自然语言处理NLTK之入门
环境:window10 + python3
一、安装NLTK
pip install nltk
# 或者 PyCharm --> File --> Settings --> Project Interpreter --> +号搜索 --> Install Package 【matplotlib、numpy、pandas一并安装,后面会用到】
二、下载NLTK books数据
# download_books.py 中 # -*- coding: utf-8 -*-
# Nola
import nltk
nltk.download()


特别说明:Download Directory(下载目录)可以自己指定,父目录必须为nltk_data,此处下载目录为沙盒环境下的share目录。若不知道该怎么自定义下载目录可参考下方提供的几个查找目录,放在查找目录下一定没错:
若显示下载失败,在NLTK Downloader界面的All Packages找到对应的库单独下载。
三、使用NLTK books数据
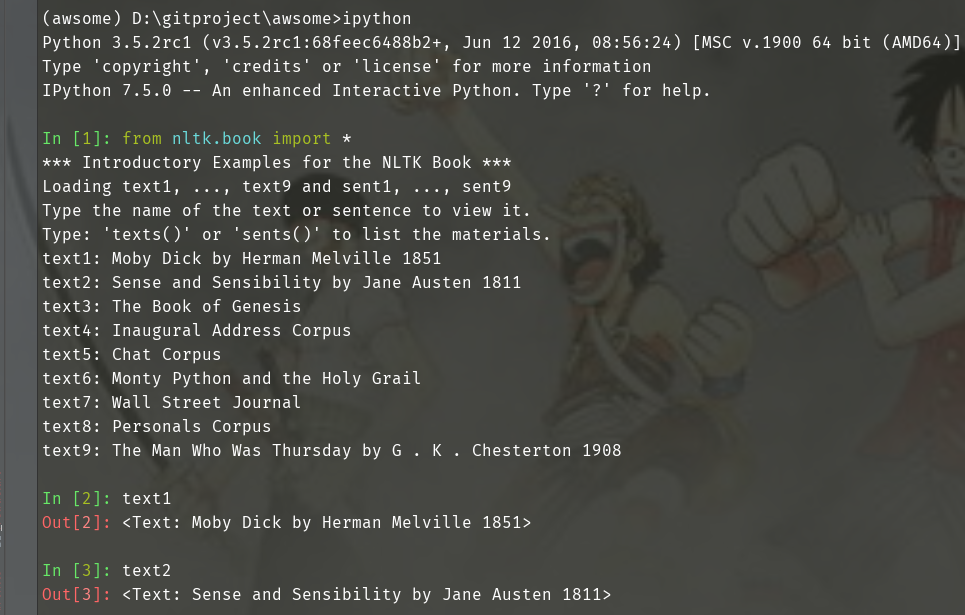
1.1 引入books数据集
# Pycharm 打开Terminal
# 安装ipython
pip install ipython from nltk.book import * text1 text2
1.2 搜索文本
# concordance(word)函数 词汇索引word及上下文
text1.concordance("monstrous")
text2.concordance("affection")
text5.concordance("lol") # similar(word)函数 搜索word相关词
text1.similar("monstrous")
text2.similar("monstrous") # common_contexts([word1, word2])函数 搜索多个word共同上下文
text2.common_contexts(["monstrous", "very"]) # dispersion_plot([word1, word2, word3])函数 判断词在文本中的位置(每一竖线代表一个单词,从文本开始位置到指定词前面有多少给词) 离散图(使用matplotlib画图)
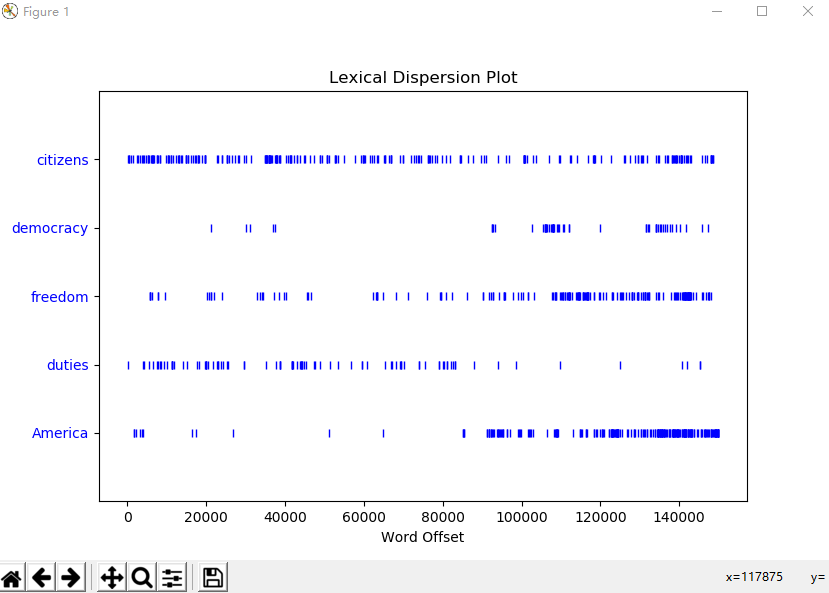
# generate() 生成随机文本
text3.generate()

1.3 词汇计数
# python语法
len(text3)
sorted(set(text3))
len(set(text3))
1.4 词频分布
# FreqDist(text)函数 返回text文本中每个词出现的次数的元组列表
fdist1 = FreqDist(text1) fdist1
FreqDist({',': 18713, 'the': 13721, '.': 6862, 'of': 6536, 'and': 6024, 'a': 4569, 'to': 4542, ';': 4072, 'in': 3916, 'that': 2982, ...}) print(fdist1)
<FreqDist with 19317 samples and 260819 outcomes> # hapaxes()函数 返回低频词
len(fdist1.hapaxes()) # most_common(num)函数 返回高频词汇top50
fdist1.most_common(50) fdist1.plot(50, cumulative=True) # top50词汇累计频率图
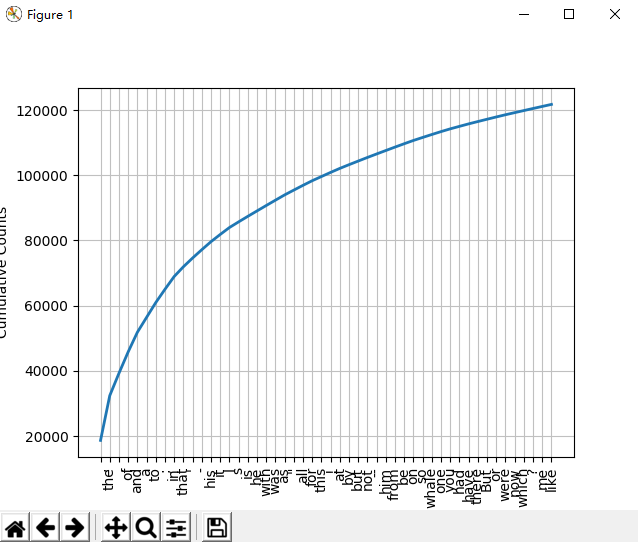
1.5 细粒度选择词
高频词和低频词提取出的信息量有限,研究文本中的长词提取出更多的信息量。采用集合论的一些符号:P性质,V词汇,w单个词符,P(w)当且仅当w词符长度大于15。表示为:{w | w ∈ V & P(w)}
V = set(text1)
long_words = [w for w in V if len(w) > 15]
len(long_words) fdist5 = FreqDist(text5)
sorted(w for w in set(text5) if len(w) > 7 and fdist5[w] > 7)
1.6 词语搭配和双连词
# 词对称为双连词 # bigrams([word1, word2, word3]) 生成双连词 返回一个generator
list(bigrams(["a", "doctor", "with", "him"]))
Out[37]: [('a', 'doctor'), ('doctor', 'with'), ('with', 'him')] # nltk中使用collocation_list()函数生成 很能体现文本风格
text4.collocation_list()
text8.collocation_list()
Out[44]:
['would like',
'medium build',
'social drinker',
'quiet nights',
'non smoker',
'long term',
'age open',
'Would like',
'easy going',
'financially secure',
'fun times',
'similar interests',
'Age open',
'weekends away',
'poss rship',
'well presented',
'never married',
'single mum',
'permanent relationship',
'slim build']
1.7 计数词汇长度
# 统计text1文本词符长度和长度频次
[len(w) for w in text1] fdist = FreqDist(len(w) for w in text1) In [47]: fdist
Out[47]: FreqDist({3: 50223, 1: 47933, 4: 42345, 2: 38513, 5: 26597, 6: 17111, 7: 14399, 8: 9966, 9: 6428, 10: 3528, ...}) In [48]: fdist.most_common(10)
Out[48]:
[(3, 50223),
(1, 47933),
(4, 42345),
(2, 38513),
(5, 26597),
(6, 17111),
(7, 14399),
(8, 9966),
(9, 6428),
(10, 3528)] In [49]: fdist.max()
Out[49]: 3 In [50]: fdist[3]
Out[50]: 50223 In [51]: fdist.freq(3)
Out[51]: 0.19255882431878046 In [52]: fdist.freq(1)
Out[52]: 0.18377878912195814
1.8 函数说明
fdist.N() # 样本总数 In [60]: fdist.freq(3) # 给定样本的频率
Out[60]: 0.19255882431878046 In [55]: fdist.tabulate() # 频率分布表
3 1 4 2 5 6 7 8 9 10 11 12 13 14 15 16 17 18 20
50223 47933 42345 38513 26597 17111 14399 9966 6428 3528 1873 1053 567 177 70 22 12 1 1 fdist.plot() # 频率分布图 (图1)
fdist.plot(cumulative=True) # 累计频率分布图 (图2)
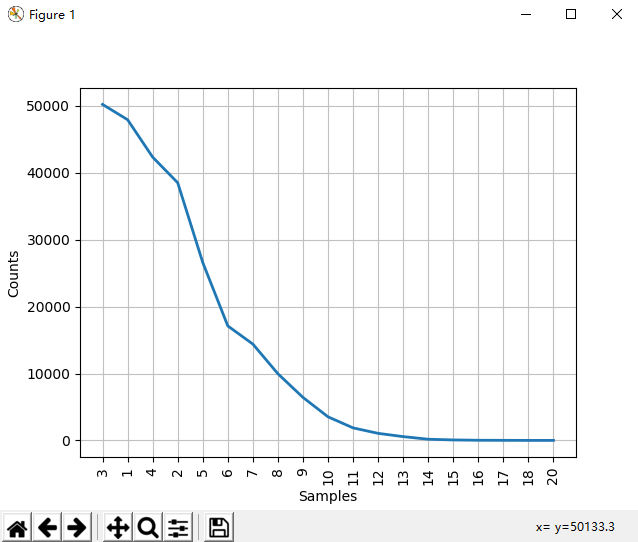
图1
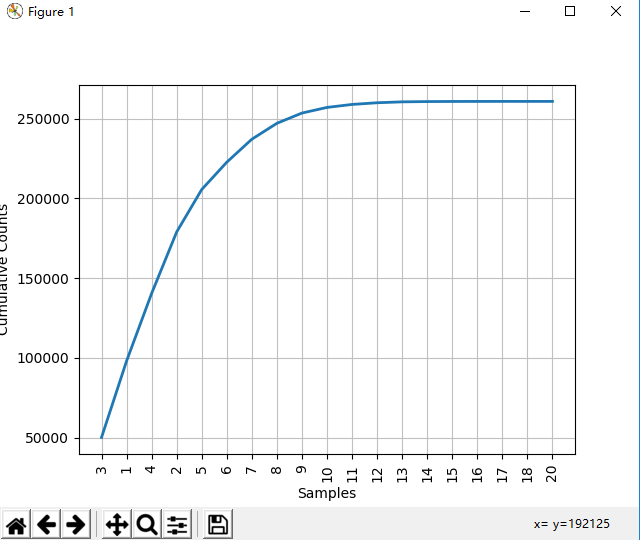
图2
自然语言处理NLTK之入门的更多相关文章
- 自然语言处理NLP快速入门
自然语言处理NLP快速入门 https://mp.weixin.qq.com/s/J-vndnycZgwVrSlDCefHZA [导读]自然语言处理已经成为人工智能领域一个重要的分支,它研究能实现人与 ...
- Python自然语言工具包(NLTK)入门
在本期文章中,小生向您介绍了自然语言工具包(Natural Language Toolkit),它是一个将学术语言技术应用于文本数据集的 Python 库.称为“文本处理”的程序设计是其基本功能:更深 ...
- python自然语言处理函数库nltk从入门到精通
1. 关于Python安装的补充 若在ubuntu系统中同时安装了Python2和python3,则输入python或python2命令打开python2.x版本的控制台:输入python3命令打开p ...
- Mac OS10.9 下python开发环境(eclipse)以及自然语言包NLTK的安装与注意
折腾了大半天,终于把mbp上python自然语言开发环境搭建好了. 第一步,安装JDK1.7 for mac MacOS10.9是自带python2.7.5的,够用,具体的可以打开终端输入python ...
- 自然语言处理--nltk安装及wordnet使用详解
环境:python2.7.10 首先安装pip 在https://pip.pypa.io/en/stable/installing/ 下载get-pip.py 然后执行 python get-pip. ...
- 自然语言处理——NLTK中文语料库语料库
Python NLTK库中包含着大量的语料库,但是大部分都是英文,不过有一个Sinica(中央研究院)提供的繁体中文语料库,值得我们注意. 在使用这个语料库之前,我们首先要检查一下是否已经安装了这个语 ...
- Python3自然语言(NLTK)——语言大数据
NLTK 这是一个处理文本的python库,我们知道文字性的知识可是拥有非常庞大的数据量,故而这属于大数据系列. 本文只是浅尝辄止,目前本人并未涉及这块知识,只是偶尔好奇,才写本文. 从NLTK中的b ...
- 自然语言处理hanlp的入门基础
此文整理的基础是建立在hanlp较早版本的基础上的,虽然hanlp的最新1.7版本已经发布,但对于入门来说差别不大!分享一篇比较早的“旧文”给需要的朋友! 安装HanLP HanLP将数据与程序分 ...
- 自然语言处理NLTK
Python文本分析工具NLTK 情感分析 文本相似度 文本分类 分类预测模型:朴素贝叶斯 实战案例:微博情感分析
随机推荐
- 892A. Greed#贪婪(优先队列priority_queue)
题目出处:http://codeforces.com/problemset/problem/892/A 题目大意:有一些可乐(不一定装满),问能不能把所有可乐装进两个可乐瓶中 #include< ...
- Matlab高级教程_第二篇:一个简单的混编例子
1. 常用的混编是MATLAB和VS两个编辑器之间的混编方式. 2. 因为MATLAB的核是C型语言,因此常见的混编方式是MATLAB和C型语言的混编. 3. 这里介绍一个简单的MATLAB语言混编成 ...
- [LC] 90. Subsets II
Given a collection of integers that might contain duplicates, nums, return all possible subsets (the ...
- Linux_列出文件和文件属性
ls +文件名:列出该文件 ls +目录名:列出该目录下的文件 ls 什么也不加:列出当前工作目录下的文件 ls -a 列出包括隐藏文件,即所有文件名 ls -l 列出文件名+详细信息 ls -al ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- day42-进程池
#进程池Pool:apply apply_async-close-join-get map callback #1.进程池Pool:执行下面代码发现任务012先执行,345后执行,因为进程池只有3个进 ...
- 部署企业本地yum源及源码包安装
YUM命令 yum list //列出每个软件包(包括未安装和已安装) rpm -q repolist //列出所以仓库名称 info //查看软件信息 rpm -qi install //安装 rp ...
- if necessary
- JavaScript 的DOM操作及实例
一.Windows对象操作 (1).用代码打开窗口:window.open("第一部分","第二部分","第三部分","第四部分& ...
- ExecuteScalar()方法的使用
ExecuteScalar()方法的作用是: 执行查询,并返回查询所返回的结果集中第一行的第一列.所有其他的列和行将被忽略. 1.返回的是一个object类型,也就是说是所有数据类型的基类,可根据se ...