度引擎获取相应数据
7)、返回结果。
参考:
http://blog.coderland.net/mysql/2015/08/26/MySQL%E7%B4%A2%E5%BC%95%E5%AE%9E%E8%B7%B5/
http://www.kancloud.cn/kancloud/theory-of-mysql-index/41857
http://tech.meituan.com/mysql-index.html
http://www.cnblogs.com/hustcat/archive/2009/10/28/1591648.html
http://tec.5lulu.com/detail/104dan2wtey6z85a7.html
http://www.2cto.com/database/201302/188193.html
以上所引用的图什么大部分来自于网络!
mysql InnoDB 索引小记的更多相关文章
- MySQL InnoDB 索引 (INDEX) 页结构
MySQL InnoDB 索引 (INDEX) 页结构 InnoDB 为了不同的目的而设计了不同类型的页,我们把用于存放记录的页叫做索引页 索引页内容 索引页分为以下部分: File Header:表 ...
- 【原创】MySQL(Innodb)索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有 ...
- MySQL InnoDB 索引组织表 & 主键作用
InnoDB 索引组织表 一.索引组织表定义 在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表(index organized table IOT). 在Inno ...
- MySQL(Innodb)索引的原理
引言 回想四年前,我在学习mysql的索引这块的时候,老师在讲索引的时候,是像下面这么说的 索引就像一本书的目录.而当用户通过索引查找数据时,就好比用户通过目录查询某章节的某个知识点.这样就帮助用户有 ...
- 为什么mysql innodb索引是B+树数据结构
1.文件很大,不可能全部存储在内存中,所以要存在磁盘上 2.索引的组织结构要尽量减少查找过程中磁盘I/O的存取次数(为什么用B-/+Tree,还跟磁盘存取原理有关) 3.B+树所有的data域在叶子节 ...
- MySQL InnoDB 索引原理
本文由 网易云发布. 作者:范鹏程,网易考拉海购 InnoDB是 MySQL最常用的存储引擎,了解InnoDB存储引擎的索引对于日常工作有很大的益处,索引的存在便是为了加速数据库行记录的检索.以下是 ...
- mysql Innodb索引
基本概念 对于mysql目前的默认存储引擎Innodb来说,索引分为2个,一个是聚集索引,一个是普通索引(也叫二级索引). 聚集索引:聚集索引的顺序和数据在磁盘的顺序一致,因此查询时使用聚集索引,效率 ...
- mysql innodb索引原理
聚集索引(clustered index) innodb存储引擎表是索引组织表,表中数据按照主键顺序存放.其聚集索引就是按照每张表的主键顺序构造一颗B+树,其叶子结点中存放的就是整张表的行记录数据,这 ...
- MySQL InnoDB索引介绍以及在线添加索引实例分析
引言:MySQL之所以能成为经典,不是没有道理的,B+树足矣! 一.索引概念 InnoDB引擎支持三种常见的索引:B+树索引,全文索引和(自适应)哈希索引.B+树索引是传统意义上的索引,构造类似二叉树 ...
随机推荐
- IOS_问题: Xcode8 安装KSImageName插件, 编代码就崩了
Xcode 8之后, KSImageName插件就不能用了,如果安装了,就会导致一写英文代码Xcode 就崩了. 解决方法: 把这个插件删除,重启了一下xcode就可以了, 如果重启没用, 可以尝试下 ...
- Jquery操作Cookie取值错误的解决方法
使用JQuery操作cookie时 发生取的值不正确,结果发现cookie有四个不同的属性,分享下错误的原因及解决方法. 使用JQuery操作cookie时 发生取的值不正确的问题: 结果发现coo ...
- c#读写注册表示例分享
c#读写注册表示例,示例中有详细注释. 代码: //写注册表RegistryKey regWrite;//往HKEY_CURRENT_USER主键里的Software子键下写一个名为“Test”的子键 ...
- haproxy 常用acl规则与会话保持
一.常用的acl规则 haproxy的ACL用于实现基于请求报文的首部.响应报文的内容或其它的环境状态信息来做出转发决策,这大大增强了其配置弹性.其配置法则通常分为两 步,首先去定义ACL,即定义一个 ...
- python with语句上下文管理的两种实现方法
在编程中会经常碰到这种情况:有一个特殊的语句块,在执行这个语句块之前需要先执行一些准备动作:当语句块执行完成后,需要继续执行一些收尾动作.例如,文件读写后需要关闭,数据库读写完毕需要关闭连接,资源的加 ...
- [转]Oracle学习记录 九 Prc C学习
经过前面的了解,现在想用C语言来编程了,搜索了很多东西,后来决定先用Pro C来进行学习 在安装完Oracle数据库后就可以进行编程了,里面有一个命令proc就是对程序进行预编译的. 在这记一下,这是 ...
- orcale 修改字段属性
有些时候,因为没能预料到一些情况的变化,需要修改字段的类型.如果是varchar型,直接增加长度是可以的,但是如果需要修改成其他类型就不能这么做了. 思路:1.增加一个临时列,把需要修改的那个字段的数 ...
- PHP中::、->、self、$this操作符的区别
在访问PHP类中的成员变量或方法时,如果被引用的变量或者方法被声明成const(定义常量)或者static(声明静态),那么就必须使用操作符::,反之如果被引用的变量或者方法没有被声明成const或者 ...
- 人工智能起步-反向回馈神经网路算法(BP算法)
人工智能分为强人工,弱人工. 弱人工智能就包括我们常用的语音识别,图像识别等,或者为了某一个固定目标实现的人工算法,如:下围棋,游戏的AI,聊天机器人,阿尔法狗等. 强人工智能目前只是一个幻想,就是自 ...
- C++中的冒泡排序,选择排序,插入排序
最简单的插入排序:思想,两两之间比较,时间复杂度o(n^2) void bubblesort(vector<int>&vec, int n) { if (&vec==NUL ...