PCA主成分分析(上)
之前看3DMM的论文的看到其用了PCA的方法,一开始以为自己对于PCA已经有了一定的理解,但是当看到式子的时候发现自己好像对于原理却又不甚明了,所以又回顾了以下PCA的原理,在此写一个总结。
PCA目的
主成分分析(principal component analysis, PCA) 是常用的一种降维方法,其目的是为了让数据合理的降维,在降低维度的同时尽量保证数据的原始信息不过于流失,同时减少数据的相关性。也可以理解为,对于正交属性空间中的样本点,如何用一个超平面对所有样本进行恰当的表达。
基于以上的目的可以大致分为两种
- 最大可分性: 样本点在这个超平面上的投影尽可能的分开(即投影后的方差最大)
- 最近重构性: 样本点到这个超平面的距离都足够近
最大可分性(最大投影方差)
我们的目的是为了让投影后的信息量的尽量保持原样,那么为什么方差越大信息量就越多?
我们知道信息量可以通过信息熵来描述,信息熵的定义为:变量的概率分布和每个变量的信息量构成了一个随机变量,这个随机变量的期望就是这个分布产生的信息量的熵
\]
其描述了样本的不确定度。举个例子,如果一个文档中字母全是 a,那么 \(p(a) = 1\),其信息量为 \(logp(a) = 0\) 可以知道这个文档的信息量完全不混乱,换言之字母a所承载的信息量为0,也可以理解为字母a对于这个系统毫无意义,所以采取 \(logp(a) = 0\) 来表示。同时也可以看到其方差也为0。
那是不是所有的方差都和熵表达的是一样的事呢?
再看看方差的定义:一个随机变量的方差描述的是它的离散程度,也就是该变量离其期望值的距离。
\]
通过以上的两个定义可以看出,方差描述的是与均值(期望)的离散程度, 而信息熵描述的是 不确定程度 ,仅仅与随机变量的分布有关,与其的具体取值无关。
在某些情况下,当方差越大,信息熵不一定越大。如下图
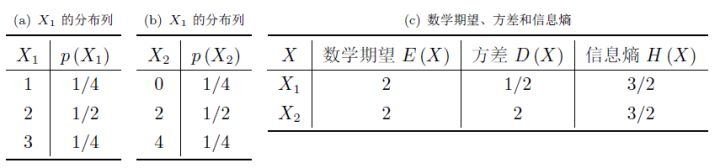
再回到PCA的目的,是为了保持降维后信息量的最大化。但由于我们当处理一个具体的事件时,并无法准确得到数据是以什么概率分布产生的,这样计算信息熵也就没有什么意义。而对于某些分布,如下

可以看出,在大部分情况下,方差越大信息熵也越大,即用方差去描述不确定性和信息熵描述不确定性在这些分布的情况下等价。
当然也有不等价的情况,只是在这种情况下,考虑方差就不一定成立.
以上是一种考虑方式,另一种直接通过投影如下图
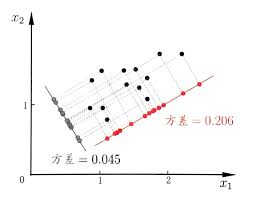
图片来源于西瓜书
可以看到,可以将二维向量投影到红线或者灰线,当然还有很多可以选择的投影方向,那么问题在于哪一个投影方向是最好的呢?对于红线而言投影后样本点更分散,所以其包含的信息量更大。
所以,根据以上信息我们需要找到的是进行降维后,对于不同样本在同一纬度的值差异大的纬度
投影
假设有m个n维数据 \(X(x^{(1)}, x^{(2)},...,x^{(m)})( n \times m)\) (后面均用这个例子),该数据需要先经历中心化,然后经过投影变换后得到了新的坐标系为 \(\{w_1,w_2,...,w_n\}\),其中 \(w\) 是标准正交基, 即 \(||w||_2=1, w_i^Tw_j=0\)。
这里可以想象成对于任意一个样本点 \(x_i\) 投影到任意新坐标轴 \(w_j\) 上的所表达的坐标为 \(z_j = w_j^Tx_i\), 所以这里 \(z_j\) 就表示了低纬坐标系里第 \(j\) 纬的坐标。
即对于任意一个样本 \(x^{(i)}\) 在新坐标系中的投影为 \(W^Tx^{(i)}\)
优化目标
所以对于基于最大方差投影的PCA算法的优化目标是:
- 降维后投影在各个方向的方差和最大
- 不同纬度之间的相关性为0
根据优化目标如何得到降维后的数据呢?
这里先给出步骤:
将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
求出协方差矩阵 \(C=\frac{1}{m}XX^\mathsf{T}\)
求出协方差矩阵的特征值及对应的特征向量
取最大的 \(n'\) 个特征值所对应的所对应的特征向量,组成的矩阵 \(W\) 即是投影矩阵
\(Z=W^TX\)即为降维到 \(n'\) 维后的数据集
关键点
- 为什么要将X的每一行进行0均值化(即每一个属性字段0均值化)
- 为什么要求去协方差矩阵
首先我们知道同一特征的协方差表示该元素的方差,不同特征之间的协方差表示他们的相关性,如下, 假设针对特征 \((f_1,f_2,...,f_n)\) 有协方差矩阵为
\]
其中, 对于特征 \((X,Y)\)
Cov\left( X,Y \right)&=E\left[ \left( X-E\left( X \right) \right)\left( Y-E\left( Y \right) \right) \right] \\ &=\frac{1}{n-1}\sum_{i=1}^{n}{(x_{i}-\bar{x})(y_{i}-\bar{y})}
\end{aligned}
\]
所以根据我们的求取的目标(同一纬度方差最大化,不同纬度相关性为0)可以用以下的协方差矩阵来表示
\]
这里引入矩阵的迹
数学定义: 在线性代数中,一个n×n矩阵A的主对角线(从左上方至右下方的对角线)上各个元素的总和被称为矩阵A的迹(或迹数),一般记作tr(A)。
假设将数据从 \(n\) 维降到 \(n'\) 维, 所以要优化的目标之一便是令 \(Cov(f_1,f_2, ..., f_{n'})\) 矩阵对角线元素之和最大,即 \(max(\delta_{11}, \delta_{22}, ... ,\delta_{n'n'})\)
推导
设有m个n维数据\(X (x^{(1)}, x^{(2)},...,x^{(m)})(n \times m)\) , 首先将数据X的每一维进行中心化, 原因在于求协方差矩阵的时候需要用到 \((x_i - \bar x)(y_i - \bar y)\) 所以原始数据变成
\begin{bmatrix}
x_{11} - u_1 & x_{12} - u_1 & ... & x_{1m} - u_1 \\
x_{21} - u_2 & x_{22} - u_2 & ... & x_{2m} - u_2 \\
... & ... & ... & ... \\
x_{n1} - u_n & x_{n2} - u_n & ... & x_{nm} - u_n
\end{bmatrix}\]
\(W \{w_1,w_2,...,w_n\}\) 为 \((n \times n)\) 的标准正交基矩阵(投影矩阵), \(Y = W^TX\) 为投影后的样本矩阵(新坐标系中任何一个样本的投影方差为 \(x^{(i)T}WW^Tx^{(i)}\))
则 \(Y\) 的协方差矩阵(根据维度数来考虑)为
C_Y &= \frac{1}{m} YY^T \\
&= \frac{1}{m} W^TXX^TW \\
&= W^T (\frac{1}{m} XX^T) W
\end{aligned}
\]
设 \(C = \frac{1}{m} XX^T\) 可得
\]
而优化的目标为
\underbrace{arg\;max}_{W}\;tr( W^TCW ) \\
W^TW=I
\end{matrix}\right. \tag1
\]
由于 \(C\) 已知,目的是为了求取极值, 利用拉格朗日函数(设给定函数 \(z=ƒ(x,y)\) 在满足 \(φ(x,y)=0\)下的条件极值,可以转化为函数 \(F(x,y,\lambda) = f(x,y) + \lambda φ(x,y)\) 的无条件极值问题)
所以上式(1) 就转化为
\]
等式两遍对W求导
\]
令导数为0,即 \(\frac{\partial f}{\partial W} = 0\), 且有性质 \(\frac{\partial tr(AB)}{\partial A} = B^T\), \(\frac{\partial tr(AB)}{\partial B} =A^T\),\(\frac{\partial X^TX}{\partial X} = X\) 可得
\]
由上式可以看出, \(W\) 是 \(XX^T\) 的特征向量组成的矩阵, 而 \(-\lambda\) 是 \(XX^T\) 的若干个特征值组成的矩阵,特征值在主对角线上,其余位置为0。 当将数据从 \(n\) 维降到 \(n'\) 维时, 需要找到最大的 \(n'\) 个特征值对应的特征向量, 这 \(n'\) 个特征向量组成的矩阵 \(W\) 即维我们需要的新坐标系矩阵,对于原始的数据集, 只需要利用 \(W^TX\), 就可以把原始数据集降维到最小投影距离的 \(n'\) 维数据集。
ps: 这里有一个性质 实对称矩阵不同特征值对应的特征向量互相正交, 在这里我们的 \(C_Y\) 是一个协方差矩阵,而协方差矩阵是一个实对称矩阵
为什么要找最大特征值对应的特征向量呢?
假设有样本点如下(已经做过预处理,均值为0),以及可投影的维度
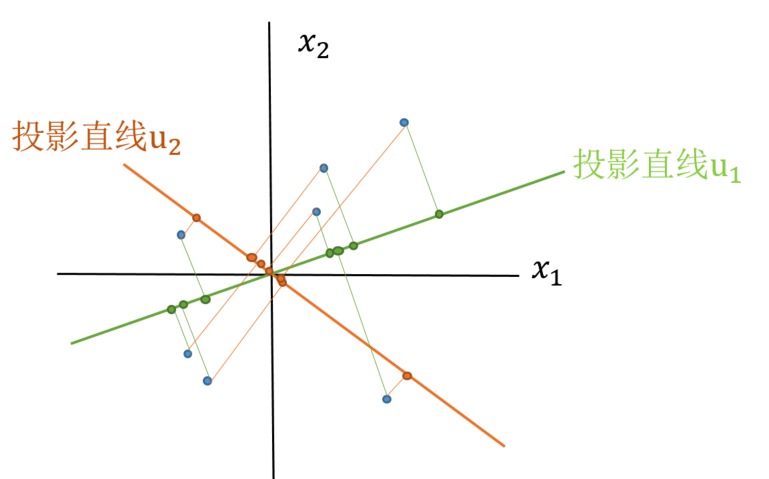
我们知道向量点乘的意义是,一个向量对于某一个单位向量的投影(向量对这个单位向量的线性变换),即 \(\vec{A} \cdot \vec{B}\) 的意义是向量A在向量B上的投影长度乘以向量B的模长(对如果B是一个平面也适用,即B为新的平面的基向量)。
所以对于任意维度的投影直线 \(u\)(列向量) 其投影后的样本方差为:
\]
由于已经在一开始就进行了 \(X\) 的零均值处理,以及向量加法的分配律可以得知 \(所有{{x^{i}}^Tu}的均值 = 0\)
所以最终方差为
\]
对上式进行变换 (根据向量的交换律\(a \cdot b = b \cdot a\))
\]
由上式可以发现,括号内的部分就是样本特征的协方差矩阵, 现在我们已经得到这个方差的表达方式,那么如何使得这个方差最大呢?令方差 \(\frac{1}{m} \sum_{i=1}^{m}({x^{i}}^Tu )^2 = \lambda, C = \frac{1}{m}\sum_{i=1}^{m}{x^ix^{i}}^T\) ,于是上式就变成了
\]
因为 \(u^Tu = 1\) 同理, 为了使得方差最大,利用拉格朗日乘子法可以得知:
\]
将上式求导,是之为0, 得到:
\]
所以为了使得方差 \(\lambda\) 最大,也就是取协方差矩阵 \(C\) 的最大特征值,与其对应的特征向量,为了使选取的 \(n'\) 维空间各个维度方差之和最大,就是取最大的 \(n'\) 个特征值以及其对应的特征向量。 从这里也可以看出,由于 \(C\) 使协方差矩阵,也就是实对称矩阵, 所以其特征特征向量两两正交。
参考:
https://www.cnblogs.com/LeftNotEasy/archive/2011/01/08/lda-and-pca-machine-learning.html
https://www.cnblogs.com/pinard/p/6239403.html#!comments
https://www.cnblogs.com/jerrylead/archive/2011/04/18/2020209.html
PCA主成分分析(上)的更多相关文章
- 用PCA(主成分分析法)进行信号滤波
用PCA(主成分分析法)进行信号滤波 此文章从我之前的C博客上导入,代码什么的可以参考matlab官方帮助文档 现在网上大多是通过PCA对数据进行降维,其实PCA还有一个用处就是可以进行信号滤波.网上 ...
- 机器学习之PCA主成分分析
前言 以下内容是个人学习之后的感悟,转载请注明出处~ 简介 在用统计分析方法研究多变量的课题时,变量个数太多就会增加课题的复杂性.人们自然希望变量个数较少而得到的 信息较多.在很 ...
- PCA主成分分析Python实现
作者:拾毅者 出处:http://blog.csdn.net/Dream_angel_Z/article/details/50760130 Github源代码:https://github.com/c ...
- 机器学习 - 算法 - PCA 主成分分析
PCA 主成分分析 原理概述 用途 - 降维中最常用的手段 目标 - 提取最有价值的信息( 基于方差 ) 问题 - 降维后的数据的意义 ? 所需数学基础概念 向量的表示 基变换 协方差矩阵 协方差 优 ...
- PCA(主成分分析)方法浅析
PCA(主成分分析)方法浅析 降维.数据压缩 找到数据中最重要的方向:方差最大的方向,也就是样本间差距最显著的方向 在与第一个正交的超平面上找最合适的第二个方向 PCA算法流程 上图第一步描述不正确, ...
- PCA 主成分分析
链接1 链接2(原文地址) PCA的数学原理(转) PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表 ...
- PCA主成分分析方法
PCA: Principal Components Analysis,主成分分析. 1.引入 在对任何训练集进行分类和回归处理之前,我们首先都需要提取原始数据的特征,然后将提取出的特征数据输入到相应的 ...
- 【建模应用】PCA主成分分析原理详解
原文载于此:http://blog.csdn.net/zhongkelee/article/details/44064401 一.PCA简介 1. 相关背景 上完陈恩红老师的<机器学习与知识发现 ...
- PCA主成分分析+白化
参考链接:http://deeplearning.stanford.edu/wiki/index.php/%E4%B8%BB%E6%88%90%E5%88%86%E5%88%86%E6%9E%90 h ...
随机推荐
- PHP常用设计模式,PHP常用设计模式详解,PHP详解设计模式,PHP设计模式
PHP常用设计模式详解 单例模式: php交流群:159789818 特性:单例类只能有一个实例 类内__construct构造函数私有化,防止new实例 类内__clone私有化,防止复制对象 设置 ...
- HDU1398:Square Coins(DP水题)
Square Coins Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tota ...
- 微信小程序--分享功能
微信小程序--分享功能 微信小程序前段时间开放了小程序右上角的分享功能, 可以分享任意一个页面到好友或者群聊, 但是不能分享到朋友圈 这里有微信开发文档链接:点击跳转到微信分享功能API 入口方法: ...
- 微信小程序 使用include导入wxml文件注意的问题
(1)使用inlucde的时,要注意将最后的终止符 / 添加上去,否则不能正常的导入界面内容 <include src="header.wxml"/> (2)引入文件注 ...
- json格式的文件操作2
1.字典转换为字符串(json.dumps) jsongeshi={"name":"yajuan","age":"10" ...
- System.out.println()的真实含义
每一个人的Java学习之路上恐怕都是用以下代码开始的吧? public class Test { public static void main(String[] args) { System.out ...
- python3(三十五)file read write
""" 文件读写 """ __author__on__ = 'shaozhiqi 2019/9/23' # !/usr/bin/env py ...
- Java的多线程编程模型5--从AtomicInteger开始
Java的多线程编程模型5--从AtomicInteger开始 2011-06-23 20:50 11393人阅读 评论(9) 收藏 举报 java多线程编程jniinteger测试 AtomicIn ...
- 【小学数学】算术口诀 独立音频MP3
算术口诀 独立音频MP3 原文载于本人个人网站:http://www.unlimitedbladeworks.cc/writing_202004_01_sskj 特点 加法口诀 乘法口诀 独立音频 m ...
- Thinking in Java,Fourth Edition(Java 编程思想,第四版)学习笔记(二)之Introduction to Objects
The genesis of the computer revolution was a machine. The genesis of out programming languages thus ...