Hadoop完全高可用集群安装
架构图(HA模型没有SNN节点)

用vm规划了8台机器,用到了7台,SNN节点没用
|
|
NN
|
DN
|
SN
|
ZKFC
|
ZK
|
JNN
|
RM
|
NM
|
|
node1
|
*
|
|
|
*
|
|
|
|
|
|
node2
|
*
|
|
|
*
|
|
|
|
|
|
node3
|
|
|
|
|
|
|||
|
node4
|
|
|
|
*
|
|
|
*
|
|
|
node5
|
|
|
|
*
|
|
|
*
|
|
|
node6
|
|
*
|
|
|
*
|
*
|
|
*
|
|
node7
|
|
*
|
|
|
*
|
*
|
|
*
|
|
node8
|
|
*
|
|
|
*
|
*
|
|
*
|
集群搭建前准备工作:
*搭建集群之前需要关闭所有服务器的selinux和防火墙
1.更改所有服务器的主机名和hosts文件对应关系
[root@localhost ~]# hostnamectl set-hostname node1 [root@localhost ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.159.129 node1
192.168.159.130 node2
192.168.159.132 node3
192.168.159.133 node4
192.168.159.136 node5
192.168.159.137 node6
192.168.159.138 node7
192.168.159.139 node8
2.两个NameNode节点做对所有主机的免密登陆,包括自己的节点;两个resourcemanager节点互相做免密登陆,包括自己的节点
[root@localhost ~]# ssh-keygen
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:lIvGygyJHycNTZJ0KeuE/BM0BWGGq/UTgMUQNo7Qm2M root@node1
The key's randomart image is:
+---[RSA 2048]----+
|+@=**o |
|*.XB. . |
|oo+*o o |
|.+E=.. o . |
|o=*o+.+ S |
|...Xoo |
| . =. |
| |
| |
+----[SHA256]-----+ [root@localhost ~]# for i in `seq 1 8`;do ssh-copy-id root@node$i;done
3.同步所有服务器时间
[root@node1 ~]# ansible all -m shell -o -a 'ntpdate ntp1.aliyun.com'
node4 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:37 ntpdate[2477]: adjust time server 120.25.115.20 offset 0.001546 sec
node6 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:37 ntpdate[2470]: adjust time server 120.25.115.20 offset 0.000220 sec
node2 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:37 ntpdate[2406]: adjust time server 120.25.115.20 offset -0.002414 sec
node3 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:37 ntpdate[2465]: adjust time server 120.25.115.20 offset -0.001185 sec
node5 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:37 ntpdate[2466]: adjust time server 120.25.115.20 offset 0.005768 sec
node7 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:43 ntpdate[2503]: adjust time server 120.25.115.20 offset 0.000703 sec
node8 | CHANGED | rc=0 | (stdout) 20 Feb 16:08:43 ntpdate[2426]: adjust time server 120.25.115.20 offset -0.001338 sec
4.所有服务器安装JDK环境并配置好环境变量
[root@node1 ~]# tar -xf jdk-8u144-linux-x64.gz -C /usr/
[root@node1 ~]# ln -sv /usr/jdk1.8.0_144/ /usr/java
"/usr/java" -> "/usr/jdk1.8.0_144/" [root@node1 ~]# cat /etc/profile.d/java.sh
export JAVA_HOME=/usr/java
export PATH=$PATH:$JAVA_HOME/bin [root@node1 ~]# source /etc/profile.d/java.sh
[root@node1 ~]# java -version
java version "1.8.0_144"
Java(TM) SE Runtime Environment (build 1.8.0_144-b01)
Java HotSpot(TM) 64-Bit Server VM (build 25.144-b01, mixed mode)
zookeeper集群搭建
在规划好的6、7、8节点上安装zookeeper(JDK环境要准备好)
#解压zookeeper程序到/usr目录下
[root@node6 ~]# tar xf zookeeper-3.4.6.tar.gz -C /usr/
#创建zookeeper存放数据目录
[root@node6 ~]# mkdir /usr/data/zookeeper
#将zookeeper的conf目录下sample配置文件更改成cfg文件
[root@node6 ~]# cp /usr/zookeeper-3.4.6/conf/zoo_sample.cfg /usr/zookeeper-3.4.6/conf/zoo.cfg
#编辑配置文件,更改数据存放目录,并添加zookeeper集群配置信息
[root@node6 ~]# vim /usr/zookeeper-3.4.6/conf/zoo.cfg
dataDir=/usr/data/zookeeper #修改
server.1=node6:2888:3888 #添加
server.2=node7:2888:3888 #添加
server.3=node8:2888:3888 #添加 #把配置好的zookeeper程序文件分发至其余的两个节点
[root@node6 ~]# scp -r /usr/zookeeper-3.4.6/ node7:/usr/zookeeper-3.4.6/
[root@node6 ~]# scp -r /usr/zookeeper-3.4.6/ node8:/usr/zookeeper-3.4.6/ #在刚刚创建的目录下当前zookeeper节点信息,必须为数字,且三个节点不能相同
[root@node6 ~]# echo 1 > /usr/data/zookeeper/myid #在剩下的两个节点上也要创建数据存放目录和节点配置文件
[root@node7 ~]# mkdir /usr/data/zookeeper
[root@node7 ~]# echo 2 > /usr/data/zookeeper/myid
[root@node8 ~]# mkdir /usr/data/zookeeper
[root@node8 ~]# echo 3 > /usr/data/zookeeper/myid
#配置完成后启动zookeeper集群
[root@node6 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start
[root@node7 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start
[root@node8 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh start #查看集群启动情况(先启动的会成为leader,同时启动数字大的会成为leader)
[root@node6 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower [root@node7 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: follower [root@node8 ~]# /usr/zookeeper-3.4.6/bin/zkServer.sh status
JMX enabled by default
Using config: /usr/zookeeper-3.4.6/bin/../conf/zoo.cfg
Mode: leader [root@node8 ~]# netstat -tnlp | grep java #只有主节点有2888
tcp6 0 0 :::2181 :::* LISTEN 33766/java
tcp6 0 0 192.168.159.139:2888 :::* LISTEN 33766/java
tcp6 0 0 192.168.159.139:3888 :::* LISTEN 33766/java
tcp6 0 0 :::43793 :::* LISTEN 33766/java
Hadoop集群搭建
1.先添加hadoop的环境变量
[root@node1 ~]# cat /etc/profile.d/hadoop.sh
export HADOOP_HOME=/usr/hadoop-2.9.2
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
2.解压hadoop程序包到/usr目录下
[root@node1 ~]# tar xf hadoop-2.9.2.tar.gz -C /usr
[root@node1 ~]# ln -sv /usr/hadoop-2.9.2/ /usr/hadoop
"/usr/hadoop" -> "/usr/hadoop-2.9.2/"
3.更改hadoop程序包内 hadoop-env.sh,mapred-env.sh,yarn-env.sh中的JAVA_HOME环境变量
[root@node1 ~]# grep 'export JAVA_HOME' /usr/hadoop/etc/hadoop/{hadoop-env.sh,mapred-env.sh,yarn-env.sh}
/usr/hadoop/etc/hadoop/hadoop-env.sh:export JAVA_HOME=/usr/java
/usr/hadoop/etc/hadoop/mapred-env.sh:export JAVA_HOME=/usr/java
/usr/hadoop/etc/hadoop/yarn-env.sh:export JAVA_HOME=/usr/java
4.修改core-site.xml文件(NameNode配置文件)
[root@node1 ~]# vim /usr/hadoop/etc/hadoop/core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop</value>
<!--HA部署下,NameNode访问hdfs-site.xml中的dfs.nameservices值 -->
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/data/hadoop</value>
<!--Hadoop的文件存放目录 -->
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node6:2181,node7:2181,node8:2181</value>
<!--zookeeper集群地址 -->
</property>
</configuration>
5.在所有hadoop节点创建/usr/data/hadoop目录
6.修改hdfs-site.xml文件
[root@node1 ~]# vim /usr/hadoop/etc/hadoop/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<!--数据文件副本数量-->
</property>
<property>
<name>dfs.blocksize</name>
<value>134217728</value>
<!--数据块大小,文件超过这个大小就会切开,128M -->
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
<!-- **** -->
</property>
<property>
<name>dfs.nameservices</name>
<value>hadoop</value>
<!--这个值就是core-site.xml中hdfs集群入口 -->
</property>
<property>
<name>dfs.ha.namenodes.hadoop</name>
<value>nn1,nn2</value>
<!--集群中一共有两个namenode -->
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn1</name>
<value>node1:9000</value>
<!--nn1的rpc通信地址 -->
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn1</name>
<value>node1:50070</value>
<!--nn1的http通信地址 -->
</property>
<property>
<name>dfs.namenode.rpc-address.hadoop.nn2</name>
<value>node2:9000</value>
<!--nn2的rpc通信地址 -->
</property>
<property>
<name>dfs.namenode.http-address.hadoop.nn2</name>
<value>node2:50070</value>
<!--nn2的http通信地址 -->
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node6:8485;node7:8485;node8:8485/hadoop</value>
<!-- 指定NameNode的元数据在JournalNode日志上的存放位置(一般和zookeeper部署在一起)-->
<!-- 存储路径可以随便起,如果有多个集群,不一样就行-->
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
<!--是否开启故障自动隔离-->
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/data/journalnode</value>
<!-- 指定JournalNode在本地磁盘存放数据的位置,这个需要指定,默认是放在tmp目录下 -->
</property>
<property>
<name>dfs.client.failover.proxy.provider.hadoop</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
<!-- namenode故障转移实现的代理类,注意"name键"要改动-->
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<!--故障自动转移的方法,这里选用ssh远程登陆方法-->
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
<!--选用了ssh远程登陆就需要ssh密钥,两台namenode需要互相做密钥认证-->
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
<!--配置ssh超时时间-->
</property>
</configuration>
7.在journalnode节点创建/usr/data/journalnode目录
8.修改mapred-site.xml( 修改mapred-site.xml.template名称为mapred-site.xml)
[root@node1 ~]# vim /usr/hadoop/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>node3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>node3:19888</value>
</property>
</configuration>
9.修改yarn-site.xml
[root@node1 ~]# vim /usr/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<!--是否开启rm的高可用-->
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>rmcluster</value>
<!--生成rm集群的唯一标识,name键不需要改动 -->
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<!--rm集群的两台机器名称 -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node4</value>
<!--rm1的机器地址 -->
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node4:8088</value>
<!--rm1的网页访问地址 -->
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node5</value>
<!--rm2的机器地址 -->
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node5:8088</value>
<!--rm2的网页访问地址 -->
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node6:2181,node7:2181,node8:2181</value>
<!--指定zookeeper集群的地址-->
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<!--启用自动恢复,默认是false-->
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里-->
</property>
</configuration>
10.编辑datanode配置文件(也是nodemanager的启动位置)
[root@node1 ~]# vim /usr/hadoop/etc/hadoop/slaves
node6
node7
node8
仅首次初始化时需要的步骤如下:
1.首先启动三台journalnode集群
[root@node6 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-journalnode-node6.out
[root@node6 ~]# jps
2965 Jps
2904 JournalNode
2779 QuorumPeerMain [root@node7 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-journalnode-node7.out
[root@node7 ~]# jps
2119 QuorumPeerMain
2220 JournalNode
2318 Jps [root@node8 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-journalnode-node8.out
[root@node8 ~]# jps
2229 Jps
2025 QuorumPeerMain
2153 JournalNode
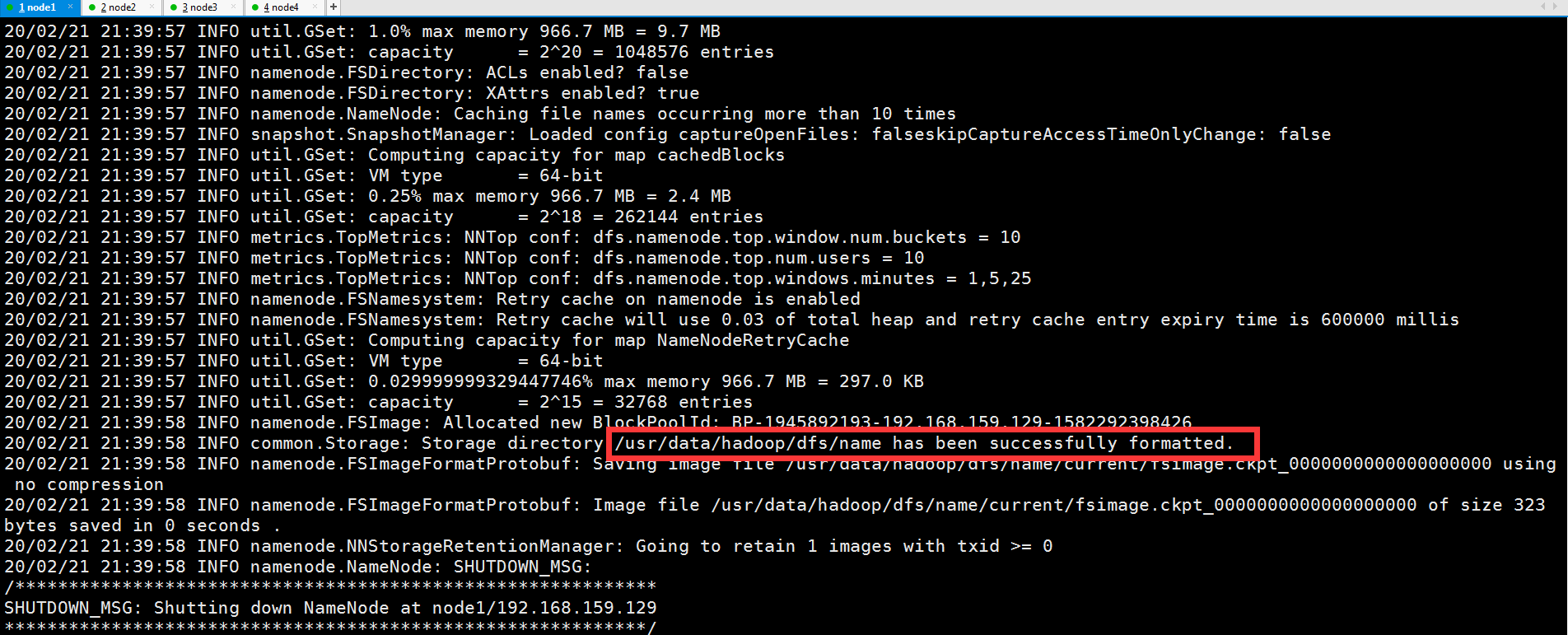
2.格式化NameNode主节点
[root@node1 ~]# hadoop namenode -format
3.启动NameNode主节点
[root@node1 ~]# hadoop-daemon.sh start namenode
starting namenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-namenode-node1.out
[root@node1 ~]# jps
7302 Jps
7225 NameNode
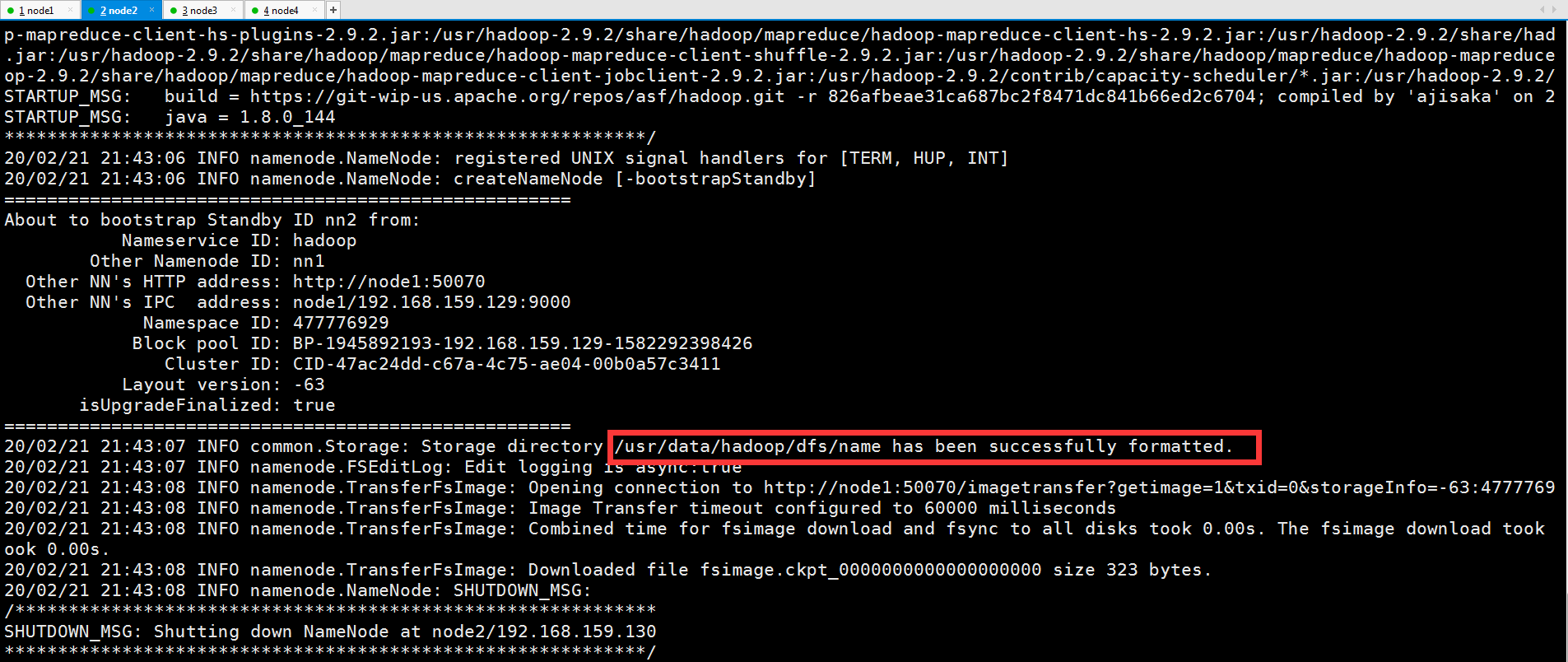
4.格式化NameNode从节点
[root@node2 ~]# hadoop namenode -bootstrapStandby
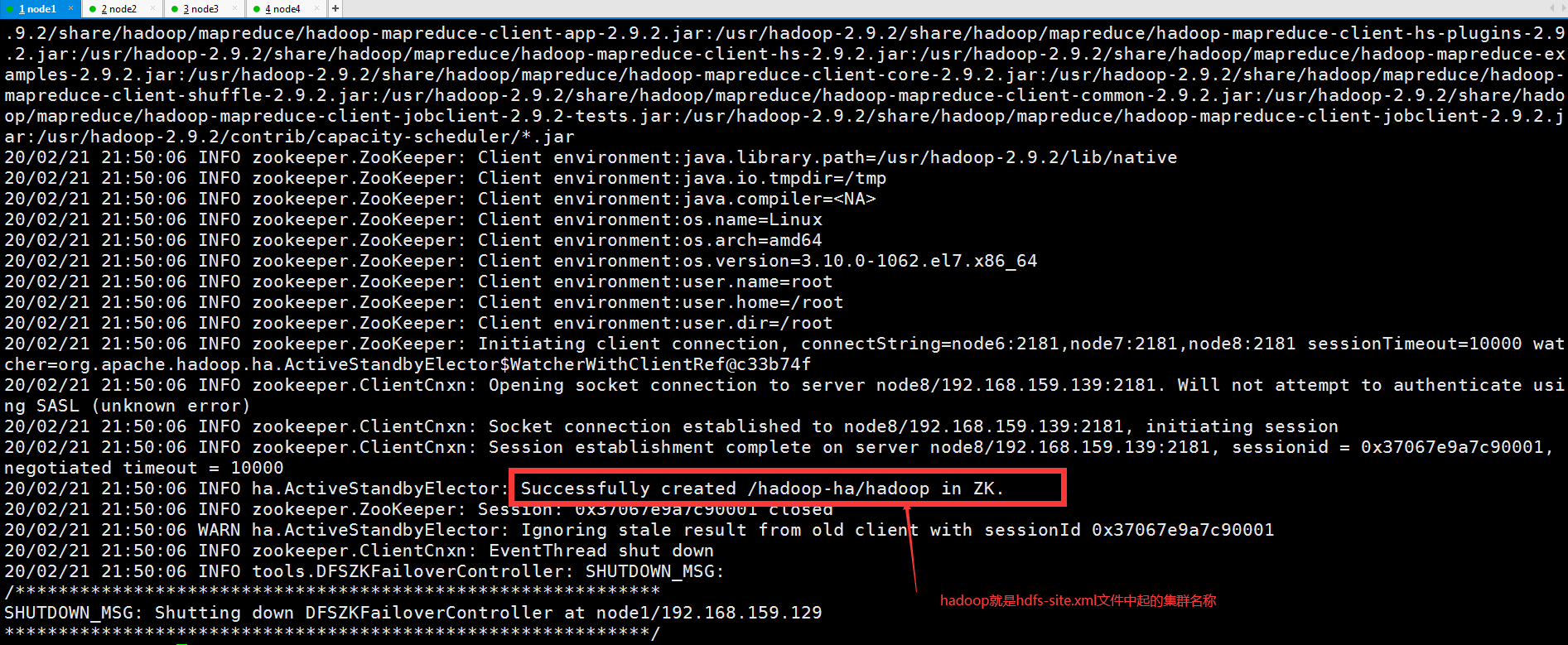
5.NameNode主节点向zookeeper提交初始化节点信息
[root@node1 ~]# hdfs zkfc -formatZK
5.1可以在zookeeper节点上使用zkCli.sh命令查看hdfs信息
[root@node6 ~]# /usr/zookeeper-3.4.6/bin/zkCli.sh
Connecting to localhost:2181
......
......
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper] #namenode还没提交信息的时候
[zk: localhost:2181(CONNECTED) 1] ls /
[zookeeper, hadoop-ha] #执行了上面那个提交命令
[zk: localhost:2181(CONNECTED) 2] ls /hadoop-ha/hadoop
[]
6.启动HDFS集群
[root@node1 ~]# start-dfs.sh
Starting namenodes on [node1 node2]
node2: starting namenode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-namenode-node2.out
node1: namenode running as process 7225. Stop it first.
node8: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-node8.out
node6: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-node6.out
node7: starting datanode, logging to /usr/hadoop-2.9.2/logs/hadoop-root-datanode-node7.out
Starting journal nodes [node6 node7 node8]
node6: journalnode running as process 2904. Stop it first.
node7: journalnode running as process 2220. Stop it first.
node8: journalnode running as process 2153. Stop it first.
Starting ZK Failover Controllers on NN hosts [node1 node2]
node2: starting zkfc, logging to /usr/hadoop-2.9.2/logs/hadoop-root-zkfc-node2.out
node1: starting zkfc, logging to /usr/hadoop-2.9.2/logs/hadoop-root-zkfc-node1.out [root@node1 ~]# jps
7857 DFSZKFailoverController
7924 Jps
7225 NameNode [root@node2 ~]# jps
2788 Jps
2633 NameNode
2732 DFSZKFailoverController [root@node6 ~]# jps
3235 Jps
3125 DataNode
2904 JournalNode
2779 QuorumPeerMain [root@node7 ~]# jps
2119 QuorumPeerMain
2220 JournalNode
2572 Jps
2462 DataNode [root@node8 ~]# jps
2483 Jps
2373 DataNode
2025 QuorumPeerMain
2153 JournalNode
7.此时zookeeper上就会有namenode的信息了,只存储主节点信息
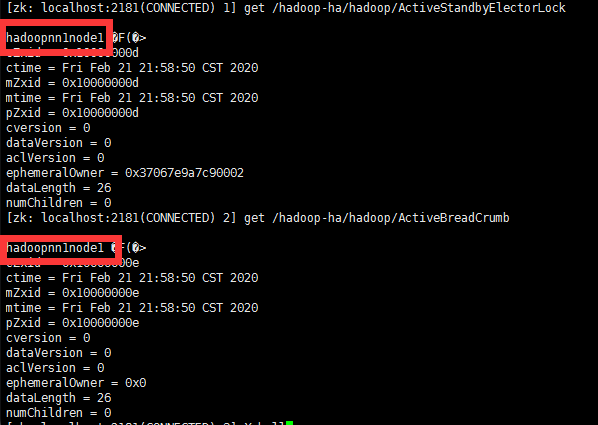
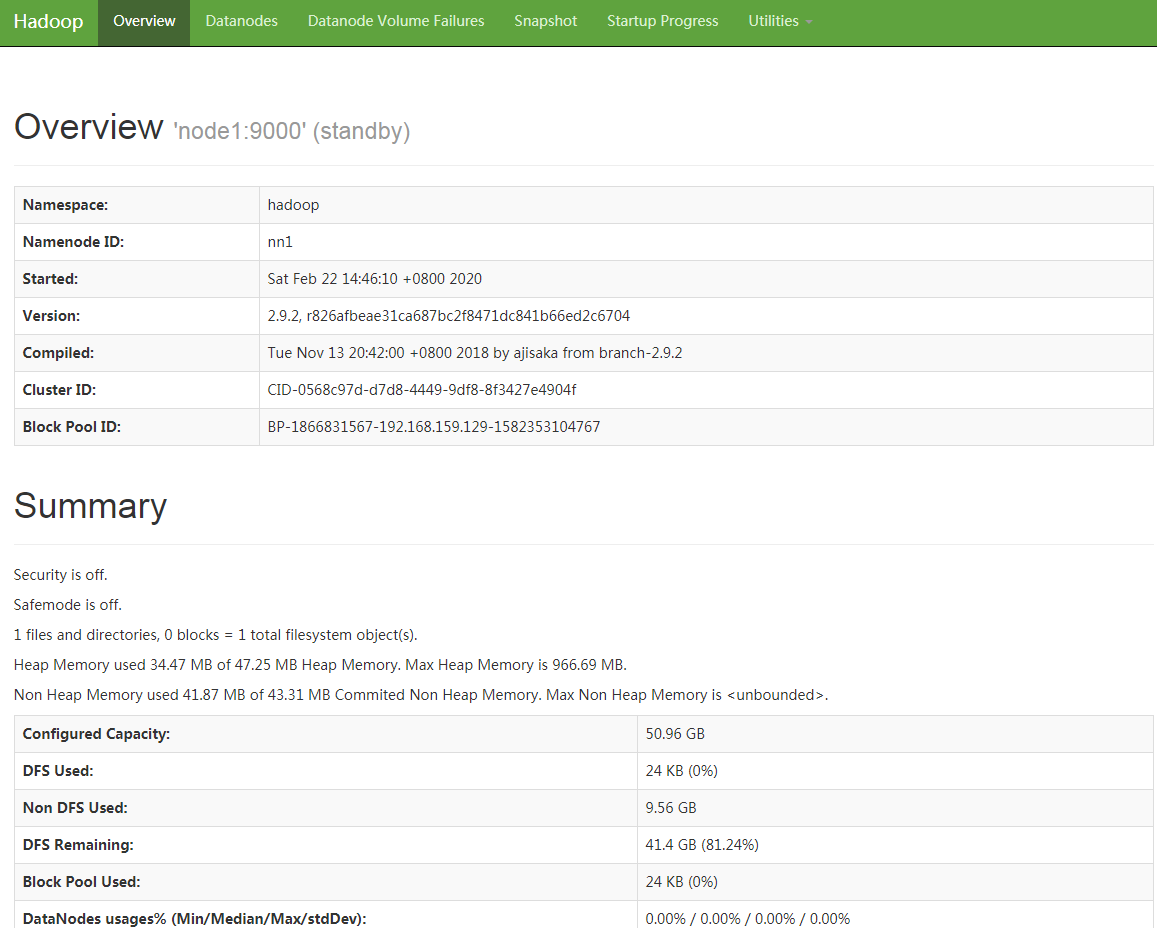
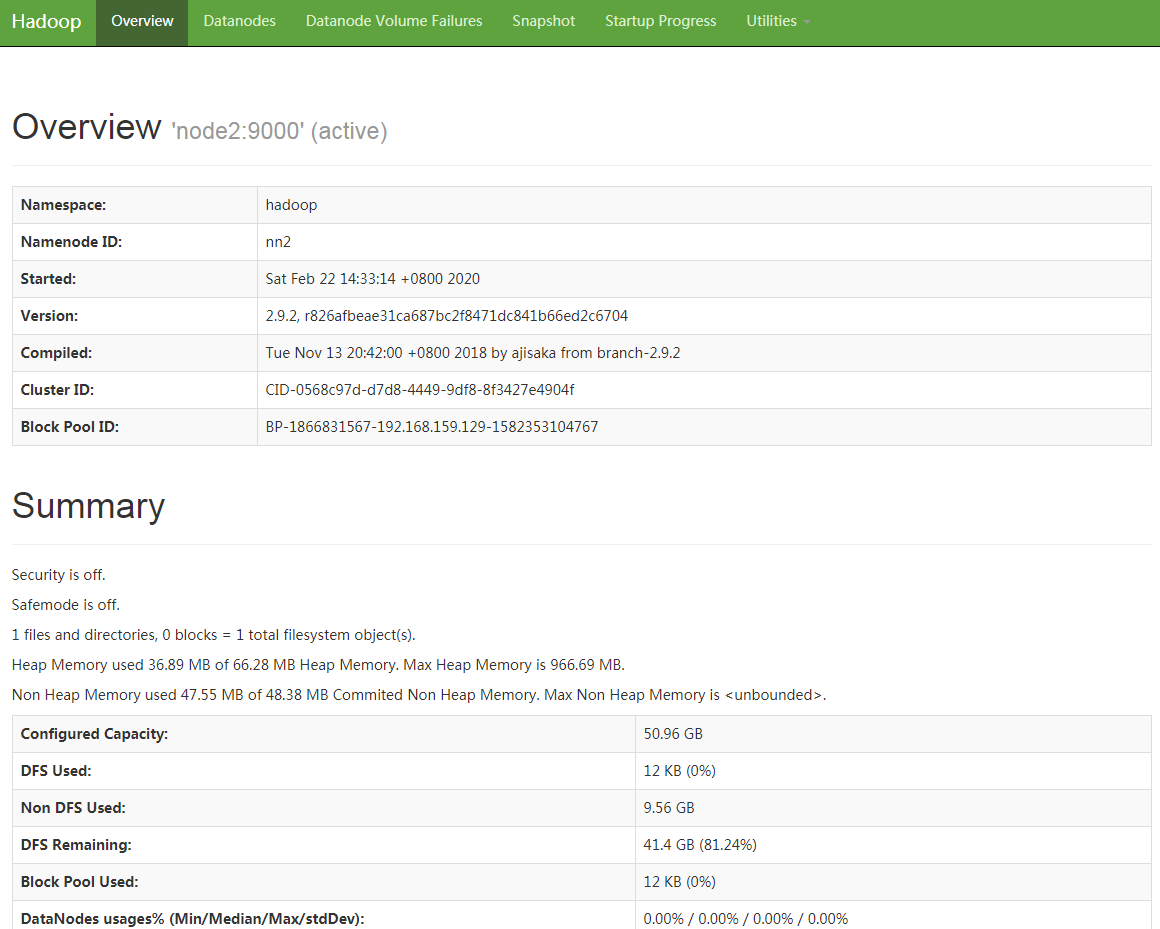
以上HDFS高可用集群初始化完成,下面启动yarn集群
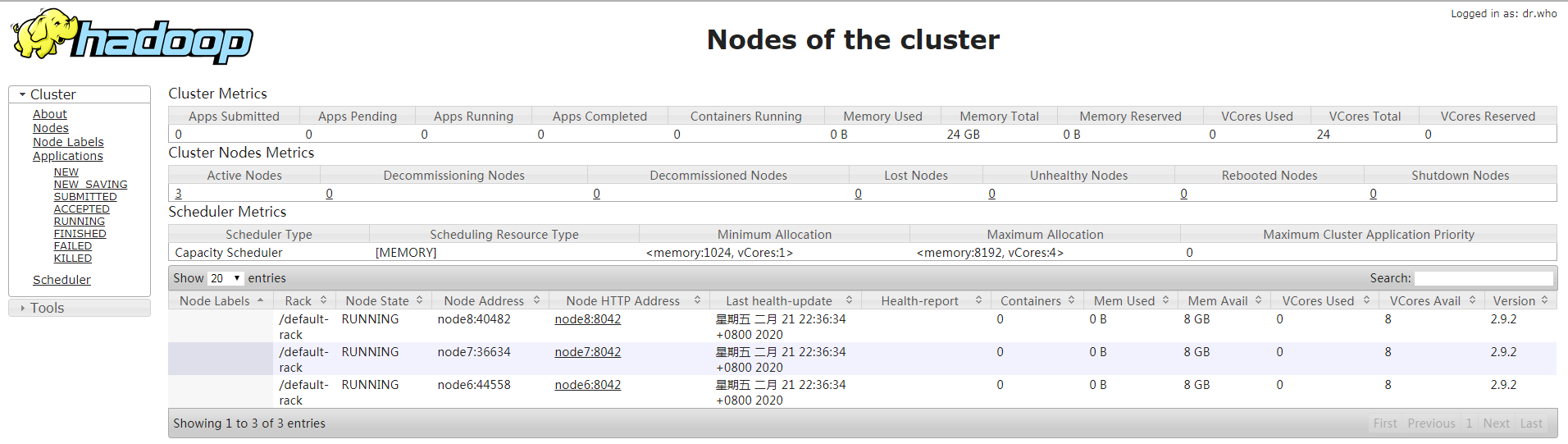
1.在namenode主节点上开启yarn集群,start-yarn.sh命令仅可以启动nodemanager,resourcemanager需要在对应节点上手动启动
[root@node1 ~]# start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-node1.out
node7: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-node7.out
node8: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-node8.out
node6: starting nodemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-nodemanager-node6.out [root@node6 ~]# jps
3125 DataNode
3397 NodeManager
3509 Jps
2904 JournalNode
2779 QuorumPeerMain [root@node7 ~]# jps
2736 NodeManager
2848 Jps
2119 QuorumPeerMain
2220 JournalNode
2462 DataNode [root@node8 ~]# jps
2373 DataNode
2646 NodeManager
2758 Jps
2025 QuorumPeerMain
2153 JournalNode
2.在resourcemanager节点手动启动rm
[root@node4 ~]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-node4.out
[root@node4 ~]# jps
2840 ResourceManager
3103 Jps [root@node5 ~]# yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /usr/hadoop-2.9.2/logs/yarn-root-resourcemanager-node5.out
[root@node5 ~]# jps
2994 Jps
2955 ResourceManager
start-dfs.sh
start-yarn.sh
在resourcemanager节点
yarn-daemon.sh start resourcemanager
Hadoop完全高可用集群安装的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- ActiveMQ 高可用集群安装、配置(ZooKeeper + LevelDB)
ActiveMQ 高可用集群安装.配置(ZooKeeper + LevelDB) 1.ActiveMQ 集群部署规划: 环境: JDK7 版本:ActiveMQ 5.11.1 ZooKeeper 集群 ...
- Neo4j 高可用集群安装
安装neo4j高可用集群,抓图安装过程 http://www.ibm.com/developerworks/cn/java/j-lo-neo4j/ Step1.下载neo4j商业版并解压,复制为neo ...
- Redis Cluster 4.0高可用集群安装、在线迁移操作记录
之前介绍了redis cluster的结构及高可用集群部署过程,今天这里简单说下redis集群的迁移.由于之前的redis cluster集群环境部署的服务器性能有限,需要迁移到高配置的服务器上.考虑 ...
- Zookeeper(四)Hadoop HA高可用集群搭建
一.高可就集群搭建 1.集群规划 2.集群服务器准备 (1) 修改主机名(2) 修改 IP 地址(3) 添加主机名和 IP 映射(4) 同步服务器时间(5) 关闭防火墙(6) 配置免密登录(7) 安装 ...
- Hadoop HA 高可用集群搭建
一.首先配置集群信息 vi /etc/hosts 二.安装zookeeper 1.解压至/usr/hadoop/下 .tar.gz -C /usr/hadoop/ 2.进入/usr/hadoop/zo ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
- 基于zookeeper(集群)+LevelDB的ActiveMq高可用集群安装、配置、测试
一. zookeeper安装(集群):http://www.cnblogs.com/wangfajun/p/8692117.html √ 二. ActiveMq配置: 1. ActiveMq集群部署 ...
随机推荐
- 利用django打造自己的工作流平台(一):从EXCEL到流程化运作
因工作所需以及管理个人一些日常事项,自己基于django(一个基于python的web框架,详细介绍可查阅相关资料)开发了一个简易的工作流平台[平台地址].本文首先简要介绍工作流平台的设计思想及其在项 ...
- 五、centos7安装mysql:安装mysqlser
一.下载通用安装二进制包 先下载mysql安装包:打开 http://dev.mysql.com/downloads/mysql/ 选择 linux - Generic并在其下选择 Linux - G ...
- 卸载sql server 2008
一. SQL2008卸载. 1.从控制面板卸载 1)点击计算机右下角“开始”,点击“控制面板” 2)点击“卸载程序”. 3)在程序列表中找到“Microsoft SQL Server 2008” ...
- 跨服务器的SQL语句如何书写
select * into 本地库名..表名 from OPENDATASOURCE( 'SQLOLEDB', 'Data ...
- BUAA软工第一次作业-热身
第一次作业-热身 项目 内容 这个作业属于哪个课程 2020春季计算机学院软件工程(罗杰 任健) (北京航空航天大学 - 计算机学院) 这个作业的要求在哪里 第一次作业-热身作业(阅读) 我在这个课程 ...
- Windows驱动开发-派遣函数
一个简单的派遣函数格式 NTSTATUS DispatchFunction(PDEVICE_OBJECT pDeviceObject, PIRP pIrp) { //业务代码区 //设置返回状态 pI ...
- js 实现循环遍历数组
for in循环遍历 let arr = [1, 2, 3, 4, 4, 3], str = '' for (const val in arr) { str += val + ' ' } consol ...
- 可以看一下我学习linux的过程
学习Linux的最佳方法是将它用于日常工作. 阅读Linux书籍,观看Linux视频不仅仅是足够的. 学习Linux没有捷径可走. 你不可能在一夜之间在Linux中掌握. 这需要时间和持久性. 刚刚潜 ...
- for 循环遍历数据,根据不同的条件判断动态渲染页面!
整体的逻辑为:for 循环遍历出数据,在for 循环里判断,根据不同的条件渲染 一.html页面结构 二.css就不再写了 三.JS逻辑代码 var listGroup='' ;k<data.i ...
- 「SCOI2009」windy数
传送门 Luogu 解题思路 数位 \(\text{DP}\) 设状态 \(dp[now][las][0/1][0/1]\) 表示当前 \(\text{DP}\) 到第 \(i\) 位,前一个数是 \ ...