【图机器学习】cs224w Lecture 10 - PageRank
转自本人:https://blog.csdn.net/New2World/article/details/106233258
将互联网视为图的话,它必定存在结构上的一些规律。首先回顾一下强连通子图 (strongly connected component, SCC),如果一个有向图的子图内任意节点可以互相到达,那么这就是一个 SCC。而包含节点 A 的 SCC 必满足 \(SCC(A)=Out(A)\cap In(A)\) 其中 Out 和 In 分别表示从 A 出发能到达的点以及能到达 A 的点。
在 2000 年的一篇互联网分析论文中显示,当时互联网节点大概 2 千万左右,链接数在 15 亿上下。对于随机点的 Out 和 In 大概都覆盖了半个互联网,即 1 千万个点,由这个随机点得到的 SCC 覆盖了 1/4 个互联网。由此我们可以大致画出互联网的构成关系图。
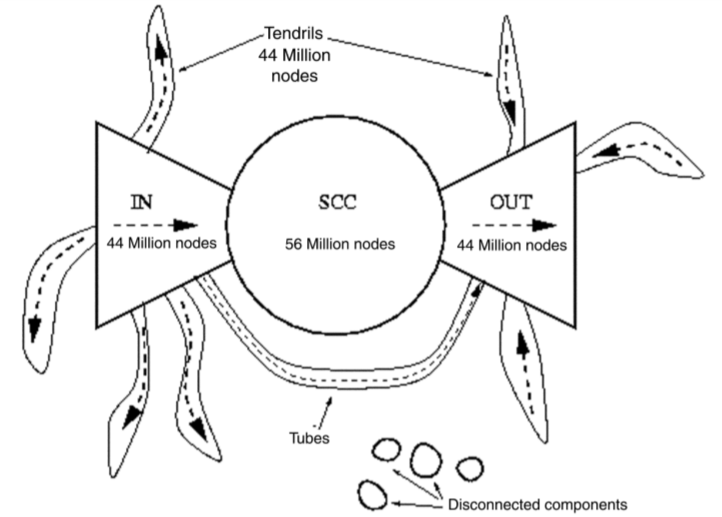
PageRank
搜索引擎的工作就是根据我们提供的关键词对如此大规模的网页进行相关性排序的过程,然后将最相关的多条链接返回给用户。然而互联网如此之大,我们提供的关键词并不精确,当同时存在多条完美匹配的记录时怎样尽可能返回更优质的链接成为了曾经的一道难题。当时在 Stanford 就读的 Google 创始人之一 Larry Page 和他的小伙伴提出了 PageRank —— 一种网页评分的迭代策略。因此 PageRank 中的 Page 实际上是人名。
PageRank 的思想很简单,把网页间的链接视为一种均匀的投票机制。比如节点 v 有三个外链,且其自身的初始“票权”为 1。那么迭代开始后,v 会将自己的票平分给三个外链,即每个外链能得到 1/3。同理如果 v 是其它节点的外链,那 v 也会得到其它节点平分后的票。一直这么迭代下去直到收敛就是 PageRank 的核心过程。或者另一种解释是通过 random walk 来理解。如果当前我们位于节点 v,那么我们可以等概率的转移到 v 指向的所有邻接节点。当转移足够多次后会达到一个类似 MDP 中的稳定状态,表示在任意时间点我们位于各个节点的概率。
Talk is cheap, show me the 'math'. \(r\) 为权重,\(d\) 为出度。
\]
写成矩阵的形式为 \(r = M \cdot r\),其中 \(M_{ij}\) 表示 j 到 i 的权重,也就是说 \(M\) 的每一行其实是入度,这与邻接矩阵恰好相反。
回过头看看这个矩阵表示 \(r = M\cdot r\),是不是很像特征值的定义?也就是说,当满足 \(r = M\cdot r\) 时,\(r\) 是 \(M\) 的(主)特征向量,且对应的特征值为 1,而这个 \(r\) 就是一个 stationary 的权重分布。
虽然这个问题看似可以通过解线性方程组的方式得到解析解,然而这样做忽略了一个重要的前提:网络的规模。要解决一个有千万甚至上亿个变量的方程组,时间开销不是玩笑……
Power iteration
- 初始化:\(r\)
- 迭代:\(r^{(t+1)}=M\cdot r^{(t)}\)
- 停止:\(|r^{(t+1)}-r^{(t)}|_1<\epsilon\)
Problems
目前为止 PageRank 很完美,然而它遇到两种情况时会出现 bug。
- Dead ends:没有 out-link 的节点,这种节点会导致整个系统的权重泄漏。(不收敛)
- Spider traps:对于一个节点群,所有的 out-links 都指向群体内部节点。这种情况会导致这个节点群吸收掉整个系统中的所有权重。(收敛得到的结果并非我们想要的)
上述两个问题可由随机跳转方法解决
- 遇到 dead ends 时以概率 1 跳转到其它任意节点。
- 系统判断进入 trap 后,以概率 p 转移到其它任意节点。
而 Google 将这随机跳转和 PageRank 统一起来,通过设定概率 \(\beta\) 来控制迭代过程。以 \(\beta\) 的概率规规矩矩地迭代;以概率 \(1-\beta\) 的概率跳转到任意节点。
\]
通常来说 \(\beta=0.8\ 0.9\),即平均 5 次迭代后跳转。不过这么做的前提是 dead ends 已经被提前处理掉了,比如直接删除 dead ends,或在 dead ends 处以概率 1 进行跳转。在实际运算中,并不会将 \((1-\beta)/N\) 直接加到矩阵里去。因为加上 \((1-\beta)/N\) 后会破坏 \(M\) 稀疏矩阵的性质,这样会耗费大量存储空间。因此一般先计算 \(\beta M\cdot r\) 然后对得到的 \(r\) 向量的每一项加上 \((1-\beta)/N\)。
下面给出 PageRank 的伪码

没有 dead ends 的情况下,系统不会出现权重泄漏的情况。一旦出现 dead end,权重泄漏会导致 \(\sum_jr_j^{new}<1\),因此上面的伪码中通过记录权重和 S 来弥补泄漏。而这里必定有 \((1-S)/N \geq (1-\beta)/N\)
Personalized PageRank
现在考虑另一个问题,计算机领域如此多大大小小的会议以及投各个会议的大牛们,如何通过各研究者投的会议来推断哪些会议涉及的领域相似。
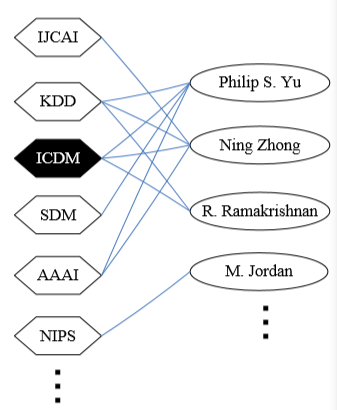
其实这个问题也是一个相关性排序的问题,只不过出发点固定为了你想查询的那个会议。还是通过 random walk 的思想来解决。比如要查询 ICDM,那从 ICDM 出发能通过 Philip S. Yu 到达 KDD, SDM 和 AAAI,通过 Ning Zhong 到达 IJCAI。问题是如果“走到头”了怎么办?这里就不能随机跳了,因为很有可能会跳到毫不相关的会上去。因此这里使用的是 random walk with restart,顾名思义走不动了就回到起点,即 ICDM 然后重新开始。就这样不停的 random walk 就能得到到达各个会议的次数,根据次数排序就是相关度排序了。而且这种方法能同时查询多个会议。
总结一下,PageRank 实质其实就是一个 random walk 的过程,而几种不同的 PageRank 的区别仅在于跳转后落点的概率 S。
- PageRank:\(S=[1/N, 1/N, 1/N,..., 1/N]\)
- Personalized:\(S=[0.1, 0, 0.1,..., 0.2, 0,..., 0.3]\) (反正和为 1)
- Random Walk with Restart:\(S=[0, 0, 0, 1, 0,..., 0]\)
【图机器学习】cs224w Lecture 10 - PageRank的更多相关文章
- 【图机器学习】cs224w Lecture 16 - 图神经网络的局限性
目录 Capturing Graph Structure Graph Isomorphism Network Vulnerability to Noise 转自本人:https://blog.csdn ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 10—Advice for applying machine learning 机器学习应用建议
Lecture 10—Advice for applying machine learning 10.1 如何调试一个机器学习算法? 有多种方案: 1.获得更多训练数据:2.尝试更少特征:3.尝试更多 ...
- 图机器学习(GML)&图神经网络(GNN)原理和代码实现(前置学习系列二)
项目链接:https://aistudio.baidu.com/aistudio/projectdetail/4990947?contributionType=1 欢迎fork欢迎三连!文章篇幅有限, ...
- 4张图看懂delphi 10生成ipa和在iPhone虚拟器上调试(教程)
4张图看懂delphi 10生成ipa和在iPhone虚拟器上调试(教程) (2016-02-01 03:21:06) 转载▼ 标签: delphi ios delphi10 教程 编程 分类: 编程 ...
- 【图机器学习】cs224w Lecture 15 - 网络演变
目录 Macroscopic Forest Fire Model Microscopic Temporal Network Temporal PageRank Mesoscopic 转自本人:http ...
- 【图机器学习】cs224w Lecture 7 - 节点的表示
目录 Node Embedding Random Walk node2vec TransE Embedding Entire Graph Anonymous Walk Reference 转自本人:h ...
- 【图机器学习】cs224w Lecture 8 & 9 - 图神经网络 及 深度生成模型
目录 Graph Neural Network Graph Convolutional Network GraphSAGE Graph Attention Network Tips Deep Gene ...
- 【图机器学习】cs224w Lecture 13 & 14 - 影响力最大化 & 爆发检测
目录 Influence Maximization Propagation Models Linear Threshold Model Independent Cascade Model Greedy ...
- 【图机器学习】cs224w Lecture 11 & 12 - 网络传播
目录 Decision Based Model of Diffusion Large Cascades Extending the Model Probabilistic Spreading Mode ...
随机推荐
- 关于phpstorm、idea、gogland等等ide全家桶设置
2017-08-29 16:30:55 Preferences => IDE Settings => Editor => Code Completion => Autopopu ...
- B站百大UP主党妹被黑客勒索!!!
4月27日,哔哩哔哩视频网站的UP主“机智的党妹”发布消息称,自己被黑客勒索了.她的视频表示:“事发突然,我被勒索了,你也有可能继续被诈骗!这种诈骗的页面是由病毒程序自动生成并留在那里的.”根据她的介 ...
- 头文件<cmath>中常用函数
<cmath>里面有很多数学函数,下面说一下常用的一些函数吧:直接把函数原型给了出来,用的时候注意参数 先说一下,c++自身是没有四舍五入函数round()的,若果你要用到的话,可以自己写 ...
- Nagios基本搭建
Nagios简述: 1.一款用来监视系统和网络的开源软件 2.利用其从多的插件实现对本机和远端服务的监控 3.当被监控对象异常时,回及时向管理员警告 4.提供一批预设好的监控插件,用户可以直接调用 5 ...
- 虚拟化KVM之安装(二)
安装KVM虚拟化 1.系统基础环境: [root@linux-node1 ~]# ip addr | grep inet | awk '{ print $2; }' | sed 's/\/.*$//' ...
- tcpdump常用抓包命令
主要语法 过滤主机/IP: tcpdump -i eth1 host 172.16.7.206 抓取所有经过网卡1,目的IP为172.16.7.206的网络数据 过滤端口: tcpdump -i ...
- 超轻量级网络SqueezeNet网络解读
SqueezeNet网络模型非常小,但分类精度接近AlexNet. 这里复习一下卷积层参数的计算 输入通道ci,核尺寸k,输出通道co,参数个数为: 以AlexNet第一个卷积为例,参数量达到:3*1 ...
- 【漏洞预警】SaltStack远程命令执行漏洞 /tmp/salt-minions
前言: 2020年5月3日,阿里云应急响应中心监测到近日国外某安全团队披露了SaltStack存在认证绕过致命令执行漏洞以及目录遍历漏洞.在多个微信群和QQ群已经有群友反映中招,请马上修复. 以下 ...
- python-圆周率的计算【random库的应用】
圆周率的计算 ...
- Java模拟UDP通信
目录 Java基础:模拟UDP通信 1.一次发送,一次接收 1.1.发送方 1.2.接收方 2.多次发送,多次接收 2.1.发送方 2.2.接收方 3.模拟双方通信 3.1.发送方的线程 3.2.接收 ...